python爬虫学习笔记(1)
一、请求一个网页内容打印
爬取某个网页:
from urllib import request
# 需要爬取的网页
url = "https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9085796282359478067%22%7D&n_type=0&p_from=1"
# 打开网页,并返回
rsp = request.urlopen(url)
# 读取返回的结果
html = rsp.read()
# 由于rsp返回的是流文件需要解码
html = html.decode()
printf(html)
爬取一个网页的基本流程:
1、获取所需网页request.urlopen("网页链接")
2、读取返回页面 rsp.read()
3、解码:html.decode()
二、自动识别网页编码
from urllib import request
import chardet
url = "https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9085796282359478067%22%7D&n_type=0&p_from=1"
res = request.urlopen(url)
html = res.read()
# 检查编码
cs = chardet.detect(html)
# 编码设置
html = html.decode(cs.get("encoding", "utf-8"))
print(html)
第7行返回一个类似{'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}的字典 encoding是编码格式,confidence是前面编码格式的概率。第九行进行解码设置,如果有匹配的编码按照获取的方式进行解码,否则按照“utf-8”的方式解码。
三、到百度页面爬取指定内容
from urllib import request, parse
if __name__ =='__main__':
url = "http://www.baidu.com/s?"
# 输入关键词
wd = input("Input keyword:")
# 把关键字以字典保存
qs = {
"wd":wd
}
# 把关键字进行编码
qs = parse.urlencode(qs)
# 拼凑成完整的url
fullurl = url + qs
res = request.urlopen(fullurl)
html = res.read().decode()
print(html)
四、进行百度翻译:
解析:
1、打开F12
2、尝试输入单词,发现每输入一个字母都有请求
3、找到请求的地址:https://fanyi.baidu.com/sug
4、在NetWork-All-Headers中查看,发现FormData的关键字是 kw:单词
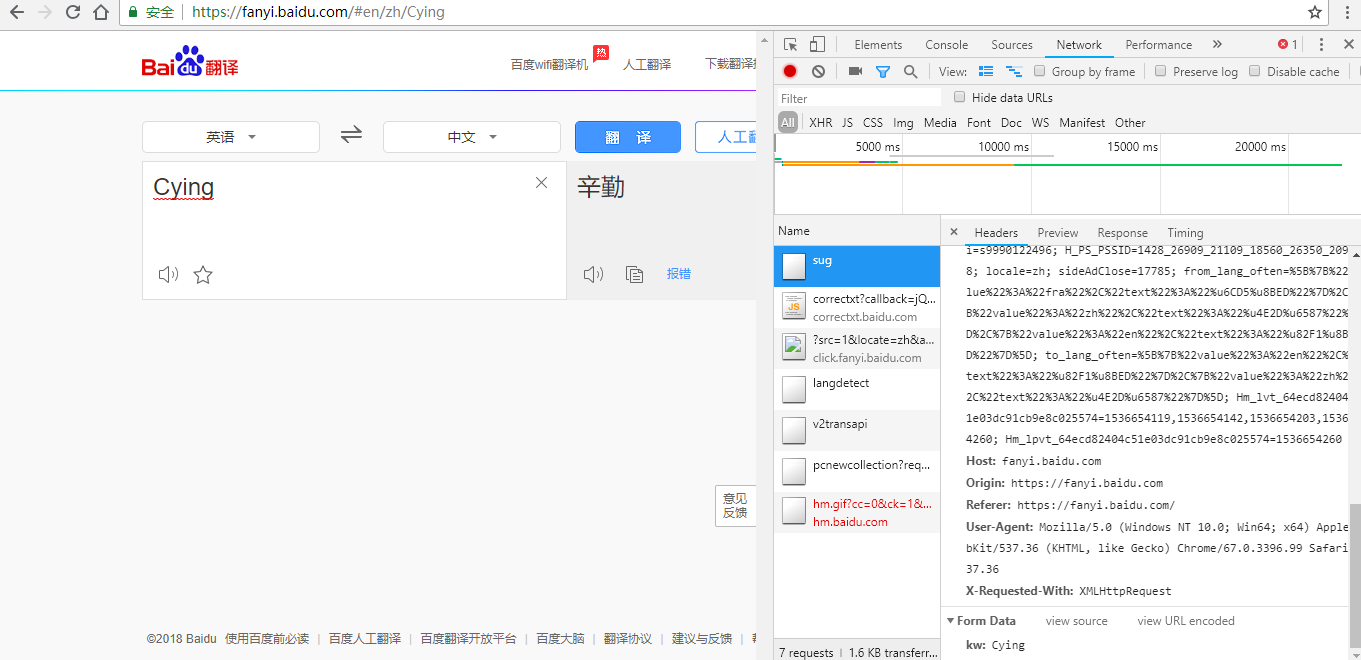
5、打开sug文件发现数据时json格式
方式一:
from urllib import request, parse
import json
baseurl = "https://fanyi.baidu.com/sug"
word = input("请输入单词: ")
data = {
"kw":word
}
# 对单词进行编码
data = parse.urlencode(data).encode()
# 构建请求头
rsp = request.urlopen(baseurl, data = data)
json_data = rsp.read().decode()
# 由于返回的是json数据,转换成字典
json_data = json.loads(json_data)
for item in json_data['data']:
print(item['k'], item['v'])
翻译流程:
1、利用data构造内容,然后用URLopen打开
2、返回一个json格式
3、转换成字典,输出
方式二:
from urllib import request, parse
import json
baseurl = "https://fanyi.baidu.com/sug"
word = input("请输入单词:")
data = {
"kw": word
}
data = parse.urlencode(data).encode('utf-8')
headers = {
'Content-Length':len(data)
}
req = request.Request(url = baseurl, data = data, headers = headers)
res = request.urlopen(req)
json_data = res.read().decode()
json_data = json.loads(json_data)
for item in json_data['data']:
print(item['k'], item['v])
五、urllib.error
在某些时候爬取网站出现问题,可以通过 URLError和HTTPError查找问题
1、URLError产生原因
- 没网
- 没有指定服务器
- 服务器连接失败
from urllib import request, error
if __name__ == '__main__':
url = "http://www.baidu.com"
try:
req = request.Request(url)
res = request.urlopen(req)
html = res.read().decode()
except error.URLError as e:
print("URLError: {0}".format(e.reason))
except Exception as e:
print(e)
2、HTTPError
HTTPError一般对应HTTP请求的返回码错误,如果返回的错误码是400以上引发HTTPError
与URLError的关系:
OSError -> URLError -> HTTPError
代码:
from urllib import request, error
if __name__ == '__main__':
url = "http://www.baidu.com"
try
req = request.Request(url)
res = request.urlopen(req)
html = res.read().decode()
except error.HTTPError as e:
print ("URLError: {0}".format(e.reason))
print ("HTTPError: {0}".format(e))
except error.URLError as e:
print ("URLError: {0}".format(e.reason))
print ("HTTPError: {0}".format(e))
except Exception as e:
print(e)
python爬虫学习笔记(1)的更多相关文章
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- Python爬虫学习笔记(三)
Cookies: 以抓取https://www.yaozh.com/为例 Test1(不使用cookies): 代码: import urllib.request # 1.添加URL url = &q ...
- python爬虫学习笔记
爬虫的分类 1.通用爬虫:通用爬虫是搜索引擎(Baidu.Google.Yahoo等)“抓取系统”的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 简单来讲就是尽可 ...
- Python、pip和scrapy的安装——Python爬虫学习笔记1
Python作为爬虫语言非常受欢迎,近期项目需要,很是学习了一番Python,在此记录学习过程:首先因为是初学,而且当时要求很快速的出demo,所以首先想到的是框架,一番查找选用了Python界大名鼎 ...
- 一入爬虫深似海,从此游戏是路人!总结我的python爬虫学习笔记!
前言 还记得是大学2年级的时候,偶然之间看到了学长在学习python:我就坐在旁边看他敲着代码,感觉很好奇.感觉很酷,从那之后,我就想和学长一样的厉害,就想让学长教我,请他吃了一周的饭,他答应了.从此 ...
- Python爬虫学习笔记——豆瓣登陆(一)
#-*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup import html5lib import re import ...
- Python爬虫学习笔记-1.Urllib库
urllib 是python内置的基本库,提供了一系列用于操作URL的功能,我们可以通过它来做一个简单的爬虫. 0X01 基本使用 简单的爬取一个页面: import urllib2 request ...
- 【Python爬虫学习笔记(3)】Beautiful Soup库相关知识点总结
1. Beautiful Soup简介 Beautiful Soup是将数据从HTML和XML文件中解析出来的一个python库,它能够提供一种符合习惯的方法去遍历搜索和修改解析树,这将大大减 ...
- 【Python爬虫学习笔记(1)】urllib2库相关知识点总结
1. urllib2的opener和handler概念 1.1 Openers: 当你获取一个URL你使用一个opener(一个urllib2.OpenerDirector的实例).正常情况下,我们使 ...
- Python爬虫学习笔记(一)
概念: 使用代码模拟用户,批量发送网络请求,批量获取数据. 分类: 通用爬虫: 通用爬虫是搜索引擎(Baidu.Google.Yahoo等)"抓取系统"的重要组成部分. 主要目的是 ...
随机推荐
- python 面向对象 【进阶】
多态 多态跟python没有太大关系,因为python本身原生支持多态. def func(arg): #多态 print (arg) func(1) func(‘pand ...
- java几种基本排序算法
1.选择排序 原理:将数组的每一个元素和第一个元素相比较,如果小于第一个元素则交换,选出第一小的,依次选出第二小,第三小的.... 代码 int[] a = {1,3,2,5}; int i,j,te ...
- 使用 Load Balancer,Corosync,Pacemaker 搭建 Linux 高可用集群
由于网络架构的原因,在一般虚拟机或物理环境中常见的用 VIP 来实现双机高可用方案,无法照搬到 Azure 平台.但利用 Azure 平台提供的负载均衡或者内部负载均衡功能,可以达到类似的效果. 本文 ...
- leetcode-valid number ZZ
http://blog.csdn.net/kenden23/article/details/18696083 本题是十分麻烦的题目,情况是非常多,网上也很多方法,其中最有效,优雅的方法是有限状态自动机 ...
- python接口自动化4-绕过验证码登录(cookie) (转载)
前言 有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接). 获取不到也没关系,可以通过添加cookie的方式绕过验证码. 一.抓登录coo ...
- window搭建svn服务器,本地提交至服务器后,直接同步
找到版本库目录(在安装svnserver时指定的目录),如下图指定了一个版本库的hooks 在其中创建post-commit.bat文件(可先创建post-cmmit.txt再修改后缀名为bat). ...
- vagrant安装centos7
1. 安装VirtualBox 去官网https://www.virtualbox.org/wiki/Downloads下载最新版的Virtualbox,然后双击安装,一直点击确认完成. 2. 安装V ...
- shell----删除文件中的^M
在Linux下使用vi来查看一些在Windows下创建的文本文件,有时会发现在行尾有一些“^M”.有几种方法可以处理. 1.使用vi的替换功能.启动vi,进入命令模式,输入以下命令: :%s/^M$/ ...
- SAP Cloud for Customer销售订单External Note的建模细节
SAP Cloud for Customer的销售订单创建页面里,我们可以给一个订单维护External Note,当这个订单同步到S/4HANA生成对应的生产订单后,这个note可以作为备注提示生产 ...
- 利用kali嗅探周围发送的短信
设备清单: 摩托罗拉 C118 (25块) FT232RL USB TO TTL (30元) 摩托罗拉 Motorola C118专用数据连接线 (10块) MiniUSB 链接线(10元,这个大家手 ...