Spark简单介绍,Windows下安装Scala+Hadoop+Spark运行环境,集成到IDEA中
一、前言
近几年大数据是异常的火爆,今天小编以java开发的身份来会会大数据,提高一下自己的层面!
大数据技术也是有很多:
- Hadoop
- Spark
- Flink
小编也只知道这些了,由于Hadoop,存在一定的缺陷(循环迭代式数据流处理:多
并行运行的数据可复用场景效率不行)。所以Spark出来了,一匹黑马,8个月的时间从加入 Apache,直接成为顶级项目!!
选择Spark的主要原因是:
Spark和Hadoop的根本差异是多个作业之间的数据通信问题 : Spark多个作业之间数据
通信是基于内存,而 Hadoop 是基于磁盘。
二、Spark介绍
Spark 是用于大规模数据处理的统一分析引擎。它提供了 Scala、Java、Python 和 R 中的高级 API,以及支持用于数据分析的通用计算图的优化引擎。它还支持一组丰富的高级工具,包括用于 SQL 和 DataFrames 的 Spark SQL、用于 Pandas 工作负载的 Spark 上的 Pandas API、用于机器学习的 MLlib、用于图形处理的 GraphX 和用于流处理的结构化流。
spark是使用Scala语言开发的,所以使用Scala更好!!
三、下载安装
1. Scala下载
点击安装

下载自己需要的版本

点击自己需要的版本:小编这里下载的是2.12.11
点击下载Windows二进制:

慢的话可以使用迅雷下载!
2. 安装
安装就是下一步下一步,记住安装目录不要有空格,不然会报错的!!!
3. 测试安装
win+R输入cmd:
输入:
scala
必须要有JDK环境哈,这个学大数据基本都有哈!!

4. Hadoop下载
一个小技巧:
Hadoop和Spark版本需要一致,我们先去看看spark,他上面名字就带着和他配套的Hadoop版本!!
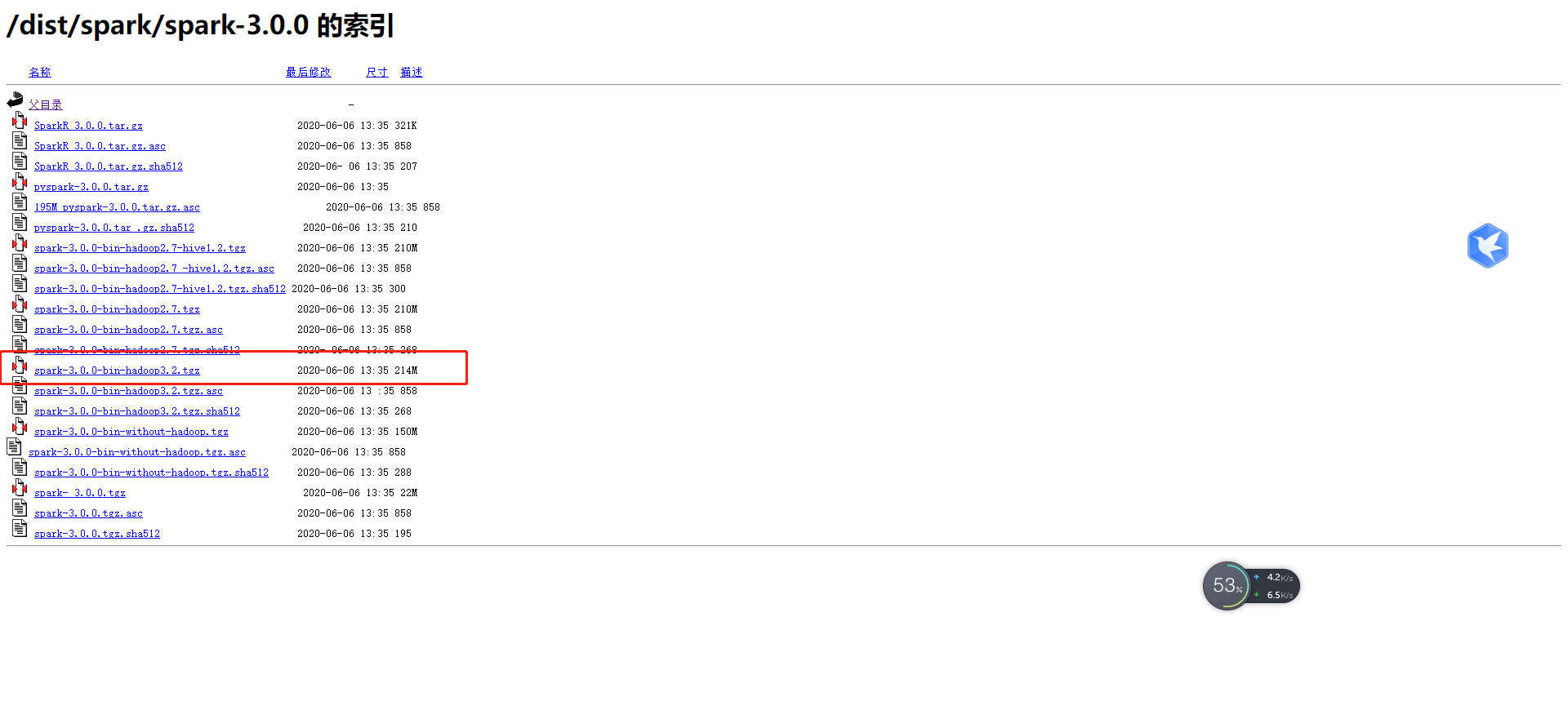
得出我们下载Hadoop的版本为:3.2

5. 解压配置环境
解压到即可使用,为了使用方便,要想jdk一样配置一下环境变量!
新建HADOOP_HOME
值为安装目录:D:\software\hadoop-3.2.1
在Path里添加:%HADOOP_HOME%\bin
cmd输入:hadoop:提示
系统找不到指定的路径。
Error: JAVA_HOME is incorrectly set.
这里先不用管,咱们只需要Hadoop的环境即可!
6. 下载Spark
点击找到历史版本:

点击下载:

7. 解压环境配置
新建:SPARK_HOME:D:\spark\spark-3.3.1-bin-hadoop3
Path添加:%SPARK_HOME%\bin
8. 测试安装
win+R输入cmd:
输入:
spark-shell

四、集成Idea
1. 下载插件
scala
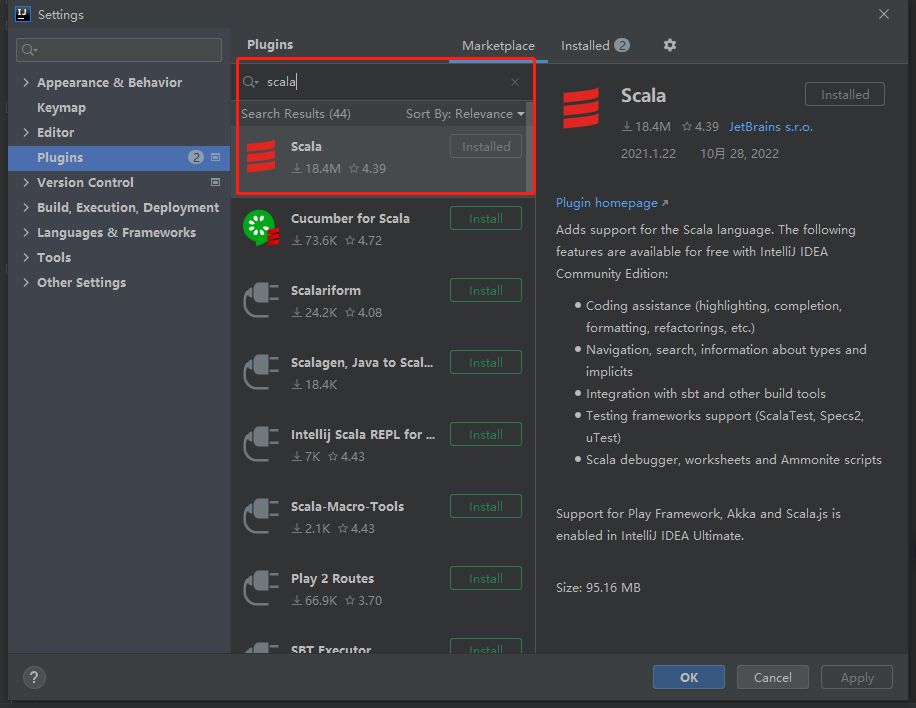
2. 给项目添加Global Libraries
打开配置:

新增SDK

下载你需要的版本:小编这里是:2.12.11

右击项目,添加上scala:

3. 导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
4. 第一个程序


object Test {
def main(args: Array[String]): Unit = {
println("hello")
var sparkConf = new SparkConf().setMaster("local").setAppName("WordCount");
var sc = new SparkContext(sparkConf);
sc.stop();
}
}
5. 测试bug1
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
22/10/31 16:20:35 INFO SparkContext: Running Spark version 3.0.0
22/10/31 16:20:35 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable D:\software\hadoop-3.2.1\bin\winutils.exe in the Hadoop binaries.

原因就是缺少:winutils

把它发放Hadoop的bin目录下:

6. 测试bug2
这个没办法复现,拔的网上的记录:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
22/10/08 21:02:10 INFO SparkContext: Running Spark version 3.0.0
22/10/08 21:02:10 ERROR SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:380)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:120)
at test.wyh.wordcount.TestWordCount$.main(TestWordCount.scala:10)
at test.wyh.wordcount.TestWordCount.main(TestWordCount.scala)
就是这句:A master URL must be set in your configuration
解决方案:
就是没有用到本地的地址
右击项目:

没有环境就添加上:

添加上:
-Dspark.master=local

7. 测试完成
没有error,完美!!

五、总结
这样就完成了,历尽千辛万苦,终于成功。第一次结束差点劝退,发现自己对这个东西还是不懂,后面再慢慢补Scala。先上手感受,然后再深度学习!!
如果对你有用,还请点赞关注下,支持一下一直是小编写作的动力!!
可以看下一小编的微信公众号,和网站文章首发看,欢迎关注,一起交流哈!!微信搜索:小王博客基地

Spark简单介绍,Windows下安装Scala+Hadoop+Spark运行环境,集成到IDEA中的更多相关文章
- 在windows下安装gulp —— 基于 Gulp 的前端集成解决方案(一)
相关连接导航 在windows下安装gulp —— 基于 Gulp 的前端集成解决方案(一) 执行 $Gulp 时发生了什么 —— 基于 Gulp 的前端集成解决方案(二) 常用 Gulp 插件汇总 ...
- windows 下安装nodejs 要怎么设置环境变量
windows 下安装nodejs 了,也安装了npm, 但是有时候切不能直接用request(‘ws’)这一类的东西.我觉得是确实环境变量或其他设置有问题,能否给个完整的设置方案: 要设置两个东西, ...
- Windows下安装Scala
Scala是一种类似Java的纯面向对象的函数式编程语言,由于函数具有明确的确定输入对确定输出的关系,所以适合推理和计算,一切函数都可以看成一系列的计算组成,另外由于Scala函数是没有副作用和透明的 ...
- windows下安装virtualenv并且配置指定环境
下面是在windows下通过virtualenv创建虚拟环境, 包括 : 1. 安装virtualenv(使用pip可直接安装) 2. 使用virtualenv创建指定版本的虚拟环境 3. 进入虚拟环 ...
- 在windows下安装、配置、运行PostgreSQL【转】
安装PostgreSQL 在Windows下的安装就位无脑安装,选择好安装路径就好了,我的安装目录为D:\PostgreSQL\10,需要注意一下几点: 安装过程中需要一个数据库的目录,我的为D:\P ...
- windows下搭建学习objective-c 的运行环境【转载】
对于Iphone开发学习者而言,Object -c 是必修的语言.但是由于苹果的自我封闭的产业链发展模式(从芯片.机器.开发语言.终端产品.服务)的限制,要想开发针对苹果iPhone等产品的应用程序, ...
- 简单介绍Linux下安装Tomcat的步骤
Tomcat是一个免费的开源的Serlvet容器,它是Apache基金会的Jakarta项目中的一个核心项目,由Apache,Sun和其它一些公司及个人共同开发而成.由于有了Sun的参与和支持,最新的 ...
- windows下安装Apache、php、mysql集成环境
一.准备工作 本次安装的版本分别为:apache2.4 .php5.6 . mysql5.7 下载地址为:http://pan.baidu.com/s/1boQNIOn 密码:zarx 二.安装步骤 ...
- Windows下安装配置MinGW GCC调试环境
下载安装文件:Sourceforge 64位系统安装选项记得选x86_64.安装过程中连不上服务器的话也可以选择下载压缩包. 配置环境变量,假设mingw安装目录为C:\mingw-w64\ming ...
随机推荐
- String vs StringBuffer vs StringBuilder
String vs StringBuffer vs StringBuilder 本文翻译自:https://www.digitalocean.com/community/tutorials/strin ...
- 自定义View3-水波纹扩散(仿支付宝咻一咻)实现代码、思想
PS:自定义view篇-水波纹实现 效果:水波纹扩散 场景:雷达.按钮点击效果.搜索等 实现:先上效果图,之前记得支付宝有一个咻一咻,当时就是水波纹效果,实现起来一共两步,第一画内圆,第二画多个外圆, ...
- 第六十二篇:Vue的双向绑定与按键修饰符
好家伙,依旧是vue的基础 1.按键修饰符 假设我们在一个<input>框中输入了12345,我们希望按一下"Esc" 然后删除所有前面输入的内容,这时候,我们会用到按 ...
- ESP8266 RTOS SDK开发
ESP8266 RTOS SDK开发 目录 ESP8266 RTOS SDK开发 一.源码RTOS SDK包的下载和编译 二.固件烧录 1.管脚定义 三.程序例程 ## 1.PWM设置 连接MQTT ...
- 第十二章 Kubernetes的服务暴露插件--traefik
1.前言 之前部署的coredns实现了k8s的服务在集群内可以被自动发现,那么如何使得服务在k8s集群外被使用和访问呢? 使用nodeport星的Service:此方法只能使用iptables模型, ...
- SpringBoot_事务总结
Springboot 事务 1. 打印SQL 日志的两种配置方式 [1]通过配置包的log等级来打印SQL日志,但这种不会打印出事务日志 logging.level.com.grady.mybatis ...
- Mac根据端口找进程id
lsof -i:20942 以后认真的学习一下这个命令
- re.sub()用法
原文链接:https://blog.csdn.net/jackandsnow/article/details/103885422
- [Python]-numpy模块-机器学习Python入门《Python机器学习手册》-01-向量、矩阵和数组
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- Windows服务器限制进程CPU使用率
在Windows server 2012 之前的服务系统 2008和2008 R2中有系统资源管理器System Resource Manager可以管理系统的CPU和内存使用情况.特别对于一些自己开 ...