【Python3 爬虫】02_利用urllib.urlopen向百度翻译发送数据并返回结果
上一节进行了网页的简单抓取,接下来我们详细的了解一下两个重要的参数url与data
urlopen详解
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None
URL参数
Open the URL url, which can be either a string or a Request object.
大概意思:URL参数不仅可以是一个字符串也可以是一个对象
data参数
data may be a bytes object specifying additional data to send to the server, or None if no such data is needed. data may also be an iterable object and in that case Content-Length value must be specified in the headers. Currently HTTP requests are the only ones that use data; the HTTP request will be a POST instead of a GET when the data parameter is provided. data should be a buffer in the standard application/x-www-form-urlencoded format. The urllib.parse.urlencode() function takes a mapping or sequence of 2-tuples and returns a string in this format. urllib.request module uses HTTP/1.1 and includes Connection:close header in its HTTP requests.
大概意思:如果没有设置urlopen()函数的data参数,HTTP请求采用GET方式,也就是我们从服务器获取信息,如果我们设置data参数,HTTP请求采用POST方式,也就是我们向服务器传递数据。data参数有自己的格式,它是一个基于application/x-www.form-urlencoded的格式, 因为我们可以使用urllib.parse.urlencode()函数将字符串自动转换成上面所说的格式。
对象作为urlopen参数
urlopen返回的对象不仅可以使用read()进行读取,同时也可以使用geturl(),info(),getcode()方法
geturl()返回的是一个url的字符串;
info()返回的是一些meta标记的元信息,包括一些服务器的信息;
getcode()返回的是HTTP的状态码,如果返回200表示请求成功。
# -*- coding:UTF-8 -*- from urllib import request if __name__ == '__main__':
req = request.Request("http://cn.bing.com/translator?ref=MSTToolbar")
response = request.urlopen(req)
#geturl
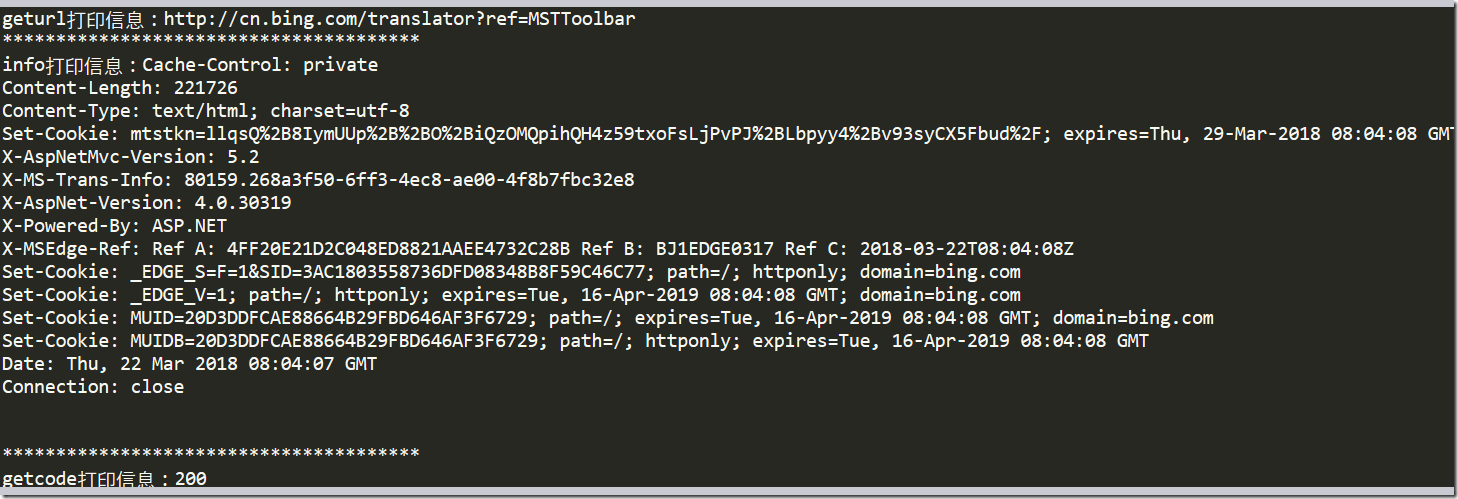
print("geturl打印信息:%s"%(response.geturl()))
print('***************************************')
#info
print("info打印信息:%s"%(response.info()))
print('***************************************') #getcode
print("getcode打印信息:%s"%(response.getcode()))
打印结果:
发送data示例
下面是一个向百度翻译传输数据并返回结果的例子:
# -*- coding:UTF-8 -*- from urllib import request,parse
import json
if __name__ == '__main__':
#对应上图的url
Request_URL = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=https://www.baidu.com/link' #创建字典
Form_Data = {}
Form_Data[type] = 'AUTO'
Form_Data['i'] = 'My name is Alice'
Form_Data['doctype'] = 'json'
Form_Data['xmlVersion'] = '1.8'
Form_Data['keyform'] = 'fanyi.web'
Form_Data['ue'] = 'ue:utf-8'
Form_Data['action'] = 'FY_BY_CLICKBUTTON' #使用urlcode转换后的标准格式
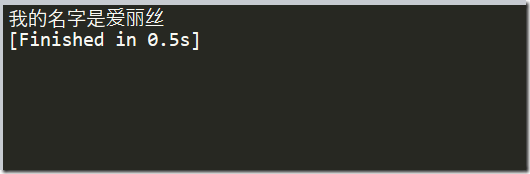
data = parse.urlencode(Form_Data).encode("utf-8") response = request.urlopen(Request_URL,data) html = response.read().decode("utf-8") translate_results = json.loads(html) translate_results = translate_results['translateResult'][0][0]['tgt'] print(translate_results)
执行结果如下:
【Python3 爬虫】02_利用urllib.urlopen向百度翻译发送数据并返回结果的更多相关文章
- python3爬虫:利用urllib与有道翻译获得翻译结果
在实现这一功能时遇到了一些困难,由于按照<零基础入门python>中的代码无法实现翻译,会爆出“您的请求来源非法,商业用途使用请关注有道翻译API官方网站“有道智云”: http://ai ...
- Python3爬虫:利用Fidder抓取手机APP的数据
1.什么是Fiddler? Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的“进出”Fiddler的数据(指cookie,ht ...
- Python3爬虫(2)_利用urllib.urlopen发送数据获得反馈信息
一.urlopen的url参数 Agent url不仅可以是一个字符串,例如:https://baike.baidu.com/.url也可以是一个Request对象,这就需要我们先定义一个Reques ...
- (未完成...)Python3网络爬虫(2):利用urllib.urlopen向有道翻译发送数据并获得翻译结果
环境: 火狐浏览器 pycharm2017.3.3 python3.5 1.url不仅可以是一个字符串,例如:http://www.baidu.com.url也可以是一个Request对象,这就需要我 ...
- 利用urllib.urlopen向有道翻译发送数据获得翻译结果
from urllib import request,parseimport requests, sys,ssl,json ssl._create_default_https_context = ss ...
- Python爬虫之简单的爬取百度贴吧数据
首先要使用的第类库有 urllib下的request 以及urllib下的parse 以及 time包 random包 之后我们定义一个名叫BaiduSpider类用来爬取信息 属性有 url: ...
- Python开发简单爬虫(二)---爬取百度百科页面数据
一.开发爬虫的步骤 1.确定目标抓取策略: 打开目标页面,通过右键审查元素确定网页的url格式.数据格式.和网页编码形式. ①先看url的格式, F12观察一下链接的形式;② 再看目标文本信息的标签格 ...
- Python爬虫爬取百度翻译之数据提取方法json
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统 说明:本例为实现输入中文翻译为英文的小程序,适合Python爬虫的初学者一起学习,感兴趣的可以做英文翻译为中文的 ...
- [C#参考]利用Socket连续发送数据
这个例子只是一个简单的连续发送数据,接收数据的DEMO.因为最近做一个项目,要求robot连续的通过Socket传回自己的当前的位置坐标,然后客户端接收到坐标信息,在本地绘制地图,实时显示robot的 ...
随机推荐
- log4j 输入不同日志文件
log4j的强大功能无可置疑,但实际应用中免不了遇到某个功能需要输出独立的日志文件的情况,怎样才能把所需的内容从原有日志中分离,形成单独的日志文件呢?其实只要在现有的log4j基础上稍加配置即可轻松实 ...
- ionic3 cordova ionic-native插件
ionic-native插件 cordova安装插件 以及 ionic-native插件使用过程以及步骤 cordova plugin add cordova-plugin-插件名称. //安装插件 ...
- SVN的配置和使用
1.安装前必备 获取 Subversion 服务器程序 到官方网站 http://subversion.tigris.org/ 我下的是CollabNetSubversion-server-1. ...
- [libgdx游戏开发教程]使用Libgdx进行游戏开发(7)-屏幕布局的最佳实践
管理多个屏幕 我们的菜单屏有2个按钮,一个play一个option.option里就是一些开关的设置,比如音乐音效等.这些设置将会保存到Preferences中. 多屏幕切换是游戏的基本机制,Libg ...
- 零基础如何学习 Web 安全?(转)
在网上看了一篇文章<零基础如何学习 Web 安全?>,虽然很多东西的都不是很懂,感觉挺好的copy过来,慢慢消化: 文章地址:https://www.zhihu.com/question/ ...
- Linux命令之ps
ps [选项] 报告当前进程状态.ps显示有关选择的活动进程的信息.如果要重复更新选择和显示的信息,请使用top.ps命令可以搭配kill随时中断.删除不必要的程序.ps命令是最基本同时也是非常强大的 ...
- java应用高cpu占用
一个应用占用CPU很高,除了确实是计算密集型应用之外,通常原因都是出现了死循环 排查故障如下: 1.根据top命令,发现PID为28555的Java进程占用CPU高达200%,出现故障 2.通过ps ...
- DeprecationWarning: current URL string parser is deprecated解决方法
我最近在使用mongoDB的时候,发现了这个警告语句,纳闷了,按照官方文档的教程去连接数据库还能出错,也是醉了. 后来尝试去阅读相关资料,发现只是需要将{ useNewUrlParser: true ...
- intellij idea 为JavaEE项目建立Servlet
建立Servlet的方法 顶部菜单栏 View > Tool Windows > Web. 然后互相web窗口 右键Web>new>Servlet 弹出窗口
- POJ 3709 K-Anonymous Sequence(斜率优化DP)
[题目链接] http://poj.org/problem?id=3709 [题目大意] 给出一个长度为n个非严格单调递增数列,每次操作可以使得其中任意一项减一, 问现在使得数列中每项数相同的数的数量 ...