Scrapy是什么
1.Scrapy是蜘蛛爬虫框架,我们用蜘蛛来获取互联网上的各种信息,然后再对这些信息进行数据分析处理。
2.Scrapy的组成
- 引擎:处理整个系统的数据流处理,出发事务
- 调度器: 接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回
- 下载器: 下载网页内容,并将网页内容返回给蜘蛛
- 蜘蛛: 蜘蛛是主要干活的,用来制定特定域名或网页的解析规则
- 项目管道: 清洗验证存储数据,页面被蜘蛛解析后,被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件: 位于引擎和下载器之间,处理引擎与下载器之间的请求及响应
- 蜘蛛中间件:位于引擎和蜘蛛之间,处理从引擎发送到调度的请求及响应
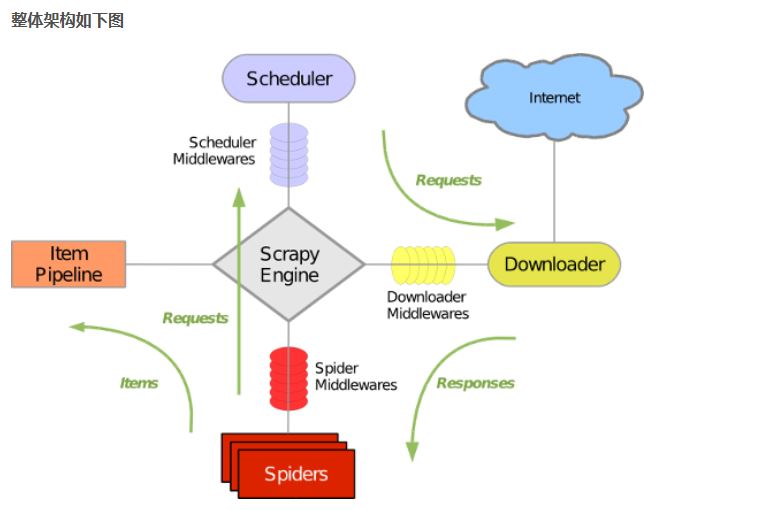
3.工作机制
- 爬取流程
首先从URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,Spider分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回给Scheduler;另一种是需要保存的数据,他们被送到Item Pipeline那里,那是对数据进行后期处理(详细分析,过滤,存储)的地方。另外在数据流动的管道里还可以安装各种中间件,进行必要的处理。
- 数据流程
- 引擎打开一个网站,找到处理该网站的Spider,并向Spider请求第一个要爬取的URL。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器中以request进行调度。
- 引擎向调度器请求下一个要爬取的URL
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件转发给下载器
- 下载完毕后,下载器生成一个该页面的response,并将其通过中间件返回给引擎
- 引擎从下载器中接收到response并通过Spider中间件发送给Spider处理
- Spider处理response并返回爬取到的Item及新的Request给引擎。
- 引擎将爬取到的Item给Item Pipeline,将Request给调度器
- 从第二步重复,直到调度器中没有更多的request,引擎关闭该网站。
Scrapy是什么的更多相关文章
- Scrapy框架爬虫初探——中关村在线手机参数数据爬取
关于Scrapy如何安装部署的文章已经相当多了,但是网上实战的例子还不是很多,近来正好在学习该爬虫框架,就简单写了个Spider Demo来实践.作为硬件数码控,我选择了经常光顾的中关村在线的手机页面 ...
- scrapy爬虫docker部署
spider_docker 接我上篇博客,为爬虫引用创建container,包括的模块:scrapy, mongo, celery, rabbitmq,连接https://github.com/Liu ...
- scrapy 知乎用户信息爬虫
zhihu_spider 此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo,下载这些数据感觉也没什么用,就当为大家学习scrapy提供一个例子吧.代码地 ...
- ubuntu 下安装scrapy
1.把Scrapy签名的GPG密钥添加到APT的钥匙环中: sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 6272 ...
- 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编写一个爬虫 系列随笔汇总 ), BeautifulSoup是一个非常流行的Python网 ...
- Scrapy:为spider指定pipeline
当一个Scrapy项目中有多个spider去爬取多个网站时,往往需要多个pipeline,这时就需要为每个spider指定其对应的pipeline. [通过程序来运行spider],可以通过修改配置s ...
- scrapy cookies:将cookies保存到文件以及从文件加载cookies
我在使用scrapy模拟登录新浪微博时,想将登录成功后的cookies保存到本地,下次加载它实现直接登录,省去中间一系列的请求和POST等.关于如何从本次请求中获取并在下次请求中附带上cookies的 ...
- Scrapy开发指南
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. Scrapy基于事件驱动网络框架 Twis ...
- 利用scrapy和MongoDB来开发一个爬虫
今天我们利用scrapy框架来抓取Stack Overflow里面最新的问题(),并且将这些问题保存到MongoDb当中,直接提供给客户进行查询. 安装 在进行今天的任务之前我们需要安装二个框架,分别 ...
- python3 安装scrapy
twisted(网络异步框架) wget https://pypi.python.org/packages/dc/c0/a0114a6d7fa211c0904b0de931e8cafb5210ad82 ...
随机推荐
- dubbo入门之微服务客户端服务端配置
正常一个服务不会只做客户端或者只做服务端,一般的微服务都是服务与服务相互调用,那么,应该怎么配置呢?接着之前的dubbo入门之helloWorld,我们再改改配置,即可实现正常的微服务架构.与之前相比 ...
- np.tile 函数使用
>>> import numpy>>> numpy.tile([0,0],5)#在列方向上重复[0,0]5次,默认行1次array([0, 0, 0, 0, 0, ...
- Python 基础知识(二)
一.基础数据类型 1.数字int 数字主要是用于计算用的,使用方法并不是很多,就记住一种就可以: #bit_length() 当十进制用二进制表示时,最少使用的位数 # -*- coding:UTF- ...
- tomcat启动报错“Error: Exception thrown by the agent : java.net.MalformedURLException: Local host name unknown: java.net.UnknownHostException: iZ25fsk1ifk: iZ25fsk1ifk”
在启动了Tomcat的时候出现下面的错误,导致启动不了,卡在读日志的状态 Error: Exception thrown by the agent : java.net.MalformedURLExc ...
- 源代码的管理与在eclipse中使用maven进行代码测试
管理源代码的工具 开发历史记录 SVN :集中式的源代码管理工具 通常必须连到公司的服务器上才能正常工作 (提交代码,查看代码的历史记录 查看代码的分支) 在公司中开发项目时 每天必须至少提交(Com ...
- PPTP不使用远程网关访问公网设置
使用PPTP拨号的时候默认使用PPTP远程网关访问公网,通过以下设置可以禁止远程网关访问公网 1,右下角选择网络图标右键-属性 2,选择网络IPv4属性,选择属性 3,点击高级选项 4,在远程网络上使 ...
- codeforces 888A/B/C/D/E - [数学题の小合集]
这次CF不是很难,我这种弱鸡都能在半个小时内连A四道……不过E题没想到还有这种折半+状压枚举+二分的骚操作,后面就挂G了…… A.Local Extrema 题目链接:https://cn.vjudg ...
- easyui-datagrid个人实例
这个实例数据表格的功能,可以实现分页,增删改查功能 1.user.jsp <%@ page language="java" contentType="text/ht ...
- 在浏览器地址栏输入一个URL后回车,将会发生的事情?
https://yq.aliyun.com/articles/20667
- compile time - run-time
php.net Class member variables are called "properties". You may also see them referred to ...