02(c)多元无约束优化问题-牛顿法
此部分内容接《02(a)多元无约束优化问题》!
第二类:牛顿法(Newton method)
\[f({{\mathbf{x}}_{k}}+\mathbf{\delta })\text{ }\approx \text{ }f({{\mathbf{x}}_{k}})+{{\nabla }^{T}}f({{\mathbf{x}}_{k}})\cdot \mathbf{\delta }+\frac{1}{2}{{\mathbf{\delta }}^{T}}\cdot {{\nabla }^{2}}f({{\mathbf{x}}_{k}})\cdot \mathbf{\delta }\]
在${{\mathbf{x}}_{k}}$定了的情况下,$f({{\mathbf{x}}_{k}}+\mathbf{\delta })\text{ }$可以看成是$\mathbf{\delta }$的函数,要使函数达到极小值点,即找出使得函数$f({{\mathbf{x}}_{k}}+\mathbf{\delta })$对$\mathbf{\delta }$的一阶导数等于0,则有:
\[\begin{aligned}& f({{\mathbf{x}}_{k}}+\mathbf{\delta }{)}'\text{ }=\nabla f({{\mathbf{x}}_{k}})+{{\nabla }^{2}}f({{\mathbf{x}}_{k}})\cdot \mathbf{\delta } \\& \text{ =}\nabla f({{\mathbf{x}}_{k}})+H({{\mathbf{x}}_{k}})\cdot \mathbf{\delta }=0 \\\end{aligned}\]
则下降方向可写为:$\mathbf{\delta }=-{{H}^{-1}}({{\mathbf{x}}_{k}})\cdot \nabla f({{\mathbf{x}}_{k}})$。
(听课的时候就一直在想,一阶导数等于零的点就是极小值点吗???$y=a{{x}^{2}}+bx+c$一种简单的一元二次函数的一阶导数等于0的点,是不是极小值点,还的看$a$的正负呢!)
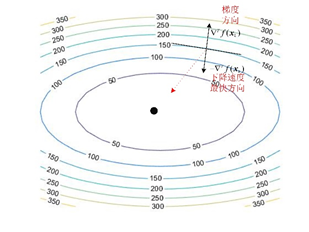
图 1
从上图中可以看出,在点${{\mathbf{x}}_{k}}$处使函数下降最快的方向是$-\nabla f({{\mathbf{x}}_{k}})$方向,但它却不是使$f({{\mathbf{x}}_{k}})$最快接近最小值的方向(最快接近最小值方向应该是上图中红色虚线的方向);由此见牛顿法的下降方向:$\mathbf{\delta }=-{{H}^{-1}}({{\mathbf{x}}_{k}})\cdot \nabla f({{\mathbf{x}}_{k}})$,就是在$-\nabla f({{\mathbf{x}}_{k}})$乘上了一个该点Hessian阵的逆${{H}^{-1}}({{\mathbf{x}}_{k}})$;我们希望的是在乘上${{H}^{-1}}({{\mathbf{x}}_{k}})$后使得下降方向朝向上图中红色虚线的方向;But,在有些情况下乘上${{H}^{-1}}({{\mathbf{x}}_{k}})$后,不但没有使函数值$f({{\mathbf{x}}_{k}})$下降,反而让函数值$f({{\mathbf{x}}_{k}})$变大了。只有当${{H}^{-1}}({{\mathbf{x}}_{k}})$在满足下面的条件下,才能使函数值不断减小:
\[\begin{aligned}& {{\left( -\nabla f({{\mathbf{x}}_{k}}) \right)}^{T}}\cdot \left( -{{H}^{-1}}({{\mathbf{x}}_{k}})\cdot \nabla f({{\mathbf{x}}_{k}}) \right)=\left\| -\nabla f({{\mathbf{x}}_{k}}) \right\|\cdot \left\| -{{H}^{-1}}({{\mathbf{x}}_{k}})\cdot \nabla f({{\mathbf{x}}_{k}}) \right\|\cos(\theta ) \\& \text{ =}{{\nabla }^{T}}f({{\mathbf{x}}_{k}})\cdot {{H}^{-1}}({{\mathbf{x}}_{k}})\cdot \nabla f({{\mathbf{x}}_{k}})>0 \\\end{aligned}\]
即要使从新获得的下降方向$-{{H}^{-1}}({{\mathbf{x}}_{k}})\cdot \nabla f({{\mathbf{x}}_{k}})$与最速下降方向$-\nabla f({{\mathbf{x}}_{k}})$之间的夹角$-{\pi }/{2}\;<\theta <{\pi }/{2}\;$。要满足:
\[{{\nabla }^{T}}f({{\mathbf{x}}_{k}})\cdot {{H}^{-1}}({{\mathbf{x}}_{k}})\nabla f({{\mathbf{x}}_{k}})>0\]
${{H}^{-1}}({{\mathbf{x}}_{k}})$要达到什么样的条件呢,由正定二次型的性质可知,当${{H}^{-1}}({{\mathbf{x}}_{k}})$为正定阵(等价于${{H}^{-1}}({{\mathbf{x}}_{k}})\succ 0$的全部特征值大于0)时,式(12)恒成立;当${{H}^{-1}}({{\mathbf{x}}_{k}})$不是正定阵的情况下仍然希望使用牛顿法,则需要对最速下降方向$-\nabla f({{\mathbf{x}}_{k}})$前面乘的Hessian阵的逆${{H}^{-1}}({{\mathbf{x}}_{k}})$进行改进;由于${{H}^{-1}}({{\mathbf{x}}_{k}})$为一个实对称阵,所以一定能正交分解,这里取${{\lambda }_{1}},{{\lambda }_{2}},...,{{\lambda }_{n}}$从大到小排:
\[{{H}^{-1}}({{\mathbf{x}}_{k}})=U\left[ \begin{matrix}{{\lambda }_{1}} & {} & {} & {} \\{} & {{\lambda }_{2}} & {} & {} \\{} & {} & \ddots & {} \\{} & {} & {} & {{\lambda }_{n}} \\\end{matrix} \right]{{U}^{T}}\]
具体步骤:
s1:找出${{H}^{-1}}({{\mathbf{x}}_{k}})$的最小特征值:Matlab代码可写为$\min (eig({{H}^{-1}}({{\mathbf{x}}_{k}})))=-9.8$;
s2:组合得到一个新的${{\hat{H}}^{-1}}({{\mathbf{x}}_{k}})={{H}^{-1}}({{\mathbf{x}}_{k}})+9.9E$;
\[\begin{aligned}& {{{\hat{H}}}^{-1}}({{\mathbf{x}}_{k}})=U\left[ \begin{matrix}{{\lambda }_{1}} & {} & {} & {} \\{} & {{\lambda }_{2}} & {} & {} \\{} & {} & \ddots & {} \\{} & {} & {} & -9.8 \\\end{matrix} \right]{{U}^{T}}+9.9UE{{U}^{T}} \\& \text{ }=U\left[ \begin{matrix}{{\lambda }_{1}}+9.9 & {} & {} & {} \\{} & {{\lambda }_{2}}+9.9 & {} & {} \\{} & {} & \ddots & {} \\{} & {} & {} & 0.1 \\\end{matrix} \right]{{U}^{T}}\succ 0 \\\end{aligned}\]
这里由于$U$为正交阵,故由$U{{U}^{T}}=E$,这样牛顿法的下降方向可写为:
\[\mathbf{\delta }=-{{\hat{H}}^{-1}}({{\mathbf{x}}_{k}})\cdot \nabla f({{\mathbf{x}}_{k}})\]
Step3:通过Step2确定下降方向${{\mathbf{d}}_{k}}$之后,$f({{\mathbf{x}}_{k}}+{{\alpha }_{k}}{{\mathbf{d}}_{k}})$可以看成${{\alpha }_{k}}$的一维函数,这一步的主要方法有(Dichotomous search, Fibonacci search, Goldensection search, quadratic interpolation method, and cubic interpolation method);所确定一个步长${{\alpha }_{k}}>0$,${{\mathbf{x}}_{k+1}}={{\mathbf{x}}_{k}}+{{\alpha }_{k}}{{\mathbf{d}}_{k}}$;
Step4: if走一步的距离$\left\| {{\alpha }_{k}}{{\mathbf{d}}_{k}} \right\|<\varepsilon $,则停止并且输出解${{\mathbf{x}}_{k+1}}$;else $k:=k+1$并返回Step2,继续迭代。
02(c)多元无约束优化问题-牛顿法的更多相关文章
- 02(d)多元无约束优化问题-拟牛顿法
此部分内容接<02(a)多元无约束优化问题-牛顿法>!!! 第三类:拟牛顿法(Quasi-Newton methods) 拟牛顿法的下降方向写为: ${{\mathbf{d}}_{k}}= ...
- 02(b)多元无约束优化问题-最速下降法
此部分内容接02(a)多元无约束优化问题的内容! 第一类:最速下降法(Steepest descent method) \[f({{\mathbf{x}}_{k}}+\mathbf{\delta }) ...
- 02(a)多元无约束优化问题
2.1 基本优化问题 $\operatorname{minimize}\text{ }f(x)\text{ for }x\in {{R}^{n}}$ 解决无约束优化问题的一般步骤 ...
- 02(e)多元无约束优化问题- 梯度的两种求解方法以及有约束转化为无约束问题
2.1 求解梯度的两种方法 以$f(x,y)={{x}^{2}}+{{y}^{3}}$为例,很容易得到: $\nabla f=\left[ \begin{aligned}& \frac{\pa ...
- 无约束优化算法——牛顿法与拟牛顿法(DFP,BFGS,LBFGS)
简介:最近在看逻辑回归算法,在算法构建模型的过程中需要对参数进行求解,采用的方法有梯度下降法和无约束项优化算法.之前对无约束项优化算法并不是很了解,于是在学习逻辑回归之前,先对无约束项优化算法中经典的 ...
- 无约束优化方法(梯度法-牛顿法-BFGS- L-BFGS)
本文讲解的是无约束优化中几个常见的基于梯度的方法,主要有梯度下降与牛顿方法.BFGS 与 L-BFGS 算法. 梯度下降法是基于目标函数梯度的,算法的收敛速度是线性的,并且当问题是病态时或者问题规模较 ...
- MATLAB进行无约束优化
首先先给出三个例子引入fminbnd和fminuc函数求解无约束优化,对这些函数有个初步的了解 求f=2exp(-x)sin(x)在(0,8)上的最大.最小值. 例2 边长3m的正方形铁板,四角减去相 ...
- 01(b)无约束优化(准备知识)
1.解方程转化为优化问题 $n\left\{ \begin{aligned}& {{P}_{1}}(x)=0 \\ & {{P}_{2}}(x)=0 \\ & \text{ ...
- 065 01 Android 零基础入门 01 Java基础语法 08 Java方法 02 带参无返回值方法
065 01 Android 零基础入门 01 Java基础语法 08 Java方法 03 带参无返回值方法 本文知识点:带参无返回值方法 说明:因为时间紧张,本人写博客过程中只是对知识点的关键步骤进 ...
随机推荐
- 微信红包功能(含示例demo)
开通支付权限 登录微信公众平台管理后台,找到“微信支付”一栏,进行开通会跳转到“微信支付商户平台”,根据提示提交相关证明,完成支付权限的开通开通之后,“微信支付”一栏会显示相关信息,在“开发-接口权限 ...
- Token的设计(2)
词法分析 Token的几个种类 前端的第一步就是词法分析, 这个过程通俗来讲就是将源代码转化为一串Tokens. 所以首先应该想到的是, 到底该有哪几种类型的Token ? 关于这个问题我已经想过了, ...
- Android零基础入门第35节:Android中基于回调的事件处理
原文:Android零基础入门第35节:Android中基于回调的事件处理 通过前面两期掌握了Android中基于监听的事件处理的五种形式,那么本期一起来学习Android中基于回调的事件处理. 一. ...
- Asp.Net MVC实现优酷(youku)Web的上传
优酷第三方上传API没有.NET版本的SDK,让从事.NET开发人员要实现开放平台上传文件无从下手.本文经过一天的预读优酷文档,以NET方式实现了视频上传. 参考: 优酷开放文档 http://ope ...
- Oracle emca on linux
http://blog.csdn.net/haibusuanyun/article/details/16338591 bash-3.2$ lsnrctl status LSNRCTL for Lin ...
- delphi 实现微信开发(1) (使用kbmmw web server)
原文地址:delphi 实现微信开发(1)作者:红鱼儿 大体思路: 1.用户向服务号发消息,(这里可以是个菜单项,也可以是一个关键词,如:注册会员.) 2.kbmmw web server收到消息,生 ...
- JavaScript语言核心--词法结构
编程语言的词法结构是一套基础性规则,用来描述如何使用这门语言来编写程序.作为语法的基础,它规定了诸如变量名是什么样的.怎么写注释,以及程序语言之间如何分隔等规则. 1. 字符集 JavaScript程 ...
- Qt在Windows上的调试器安装与配置
如果安装Qt时使用的是Visual Studio的预编译版,那么很有可能就会缺少调试器(Debugger),而使用MSVC的Qt对应的原生调试器是CDB(对应MinGW的Qt使用GDB调试器).本文介 ...
- Memory Ordering (注意Cache带来的副作用,每个CPU都有自己的Cache,内存读写不再一定需要真的作内存访问)
Memory Ordering Background 很久很久很久以前,CPU忠厚老实,一条一条指令的执行我们给它的程序,规规矩矩的进行计算和内存的存取. 很久很久以前, CPU学会了Out-Of ...
- 最短JS判断IE6/IE7/IE8系列的写法
常用的 var isIE=!!window.ActiveXObject; var isIE6=isIE&&!window.XMLHttpRequest; var isIE8=isIE& ...