负载均衡-一致性Hash算法
1. Hash算法
哈希(Hash)也称为散列,把任意长度的输入,通过散列算法变换成固定长度的输出,该输出就是散列值、哈希值(hashCode)。(来自:百度百科)
在现实中,设计者常常将散列值作为索引,用于快速定位数据的位置,比如 HashMap :
// cache => key:userId, value:phone
Map<String, String> cache = new HashMap<>();
cache.put("user:001","159xxxx0001");
cache.put("user:002","159xxxx0002");
cache.put("user:003","159xxxx0003");
// 查询 "user:001" 的手机号
String phone = cache.get("user:001");
为了引入一致性Hash算法,我需要举个例子:

现在 A公司 发展良好,上亿的用户量,架构师设计出一个方案:根据用户id分库,通过对用户id进行Hash运算,计算出一个散列值,来决定用户数据存储在哪一个节点。
由此出现一个问题,怎么才能保证数据均匀分布在各个节点?假如全部数据都存储在 节点1 这个分库就是失败的,和不分库一模一样不是吗?这种状况专业术语叫数据倾斜。
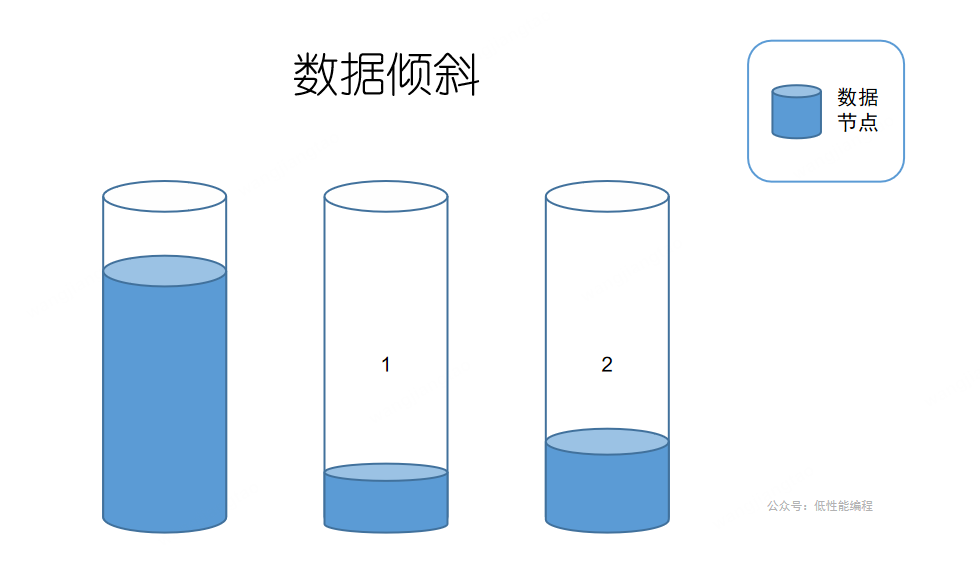
那怎么才能均匀存储在各个节点呢?答案是 1.选择合适的数据作为key、2.设计优秀的散列函数。
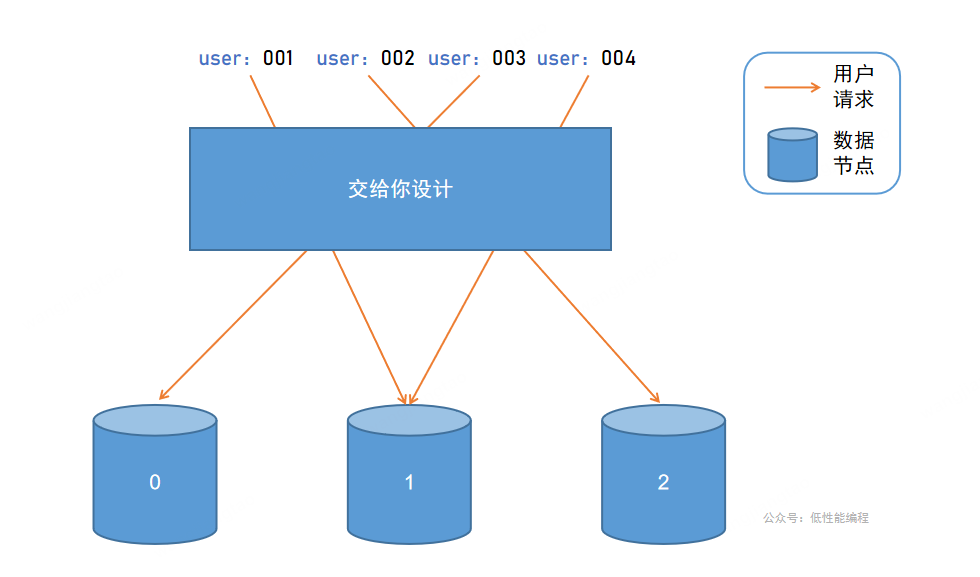
跑题了,今天要讲的是负载均衡。
下文举例中,hash算法选最简单的取余法,方便理解
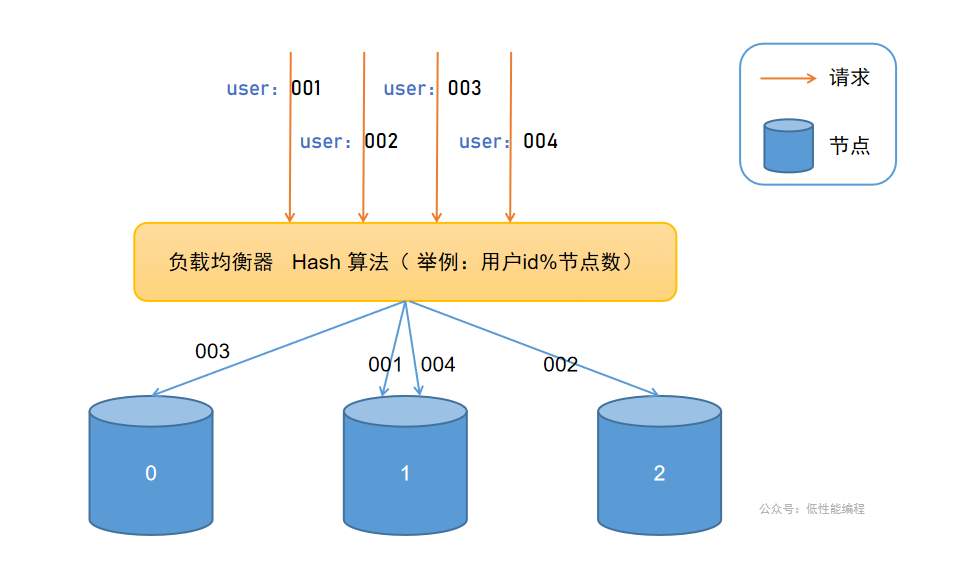
如图所示、显然、易得,上图中,有四个请求,有三个节点,我们该怎么让请求均匀的打在节点上?这是不是和上面根据用户ID分库的栗子有共同之处,首先需要选择一个合适的数据当作key,还有一个优秀的散列函数,但是这很难很好的实现。
问题1:如何让请求均匀命中节点?
如果我现在加一个节点,user:004将会映射在 节点0上(注:4%4=0),由于user:004以前将数据存储在节点1,那么将查询不到 user:004的数据。
问题2:如何解决动态增加、减少节点带来的问题?
2. 一致性Hash算法
背景之类的东西就跳过了。
上面的散列函数是用户id%节点数,节点数是会动态增减的,那我们把节点数设置为一个固定的大数(2^32),这样就解决了动态增加、减少节点带来的问题。

再上图:
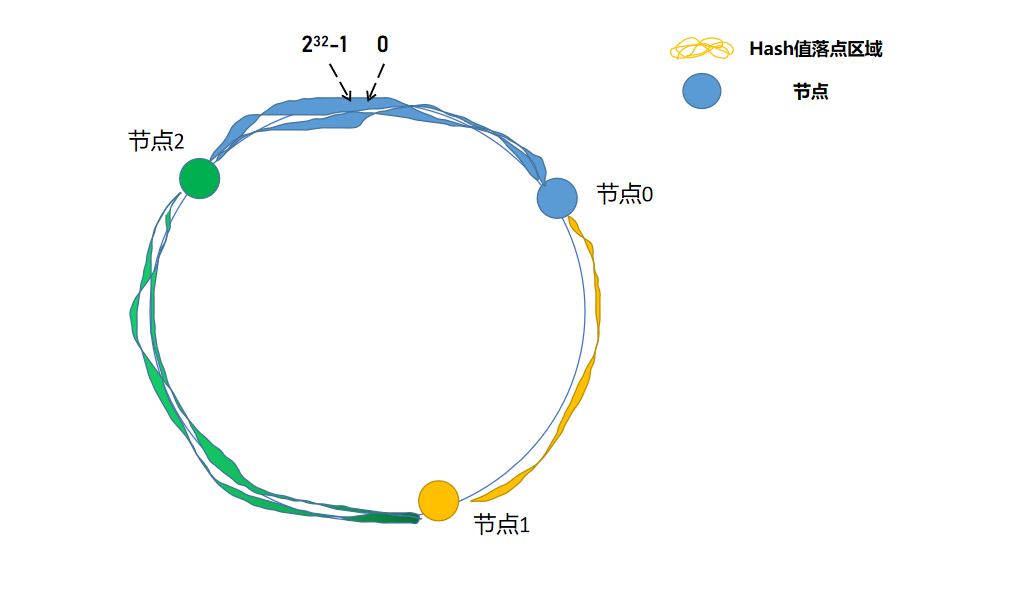
解释一下,就是将散列函数变为 用户id % \(2^{32}\),如果散列值落在 节点0 与 节点1 之间,那么我们选择 节点1 ,同理,如果落在 节点1 与 节点2 之间,我们选择 节点2 ,我们也称这个环为Hash环。
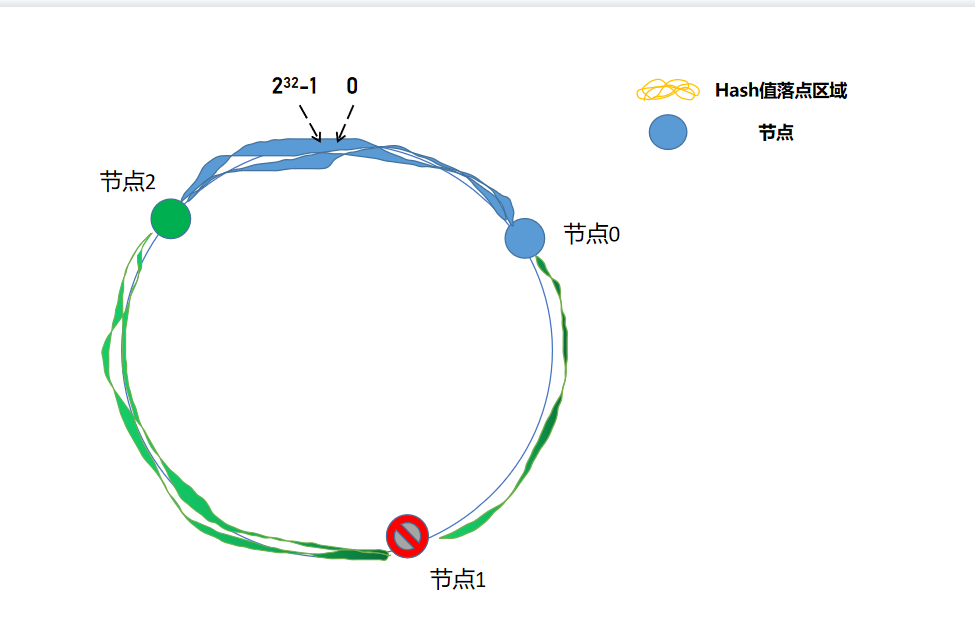
服务器减少:

节点1 挂掉后,其余节点依旧能正常工作,只不过原本打在 节点1 的请求,按照逻辑,打在了 节点2 上,所以需要将 节点1 的数据全部分配在节点2,这可能造成 节点2 短时间接收大量请求,节点2 也挂掉,然后导致请求全部打在 节点0,从而形成雪崩效应,全部节点挂掉。
服务器增加:
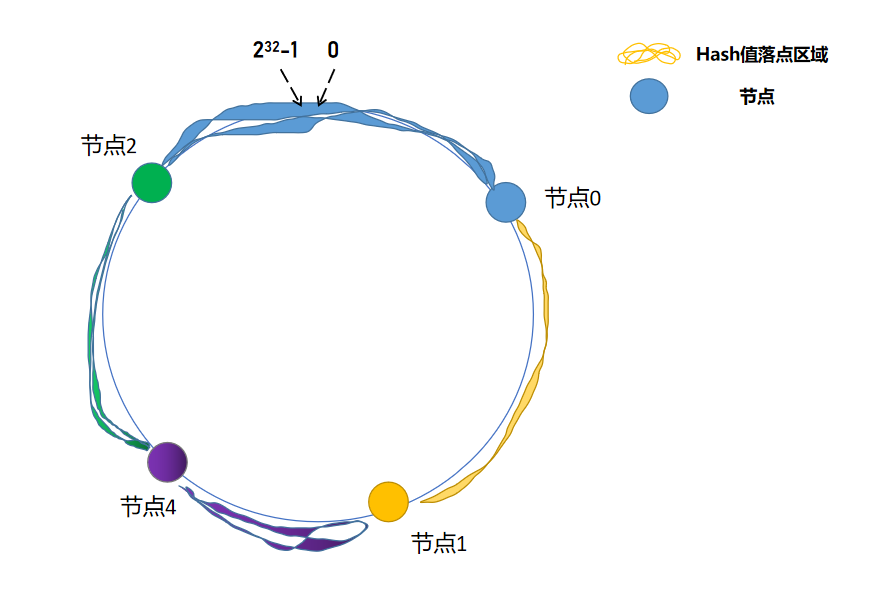
增加 节点4 , 只需将原本在 节点2 的部分数据重新分配在 节点4 。
上面解决了,增加节点与减少节点,节点数据的问题,但是没解决一个问题就是,数据倾斜的问题。
如这图,存储在 节点2 的数据概率远多于 节点0,根据概率论,极大可能会造成数据倾斜问题。
解决这个办法的问题是:添加虚拟节点。
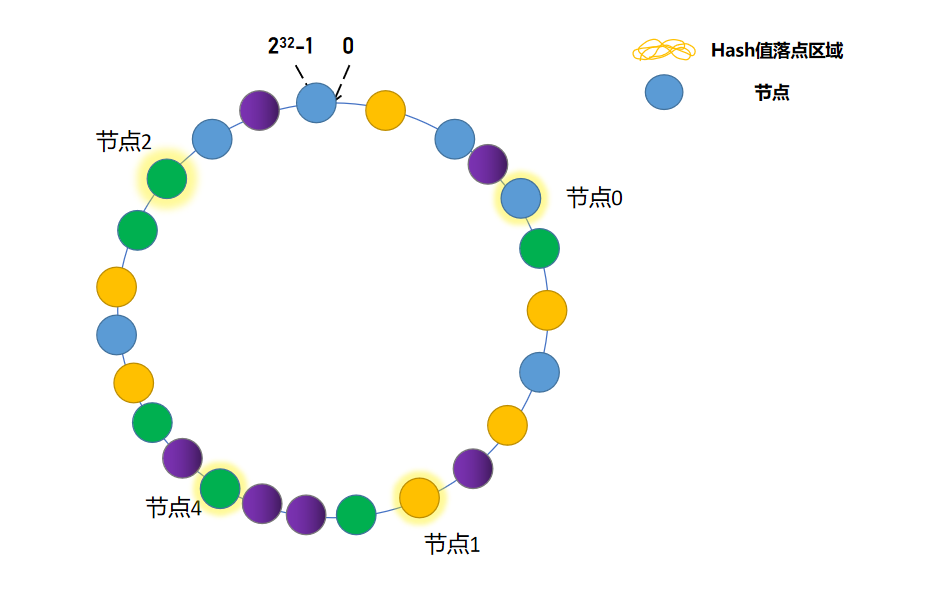
发光的节点为真实节点,不发光节点为虚拟节点,这样一操作,眼睛看着都均匀了,当然虚拟节点越多越均匀(概率论问题),假如请求命中虚拟节点,会将请求转发至真实节点,不理解了吧。
// 返回一个键大于等于给定键的最小键值对的Entry对象。如果没有这样的键值对存在,则返回null。
Map.Entry<Long, Invoker<T>> entry = virtualInvokers.ceilingEntry(hash);
看个源码吧:
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.dubbo.rpc.cluster.loadbalance;
import org.apache.dubbo.common.URL;
import org.apache.dubbo.common.io.Bytes;
import org.apache.dubbo.rpc.Invocation;
import org.apache.dubbo.rpc.Invoker;
import org.apache.dubbo.rpc.support.RpcUtils;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import static org.apache.dubbo.common.constants.CommonConstants.$INVOKE;
import static org.apache.dubbo.common.constants.CommonConstants.COMMA_SPLIT_PATTERN;
/**
* ConsistentHashLoadBalance
*/
public class ConsistentHashLoadBalance extends AbstractLoadBalance {
public static final String NAME = "consistenthash";
/**
* Hash nodes name
*/
public static final String HASH_NODES = "hash.nodes";
/**
* Hash arguments name
*/
public static final String HASH_ARGUMENTS = "hash.arguments";
private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<String, ConsistentHashSelector<?>>();
@SuppressWarnings("unchecked")
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// dubbo 把节点包装成Invoker,invokers 就相当于节点列表
String methodName = RpcUtils.getMethodName(invocation);
// eg. com.example.service.getUser 每个方法,对应一个selector
String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;
// invokers.hashCode() 也就说是节点列表的HashCode
int invokersHashCode = invokers.hashCode();
ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);
// 如果selector==null,说明还未初始化,如果selector.identityHashCode != invokersHashCode,说明增加或者减少了节点。
if (selector == null || selector.identityHashCode != invokersHashCode) {
selectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, invokersHashCode));
selector = (ConsistentHashSelector<T>) selectors.get(key);
}
return selector.select(invocation);
}
private static final class ConsistentHashSelector<T> {
private final TreeMap<Long, Invoker<T>> virtualInvokers;
private final int replicaNumber;
private final int identityHashCode;
private final int[] argumentIndex;
ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {
// 虚拟节点Map
this.virtualInvokers = new TreeMap<Long, Invoker<T>>();
// ConsistentHashSelector 的唯一标识,假如增加、减少节点,那么唯一标识会发生改变
this.identityHashCode = identityHashCode;
URL url = invokers.get(0).getUrl();
// 虚拟节点数,默认160
this.replicaNumber = url.getMethodParameter(methodName, HASH_NODES, 160);
String[] index = COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, HASH_ARGUMENTS, "0"));
argumentIndex = new int[index.length];
for (int i = 0; i < index.length; i++) {
argumentIndex[i] = Integer.parseInt(index[i]);
}
// 将虚拟节点放进virtualInvokers
for (Invoker<T> invoker : invokers) {
String address = invoker.getUrl().getAddress();
// 俩个循环,总共 replicaNumber 个虚拟节点,这样做为了让虚拟节点分布更均匀
for (int i = 0; i < replicaNumber / 4; i++) {
byte[] digest = Bytes.getMD5(address + i);
for (int h = 0; h < 4; h++) {
long m = hash(digest, h);
virtualInvokers.put(m, invoker);
}
}
}
}
public Invoker<T> select(Invocation invocation) {
boolean isGeneric = invocation.getMethodName().equals($INVOKE);
String key = toKey(invocation.getArguments(),isGeneric);
byte[] digest = Bytes.getMD5(key);
return selectForKey(hash(digest, 0));
}
private String toKey(Object[] args, boolean isGeneric) {
return isGeneric ? toKey((Object[]) args[1]) : toKey(args);
}
private String toKey(Object[] args) {
StringBuilder buf = new StringBuilder();
for (int i : argumentIndex) {
if (i >= 0 && args != null && i < args.length) {
buf.append(args[i]);
}
}
return buf.toString();
}
private Invoker<T> selectForKey(long hash) {
// 返回一个键大于等于给定键的最小键值对的Entry对象。如果没有这样的键值对存在,则返回null。
Map.Entry<Long, Invoker<T>> entry = virtualInvokers.ceilingEntry(hash);
if (entry == null) {
entry = virtualInvokers.firstEntry();
}
return entry.getValue();
}
// hash环2^32体现在这里,0xFFFFFFFFL = 2^32 - 1,说明 hash值只能取到0 ~ 2^32-1
private long hash(byte[] digest, int number) {
return (((long) (digest[3 + number * 4] & 0xFF) << 24)
| ((long) (digest[2 + number * 4] & 0xFF) << 16)
| ((long) (digest[1 + number * 4] & 0xFF) << 8)
| (digest[number * 4] & 0xFF))
& 0xFFFFFFFFL;
}
}
}
3. 总结
Hash算法: 用户id % 节点数,常被当作索引,用来快速定位数据,但是在负载均衡这个问题上,存在容易导致数据倾斜、动态增减节点的问题。
一致性Hash算法,通过将Hash环分为2^32个插槽,巧妙利用虚拟节点,提供了解决数据倾斜、动态增减节点的思路。
负载均衡-一致性Hash算法的更多相关文章
- 一致性hash算法--负载均衡
有没有好奇过redis.memcache等是怎么实现集群负载均衡的呢? 其实他们都是通过一致性hash算法实现节点调度的. 讲一致性hash算法前,先简述一下求余hash算法: hash(object ...
- 不会一致性hash算法,劝你简历别写搞过负载均衡
大家好,我是小富~ 个人公众号:程序员内点事,欢迎学习交流 这两天看到技术群里,有小伙伴在讨论一致性hash算法的问题,正愁没啥写的题目就来了,那就简单介绍下它的原理.下边我们以分布式缓存中经典场景举 ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 一致性hash算法详解
转载请说明出处:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT) ...
- memcache的一致性hash算法使用
一.概述 1.我们的memcache客户端(这里我看的spymemcache的源码),使用了一致性hash算法ketama进行数据存储节点的选择.与常规的hash算法思路不同,只是对我们要存储数据的k ...
- 一致性Hash算法在Memcached中的应用
前言 大家应该都知道Memcached要想实现分布式只能在客户端来完成,目前比较流行的是通过一致性hash算法来实现.常规的方法是将server的hash值与server的总台数进行求余,即hash% ...
- 分布式算法(一致性Hash算法)
一.分布式算法 在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin).哈希算法(HASH).最少连接算法(Least Connection).响应速度算法( ...
- Java实现一致性Hash算法深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中”一致性Hash算法”部分,对于为什么要使用一致性Hash算法和一致性Hash算法的算法原 ...
- 一致性Hash算法与代码实现
一致性Hash算法: 先构造一个长度为232的整数环(这个环被称为一致性Hash环),根据节点名称的Hash值(其分布为[0, 232-1])将服务器节点放置在这个Hash环上,然后根据数据的Key值 ...
- 一致性Hash算法介绍(分布式环境算法)
32的整数环(这个环被称作一致性Hash环),根据节点名称的Hash值(其分布范围同样为0~232)将节点放置在这个Hash 环上.然后根据KEY值计算得到其Hash值(其分布范围也同样为0~232 ...
随机推荐
- C++17新特性探索:拥抱std::optional,让代码更优雅、更安全
std::optional 背景 在编程时,我们经常会遇到可能会返回/传递/使用一个确定类型对象的场景.也就是说,这个对象可能有一个确定类型的值也可能没有任何值.因此,我们需要一种方法来模拟类似指针的 ...
- Angular 18+ 高级教程 – Change Detection & Ivy rendering engine
前言 不熟悉 Angular 的朋友可能不了解 Change Detection 和目前当火的 Signal 之间的关系,以至于认为现在应该要学习新潮流 Signal 而不是已经过时的 Change ...
- CSS – Flex
前言 Flex 诞生在 Float 之后, Grid 之前, 它主要是取代 Float 来实现布局. 而它没有 cover 到的地方则由 Grid 弥补. 所以当前, 我们做布局时, 几乎不用 Flo ...
- JAVA与.NET DES加密解密
项目需要在两个系统间采用DES加密,一个系统为JAVA开发的,另外一个.Net开发的 在网上找了很多写法但加密出的数据两个系统都无法匹配, 在做了小修改以后终于可以用了,已经测试过 JAVA版本 im ...
- Docker安装(安装Docker-CE)(三)
现版本安装Docker已经非常简单了,有很多种方式,而自17年开始,Docker分为Docker-CE(社区版).Docker-EE(企业版),另外Docker-IO是较早的版本,通常用的都是Dock ...
- excel江湖异闻录--华麒麟
认识他应该是在18.19年左右,那时就感觉这也是个高手,同大部分的高手一样,痴迷函数,热衷创造.挑战不规范的数据. 后来他消失了好长一段时间,群里的同学都以为他退圈了,偶有少数的同学想起他,言语都带着 ...
- linux中backport printk和front printk的区别
在Linux内核中,"backport printk"和"front printk"都是用于记录内核消息和调试信息的机制,但它们的工作方式和使用场景有一些区别. ...
- Redis数据库常见命令
Redis数据库常见命令 Linux启动Redis # 启动服务 redis-server # 开启客户端 redis-cli # 关闭redis服务 shutdown #查看服务是否运行 ping ...
- 自签openssl证书(包含泛域名)
1.安装openSSL weget http://www.openssl.org/source/openssl-1.0.0a.tar.gz Tar -zxvf openssl-1.0.0a.tar.g ...
- 查找大量时序遥感文件缺失、不连贯的成像日期:Python代码
本文介绍批量下载大量多时相的遥感影像文件后,基于Python语言与每一景遥感影像文件的文件名,对这些已下载的影像文件加以缺失情况的核对,并自动统计.列出未下载影像所对应的时相的方法. 批量下载 ...