Storm —— 集群环境搭建
一、集群规划
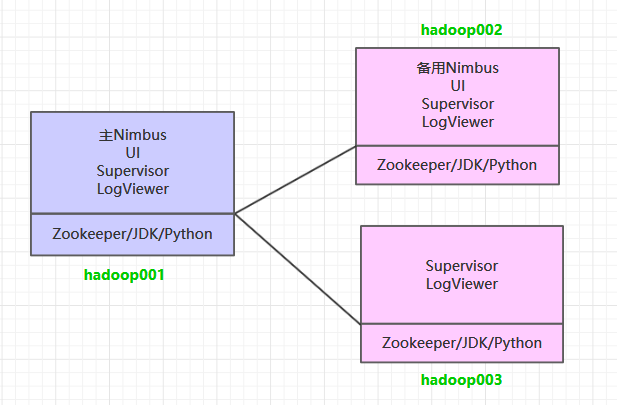
这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务。同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop002上部署备用的Nimbus服务。Nimbus服务由Zookeeper集群进行协调管理,如果主Nimbus不可用,则备用Nimbus会成为新的主Nimbus。
二、前置条件
Storm 运行依赖于Java 7+ 和 Python 2.6.6 +,所以需要预先安装这两个软件。同时为了保证高可用,这里我们不采用Storm内置的Zookeeper,而采用外置的Zookeeper集群。由于这三个软件在多个框架中都有依赖,其安装步骤单独整理至 :
三、集群搭建
1. 下载并解压
下载安装包,之后进行解压。官方下载地址:http://storm.apache.org/downloads.html
# 解压
tar -zxvf apache-storm-1.2.2.tar.gz
2. 配置环境变量
# vim /etc/profile
添加环境变量:
export STORM_HOME=/usr/app/apache-storm-1.2.2
export PATH=$STORM_HOME/bin:$PATH
使得配置的环境变量生效:
# source /etc/profile
3. 集群配置
修改${STORM_HOME}/conf/storm.yaml文件,配置如下:
# Zookeeper集群的主机列表
storm.zookeeper.servers:
- "hadoop001"
- "hadoop002"
- "hadoop003"
# Nimbus的节点列表
nimbus.seeds: ["hadoop001","hadoop002"]
# Nimbus和Supervisor需要使用本地磁盘上来存储少量状态(如jar包,配置文件等)
storm.local.dir: "/home/storm"
# workers进程的端口,每个worker进程会使用一个端口来接收消息
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
supervisor.slots.ports参数用来配置workers进程接收消息的端口,默认每个supervisor节点上会启动4个worker,当然你也可以按照自己的需要和服务器性能进行设置,假设只想启动2个worker的话,此处配置2个端口即可。
4. 安装包分发
将Storm的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下Storm的环境变量。
scp -r /usr/app/apache-storm-1.2.2/ root@hadoop002:/usr/app/
scp -r /usr/app/apache-storm-1.2.2/ root@hadoop003:/usr/app/
四. 启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动ZooKeeper服务:
zkServer.sh start
4.2 启动Storm集群
因为要启动多个进程,所以统一采用后台进程的方式启动。进入到${STORM_HOME}/bin目录下,执行下面的命令:
hadoop001 & hadoop002 :
# 启动主节点 nimbus
nohup sh storm nimbus &
# 启动从节点 supervisor
nohup sh storm supervisor &
# 启动UI界面 ui
nohup sh storm ui &
# 启动日志查看服务 logviewer
nohup sh storm logviewer &
hadoop003 :
hadoop003上只需要启动supervisor服务和logviewer服务:
# 启动从节点 supervisor
nohup sh storm supervisor &
# 启动日志查看服务 logviewer
nohup sh storm logviewer &
4.3 查看集群
使用jps查看进程,三台服务器的进程应该分别如下:

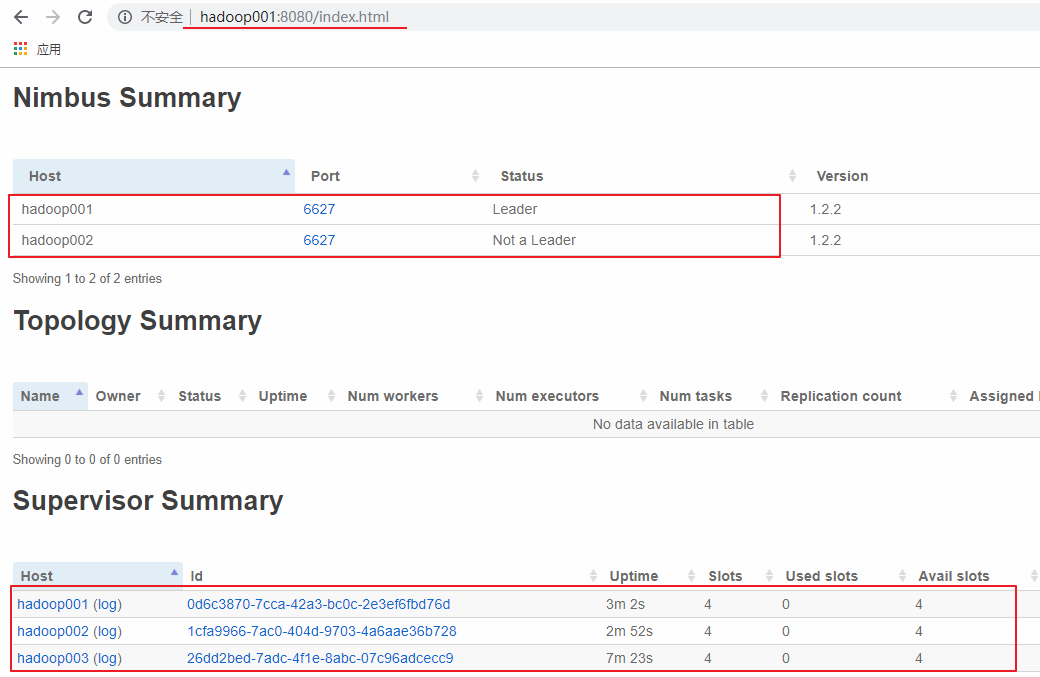
访问hadoop001或hadoop002的8080端口,界面如下。可以看到有一主一备2个Nimbus和3个Supervisor,并且每个Supervisor有四个slots,即四个可用的worker进程,此时代表集群已经搭建成功。
五、高可用验证
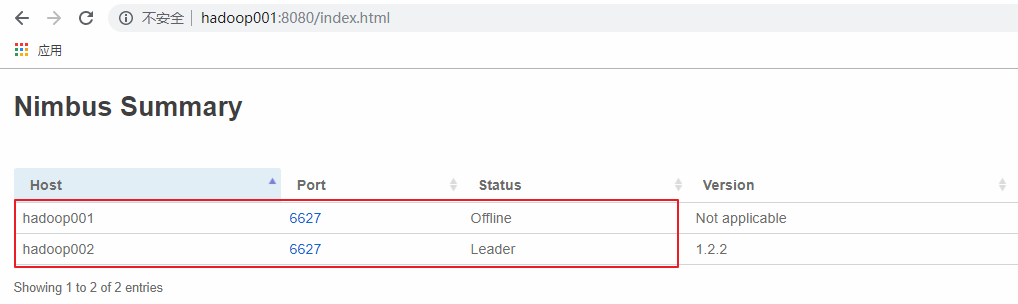
这里手动模拟主Nimbus异常的情况,在hadoop001上使用kill命令杀死Nimbus的线程,此时可以看到hadoop001上的Nimbus已经处于offline状态,而hadoop002上的Nimbus则成为新的Leader。
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Storm —— 集群环境搭建的更多相关文章
- 一:Storm集群环境搭建
第一:storm集群环境准备及部署[1]硬件环境准备--->机器数量>=3--->网卡>=1--->内存:尽可能大--->硬盘:无额外需求[2]软件环境准备---& ...
- Storm 学习之路(四)—— Storm集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm 系列(四)—— Storm 集群环境搭建
一.集群规划 这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus ...
- 大数据处理框架之Strom:Storm集群环境搭建
搭建环境 Red Hat Enterprise Linux Server release 7.3 (Maipo) zookeeper-3.4.11 jdk1.7.0_80 Pyth ...
- storm集群环境搭建
1.环境 Java环境 卸载虚机环境中自带的openJdk,安装sun的jdk,配置环境变量 2.安装storm 下载storm安装包 解压到安装目录,配置环境变量 vi /etc/profile # ...
- centos7:storm集群环境搭建
1.安装storm 下载storm安装包 在线下载 wget http://apache.fayea.com/storm/apache-storm-1.1.1/apache-storm-1.1.1.t ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- 项目进阶 之 集群环境搭建(三)多管理节点MySQL集群
上次的博文项目进阶 之 集群环境搭建(二)MySQL集群中,我们搭建了一个基础的MySQL集群,这篇博客咱们继续讲解MySQL集群的相关内容,同时针对上一篇遗留的问题提出一个解决方案. 1.单管理节点 ...
随机推荐
- Qt浅谈之十八:GraphicsView框架事件处理(有源码下载)
一.简介 GraphicsView支持事件传播体系结构,可以使图元在场景scene中得到提高了已被的精确交互能力.图形视图框架中的事件都是首先由视图进行接收,然后传递给场景,再由场景给相应的图形项. ...
- exponential family distribution(指数族分布)
1. exponential family 给定参数 η,关于 x 的指数族分布定义为如下的形式: p(x∣∣η)=h(x)g(η)exp{ηTu(x)} 其中 x 可以为标量也可以为矢量,可以为离散 ...
- Ueditor 在.net core 中的使用
参考模仿了 https://blog.csdn.net/qq_34220236/article/details/80581811 这篇文章 要注意的是,去ueditor官网下的包,大多不可用. 要自己 ...
- qt的pos()和globalpos()(globalpos是相对于桌面的)
参考:http://www.cppblog.com/izualzhy/archive/2011/03/21/142408.html 原文粘贴: 新建一个窗口程序,然后创建一个QMenu对象.在构造函数 ...
- Java transient关键字【转】
转自:http://www.blogjava.net/fhtdy2004/archive/2009/06/20/286112.htmlVolatile修饰的成员变量在每次被线程访问时,都强迫从主内存中 ...
- delphi xe 之路(14)使用FireMonkeyStyle(一共30篇)
FireMonkey使用Style来控制控件的显示方式. 每个控件都有一个StyleLookup属性,FireMonkey就是通过控件的这个属性来在当前窗体的StyleBook控件中查找匹配的Styl ...
- sql service添加索引
语法:CREATE [索引类型] INDEX 索引名称ON 表名(列名)WITH FILLFACTOR = 填充因子值0~100GO /*实例*/USE 库名GOIF EXISTS (SELECT * ...
- STM32 模拟I2C (STM32F051)
/** ****************************************************************************** * @file i2c simu. ...
- 【转】opencart 源码解析
前台控制程序列表-catalog/controller Catalog|controller|account 会员功能 |—— account.php 会员功能主頁|—— address.php 会员 ...
- 从Windows系统服务获取活动用户的注册表信息(当前活动用户的sessionId. 当前活动用户的 hUserToken)
首先,对“活动用户”的定义是,当前拥有桌面的用户.对于Windows XP及其以后的系统,即使是可以多个用户同时登录了,拥有桌面的也仅仅只有一个. 如果系统级服务调用Windows API来获取注册表 ...