JAVA使用Gecco爬虫 抓取网页内容(附Demo)
JAVA 爬虫工具有挺多的,但是Gecco是一个挺轻量方便的工具。
先上项目结构图。
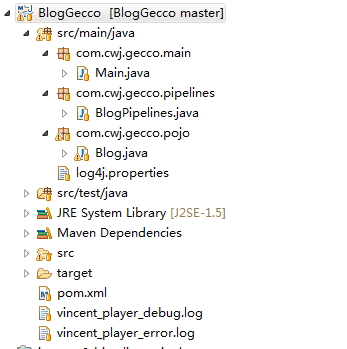
这是一个 JAVASE的 MAVEN 项目,要添加包依赖,其他就四个文件。log4j.properties 加上三个java类。
1、先配置log4j.properties
log4j.rootLogger=INFO,Console,File
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.Target=System.out
log4j.appender.Console.layout = org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=[%c] - %m%n log4j.appender.File = org.apache.log4j.RollingFileAppender
log4j.appender.File.File = logs/ssm.log
log4j.appender.File.MaxFileSize = 10MB
log4j.appender.File.Threshold = ALL
log4j.appender.File.layout = org.apache.log4j.PatternLayout
log4j.appender.File.layout.ConversionPattern =[%p] [%d{yyyy-MM-dd HH\:mm\:ss}][%c]%m%n
2、接下来着手写Blog.java,里面都有注释 不解释
package com.cwj.gecco.pojo; import com.geccocrawler.gecco.annotation.Gecco;
import com.geccocrawler.gecco.annotation.HtmlField;
import com.geccocrawler.gecco.annotation.Request;
import com.geccocrawler.gecco.request.HttpRequest;
import com.geccocrawler.gecco.spider.SpiderBean; /**
* @author cwj
* 2017年8月6日
* Blog实体类,运行主函数从这里开始解析
* matchUrl:要抓包的目标地址
* pipelines:跳转到下个pipelines
*/
@Gecco(matchUrl="http://www.cnblogs.com/boychen/p/7226831.html",pipelines="blogPipelines")
public class Blog implements SpiderBean{
/**
* 向指定URL发送GET方法的请求
*/
@Request
private HttpRequest request; /**
* 抓去这个路径下所有的内容
*/
@HtmlField(cssPath = "body div#cnblogs_post_body")
private String content; public HttpRequest getRequest() {
return request;
} public void setRequest(HttpRequest request) {
this.request = request;
} public String getContent() {
return content;
} public void setContent(String content) {
this.content = content;
} }
3、BlogPipelines.java
package com.cwj.gecco.pipelines; import com.cwj.gecco.pojo.Blog;
import com.geccocrawler.gecco.annotation.PipelineName;
import com.geccocrawler.gecco.pipeline.Pipeline; /**
* @author cwj
* 2017年8月6日
* 运行完Blog.java 根据@PipelineName 来这里
*/
@PipelineName(value="blogPipelines")
public class BlogPipelines implements Pipeline<Blog>{ /**
* 将抓取到的内容进行处理 这里是打印在控制台
*/
public void process(Blog blog) {
System.out.println(blog.getContent());
} }
4、最后便是在main中调用
package com.cwj.gecco.main;
import com.geccocrawler.gecco.GeccoEngine;
public class Main {
public static void main(String[] args) {
GeccoEngine.create()
//工程的包路径
.classpath("com.cwj.gecco")
//开始抓取的页面地址
.start("http://www.cnblogs.com/boychen/p/7226831.html")
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(5)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
5、抓取到内容,日志文件被我删除 有警告
附上源码地址 https://github.com/BeautifulMeet/Gecco
JAVA使用Gecco爬虫 抓取网页内容(附Demo)的更多相关文章
- Java豆瓣电影爬虫——抓取电影详情和电影短评数据
一直想做个这样的爬虫:定制自己的种子,爬取想要的数据,做点力所能及的小分析.正好,这段时间宝宝出生,一边陪宝宝和宝妈,一边把自己做的这个豆瓣电影爬虫的数据采集部分跑起来.现在做一个概要的介绍和演示. ...
- PHP爬虫抓取网页内容 (simple_html_dom.php)
使用simple_html_dom.php,下载|文档 因为抓取的只是一个网页,所以比较简单,整个网站的下次再研究,可能用Python来做爬虫会好些. <meta http-equiv=&quo ...
- paip.抓取网页内容--java php python
paip.抓取网页内容--java php python.txt 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog ...
- Java 实现 HttpClients+jsoup,Jsoup,htmlunit,Headless Chrome 爬虫抓取数据
最近整理一下手头上搞过的一些爬虫,有HttpClients+jsoup,Jsoup,htmlunit,HeadlessChrome 一,HttpClients+jsoup,这是第一代比较low,很快就 ...
- 爬虫学习一系列:urllib2抓取网页内容
爬虫学习一系列:urllib2抓取网页内容 所谓网页抓取,就是把URL地址中指定的网络资源从网络中读取出来,保存到本地.我们平时在浏览器中通过网址浏览网页,只不过我们看到的是解析过的页面效果,而通过程 ...
- 爬虫技术 -- 进阶学习(七)简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码...算是一份测试版的代码.大牛大神别喷... 通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配. List<string&g ...
- 爬虫技术(四)-- 简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码...算是一份测试版的代码.大牛大神别喷... 通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配. List<string&g ...
- 使用Jsoup函数包抓取网页内容
之前写过一篇用Java抓取网页内容的文章,当时是用url.openStream()函数创建一个流,然后用BufferedReader把这个inputstream读取进来.抓取的结果是一整个字符串.如果 ...
- c#抓取网页内容乱码的解决方案
写过爬虫的同学都知道,这是个很常见的问题了,一般处理思路是: 使用HttpWebRequest发送请求,HttpWebResponse来接收,判断HttpWebResponse中”Content-Ty ...
随机推荐
- Node开发文件上传系统及向七牛云存储和亚马逊AWS S3的文件上传
背景起,有奏乐: 有伟人曰:学习技能的最好途径莫过于理论与实践相结合. 初学Node这货时,每每读教程必会Fall asleep. 当真要开发系统时,顿觉精神百倍,即便踩坑无数也不失斗志. 因为同团队 ...
- openwrt,mjpeg流,wifi摄像头与APP联动,拍照、录像
最近公司好忙,自己主管的产品又忙着上线,好久都没更新博客了. 最近产品在做一款wifi摄像头,摄像头与手机同时连接在一个局域网内,即可实现摄像头图像在手机显示,并且拍照录像等功能 mjpeg是一张一张 ...
- SQL SERVER 2014--内存表实现秒杀场景
===================================== 网上针对“秒杀”的解决方案很多,数据拆分化解热点,READPAST解决锁问题,应用程序排队限制并发等等很多方式,各有优缺点, ...
- 服务端JSON内容中有富文本时
问题背景 由于数据中存在复杂的富文本,包含各种引号和特殊字符,导致后端和前端通过JSON格式进行数据交互引发前端JSON解析出错. 解决方案 后端将富文本内容 ConvertToBase64Strin ...
- VS开发Windows服务
转自:https://www.cnblogs.com/xujie/p/5695673.html
- efcore操作mysql,出现System.InvalidOperationException:“No coercion operator is defined between types 'System.Int16' and 'System.Boolean'.”
这个恶心的问题,只需要把EF的依赖换成 Pomelo.EntityFrameworkCore.MySql 库即可解决
- CSS精灵技术
在CSDN中浏览博客时,在博客的结束有上一篇和下一篇的按钮,当我们把鼠标放上去的时候,可以看到这两个按钮会进行颜色的改变,这种技术称为CSS精灵技术.通过查看源发现,其实他是通过超级链接的伪类实现的, ...
- Android - "已安装了存在签名冲突的同名数据包",解决方法!
错误提示:已安装了存在签名冲突的同名数据包. 解决方法:打开Android Studio,打开logcat,用usb线连接你出错的手机,识别出手机之后,在你的项目后面,点击“run”按钮,随后AS会提 ...
- jzoj5347
tj:80pts:維護f[i][j]表示當前第i個方塊必須選,且選了j個的最優解,設w[i]為第i個方塊長度 則可以枚舉上次選了第k個方塊,則f[i][j]=max{f[k][j-1]+w[i]*(i ...
- 听补天漏洞审核专家实战讲解XXE漏洞
对于将“挖洞”作为施展自身才干.展现自身价值方式的白 帽 子来说,听漏洞审核专家讲如何挖掘并验证漏洞,绝对不失为一种快速的成长方式! XXE Injection(XML External Entity ...