32、出任爬虫公司CEO(爬取职友网招聘信息)
D:\USERDATA\python>scrapy startproject zhiyou
New Scrapy project 'zhiyou', using template directory 'c:\users\www1707\appdata\local\programs\python\python37\lib\site-packages\scrapy\templates\project', created in:
D:\USERDATA\python\zhiyou You can start your first spider with:
cd zhiyou
scrapy genspider example example.com D:\USERDATA\python>cd zhiyou D:\USERDATA\python\zhiyou>
import scrapy
import bs4
import re
import requests
import math
from ..items import ZhiyouItem class ZhiyouItemSpider(scrapy.Spider):
name = 'zhiyou'
allowed_domains = ['www.jobui.com']
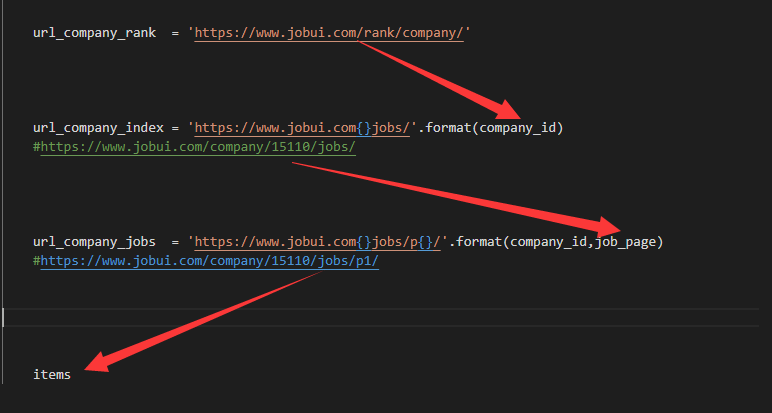
start_urls = ['https://www.jobui.com/rank/company/'] def parse(self,response):
bs = bs4.BeautifulSoup(response.text,'html.parser')
datas = bs.find_all('a',href=re.compile('^/company/'))
for data in datas:
company_id = data['href']
company_url = 'https://www.jobui.com{}jobs/'.format(company_id)
yield scrapy.Request(company_url,callback=self.parse_company) def parse_company(self,response):
bs = bs4.BeautifulSoup(response.text,'html.parser')
try:
jobs = int(bs.find('p',class_='m-desc').text.split(' ')[1])
job_page = math.ceil(jobs / 15) + 1
company_url = str(response).split(' ')[1].replace('>','')
# for i in range(1,job_page):
for i in range(1,2):
job_url = '{}p{}'.format(company_url,i)
yield scrapy.Request(job_url,callback=self.parse_job)
except:
pass def parse_job(self,response):
bs = bs4.BeautifulSoup(response.text,'html.parser')
datas = bs.find_all('div',class_='job-simple-content')
company_name = bs.find('h1',id='companyH1')['data-companyname']
for data in datas:
item = ZhiyouItem()
item['company'] = company_name
item['job'] = data.find('h3').text
item['city'] = data.find('span').text
item['desc'] = data.find_all('span')[1].text
yield item
BOT_NAME = 'zhiyou' SPIDER_MODULES = ['zhiyou.spiders']
NEWSPIDER_MODULE = 'zhiyou.spiders' USER_AGENT = 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' ROBOTSTXT_OBEY = False FEED_URI = './s.csv'
FEED_FORMAT='CSV'
FEED_EXPORT_ENCODING='utf-8-sig' DOWNLOAD_DELAY = 0.5 ITEM_PIPELINES = {
'zhiyou.pipelines.ZhiyouPipeline': 300,
}
import scrapy class ZhiyouItem(scrapy.Item):
company = scrapy.Field()
job = scrapy.Field()
city = scrapy.Field()
desc = scrapy.Field()
import openpyxl class ZhiyouPipeline(object):
#定义一个JobuiPipeline类,负责处理item
def __init__(self):
#初始化函数 当类实例化时这个方法会自启动
self.wb =openpyxl.Workbook()
#创建工作薄
self.ws = self.wb.active
#定位活动表
self.ws.append(['公司', '职位', '地址', '招聘信息'])
#用append函数往表格添加表头 def process_item(self, item, spider):
#process_item是默认的处理item的方法,就像parse是默认处理response的方法
line = [item['company'], item['job'], item['city'], item['desc']]
#把公司名称、职位名称、工作地点和招聘要求都写成列表的形式,赋值给line
self.ws.append(line)
#用append函数把公司名称、职位名称、工作地点和招聘要求的数据都添加进表格
return item
#将item丢回给引擎,如果后面还有这个item需要经过的itempipeline,引擎会自己调度 def close_spider(self, spider):
#close_spider是当爬虫结束运行时,这个方法就会执行
self.wb.save('./s.xlsx')
#保存文件
self.wb.close()
#关闭文件
#导入模块:
import scrapy
import bs4
from ..items import JobuiItem class JobuiSpider(scrapy.Spider):
name = 'jobs'
allowed_domains = ['www.jobui.com']
start_urls = ['https://www.jobui.com/rank/company/'] #提取公司id标识和构造公司招聘信息的网址:
def parse(self, response):
#parse是默认处理response的方法
bs = bs4.BeautifulSoup(response.text, 'html.parser')
ul_list = bs.find_all('ul',class_="textList flsty cfix")
for ul in ul_list:
a_list = ul.find_all('a')
for a in a_list:
company_id = a['href']
url = 'https://www.jobui.com{id}jobs'
real_url = url.format(id=company_id)
yield scrapy.Request(real_url, callback=self.parse_job)
#用yield语句把构造好的request对象传递给引擎。用scrapy.Request构造request对象。callback参数设置调用parsejob方法。 def parse_job(self, response):
#定义新的处理response的方法parse_job(方法的名字可以自己起)
bs = bs4.BeautifulSoup(response.text, 'html.parser')
#用BeautifulSoup解析response(公司招聘信息的网页源代码)
company = bs.find(id="companyH1").text
#用fin方法提取出公司名称
datas = bs.find_all('li',class_="company-job-list")
#用find_all提取<li class_="company-job-list">标签,里面含有招聘信息的数据
for data in datas:
#遍历datas
item = JobuiItem()
#实例化JobuiItem这个类
item['company'] = company
#把公司名称放回JobuiItem类的company属性里
item['position']=data.find('h3').find('a').text
#提取出职位名称,并把这个数据放回JobuiItem类的position属性里
item['address'] = data.find('span',class_="col80").text
#提取出工作地点,并把这个数据放回JobuiItem类的address属性里
item['detail'] = data.find('span',class_="col150").text
#提取出招聘要求,并把这个数据放回JobuiItem类的detail属性里
yield item
#用yield语句把item传递给引擎

32、出任爬虫公司CEO(爬取职友网招聘信息)的更多相关文章
- python - 爬虫入门练习 爬取链家网二手房信息
import requests from bs4 import BeautifulSoup import sqlite3 conn = sqlite3.connect("test.db&qu ...
- python爬虫基础应用----爬取校花网视频
一.爬虫简单介绍 爬虫是什么? 爬虫是首先使用模拟浏览器访问网站获取数据,然后通过解析过滤获得有价值的信息,最后保存到到自己库中的程序. 爬虫程序包括哪些模块? python中的爬虫程序主要包括,re ...
- Python爬虫使用selenium爬取qq群的成员信息(全自动实现自动登陆)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: python小爬虫 PS:如有需要Python学习资料的小伙伴可以 ...
- Python爬虫训练:爬取酷燃网视频数据
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 项目目标 爬取酷燃网视频数据 https://krcom.cn/ 环境 Py ...
- 使用 Scrapy 爬取去哪儿网景区信息
Scrapy 是一个使用 Python 语言开发,为了爬取网站数据,提取结构性数据而编写的应用框架,它用途广泛,比如:数据挖掘.监测和自动化测试.安装使用终端命令 pip install Scrapy ...
- 利用scrapy爬取腾讯的招聘信息
利用scrapy框架抓取腾讯的招聘信息,爬取地址为:https://hr.tencent.com/position.php 抓取字段包括:招聘岗位,人数,工作地点,发布时间,及具体的工作要求和工作任务 ...
- Scrapy爬虫框架之爬取校花网图片
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- python3爬虫-通过requests爬取图虫网
import requests from fake_useragent import UserAgent from requests.exceptions import Timeout from ur ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
随机推荐
- Unit Test in SpringBoot
此处的Unit Test in SpringBoot 包括: SpringApplication Test Service Test ControllerTest 测试项目结构如下: 代码如下: PO ...
- 二、PHP链接mongodb
<?php $db=new Mongo("mongodb://sa:sa@localhost:27017"); $c=$db->selectDB("TestD ...
- sonarqube修改自己的图像avatar
https://community.sonarsource.com/t/how-can-i-change-my-avatar/11457/2 Hi, User icons are provided b ...
- 四、日志输出Reporter.log
一.Reporter.log import org.testng.Reporter; public class TestLog { public static void main(String[] a ...
- Mimikatz 攻防杂谈
前几天看到了老外一篇讲 mimikatz 防御的文章,感觉行文思路还不错,但是内容稍有不足,国内也有一篇翻译,但是只是照着错误翻译的,所以就萌生了把那篇优秀文章,翻译复现,并加入其它一些内容,本文只是 ...
- JavaEE-实验三 Java数据库高级编程
该博客仅专为我的小伙伴提供参考而附加,没空加上代码具体解析,望各位谅解 1.在MySQL中运行以下脚本 CREATE DATABASE mydatabase; USE mydatabase; CREA ...
- Python线程和协程
写在前面 好好学习 天天向上 一.线程 1.关于线程的补充 线程:就是一条流水线的执行过程,一条流水线必须属于一个车间: 那这个车间的运行过程就是一个进程: 即一个进程内,至少有一个线程: 进程是一个 ...
- 阶段3 2.Spring_01.Spring框架简介_01.spring课程四天安排
spring共四天 第一天:spring框架的概述以及spring中基于XML的IOC配置 第二天:spring中基于注解的IOC和ioc的案例 第三天:spring中的aop和基于XML以及注解的A ...
- LoadRunner 技巧之 检查点
LoadRunner 技巧之 检查点 判断脚本是否执行成功是根据服务器返回的状态来确定的,如果服务器返回的HTTP状态为 200 OK ,那么VuGen 就认为脚本正确地运行了,并且是运行通过的.在绝 ...
- PHP加速器eAccelerator安装
程序说明 eAccelerator是一个自由开放源码php加速器,优化和动态内容缓存,提高了php脚本的缓存性能,使得PHP脚本在编译的状态下,对 服务器的开销几乎为零. 它还有对脚本起优化作用,以加 ...