PHP爬取历史天气
PHP爬取历史天气
PHP作为宇宙第一语言,爬虫也是非常方便,这里爬取的是从天气网获得中国城市历史天气统计结果。
程序架构

main.php
<?php
include_once("./parser.php");
include_once("./storer.php");
#解析器和存储器见下文
$parser = new parser();
$storer = new storer();
#获得url列表
$urlList = $parser->getCityList("http://lishi.tianqi.com/");
#依次解析新的URL网站内容,并存到数据库中
foreach($urlList as $url)
{
$data = $parser->getData($url);
$storer->store($data);
}
解析器
解析器提供两个接口,一个是解析主页,获得url列表;另一个是解析每座城市的数据,获得该城市的历史天气数据。
这里使用到的解析库是phpquery,使用JQuery的查询方式,简单高效。
<?php
#借助JQuery库解析
include_once("./phpQuery-onefile.php");
class parser
{
//获取城市url列表
function getCityList($url)
{
//直接在线流下载
phpQuery::newDocumentFile($url);
//第一次选择
$links = pq(".bcity *");
$urlList = [];
foreach ($links as $link) {
#第二次选择
$tmp = pq($link)->find('a')->attr('href');
#过滤组标签
if ($tmp!="#" and $tmp!="") {
#检查url
if(strpos($tmp,"-")==false and filter_var($tmp, FILTER_VALIDATE_URL))
$urlList[] = $tmp; #添加URL列表
}
}
return $urlList;
}
//获取某个城市的历史气候
function getData($url)
{
//直接在线流下载
phpQuery::newDocumentFile($url);
//第一次选择
$text = pq("div .tqtongji p")->text();
#匹配城市
$city = $this->match("/,(.+)共出现/",$text);
#匹配天气
$rainy = $this->match("/雨(\d+)天/",$text);
$cloudy = $this->match("/多云(\d+)天/",$text);
$sunny = $this->match("/晴(\d+)天/",$text);
$overcast = $this->match("/阴(\d+)天/",$text); #为了跟cloudy区分
$snowy = $this->match("/雪(\d+)天/",$text);
#匹配拼音
$pinYin = $this->match("/http:\/\/lishi\.tianqi\.com\/(.*?)\/index\.html/",$url);
$result["url"] = $url;
$result["city"] = $city;
$result["pinYin"] = $pinYin;
$result["rainy"] = $rainy;
$result["cloudy"] = $cloudy;
$result["sunny"] = $sunny;
$result["overcast"] = $overcast;
$result["snowy"] = $snowy;
return $result;
}
#正则解析
function match($rule,$text)
{
preg_match_all($rule, $text, $result);
#有些地区不是所有天气都有
if(count($result[1])==0)
return "0";
return $result[1][0];
}
}
存储器
使用MySQLi接口即可,代码如下:
<?php
class storer
{
public $mysqli;
function __construct()
{
$this->mysqli = new mysqli('localhost', '***', '******', 'phpWeather');
$this->mysqli->query("SET NAMES UTF8");
}
function store($data)
{
$url = $data["url"];
$city = $data["city"];
$pinYin = $data["pinYin"];
$rainy = $data["rainy"];
$cloudy = $data["cloudy"];
$sunny = $data["sunny"];
$overcast = $data["overcast"];
$snowy = $data["snowy"];
#字符串在插入时要添加''来区分
$insertData = "VALUES('$city','$pinYin',$rainy,$cloudy,$sunny,$overcast,$snowy,'$url');";
#sql分开写更加清楚
$sql = "INSERT INTO record(city,pinYin,rainy,cloudy,sunny,overcast,snowy,url)".$insertData;
$isok = $this->mysqli->query($sql);
if($isok)
{
echo "$city 数据添加成功\n";
}
else
{
echo $sql . "\n";
echo "$city 数据添加失败\n";
}
}
function __destruct()
{
$this->mysqli->close();
}
}
?>
爬虫结果
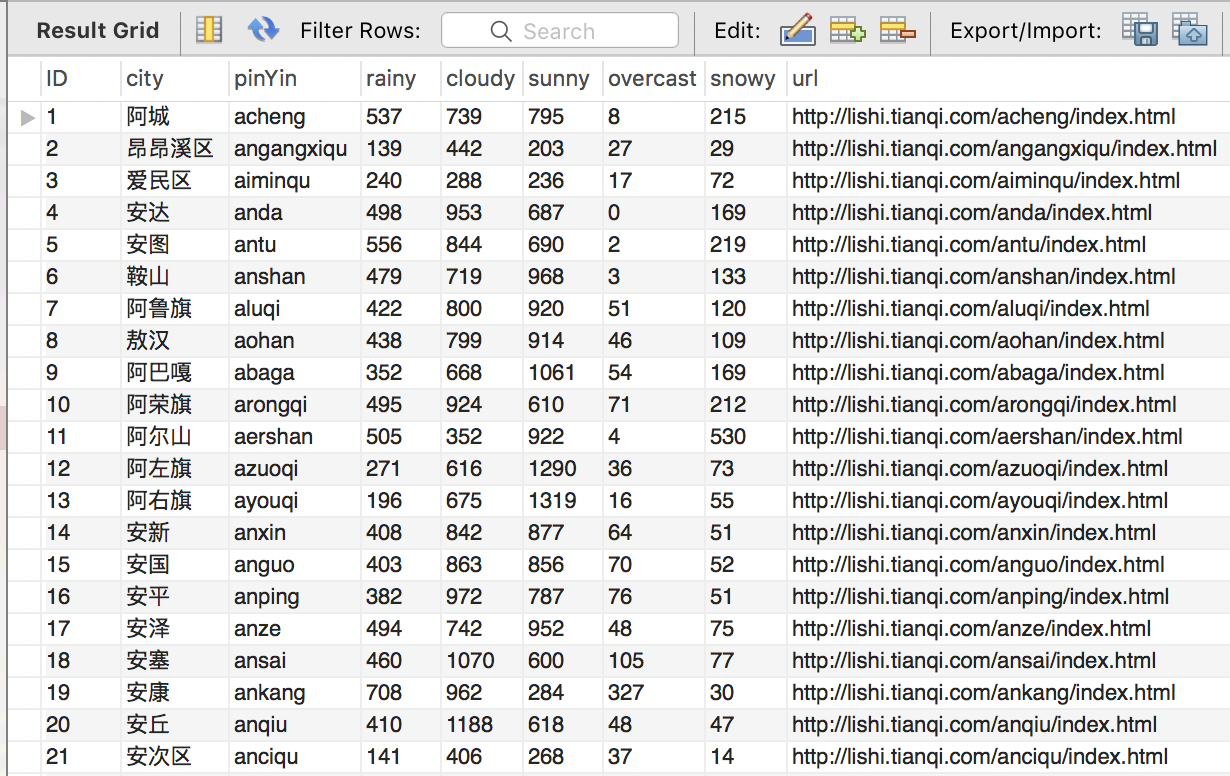
共爬取了3119座城市的从2011年到现在的历史天气,接下来的数据分析以及可视化留到下一篇博客讲述。
PHP爬取历史天气的更多相关文章
- python 爬取历史天气
python 爬取历史天气 官网:http://lishi.tianqi.com/luozhuangqu/201802.html # encoding:utf-8 import requests fr ...
- Scrapy实战篇(五)之爬取历史天气数据
本篇文章我们以抓取历史天气数据为例,简单说明数据抓取的两种方式: 1.一般简单或者较小量的数据需求,我们以requests(selenum)+beautiful的方式抓取数据 2.当我们需要的数据量较 ...
- PyQuery爬取历史天气信息
1.准备工作: 网址:https://lishi.tianqi.com/xian/index.html 爬虫类库:PyQuery,requests 2.网页分析: 红线部分可更改为需要爬取的城市名,如 ...
- python爬虫实战(六)--------新浪微博(爬取微博帐号所发内容,不爬取历史内容)
相关代码已经修改调试成功----2017-4-13 详情代码请移步我的github:https://github.com/pujinxiao/sina_spider 一.说明 1.目标网址:新浪微博 ...
- Python爬取中国天气网
Python爬取中国天气网 基于requests库制作的爬虫. 使用方法:打开终端输入 “python3 weather.py 北京(或你所在的城市)" 程序正常运行需要在同文件夹下加入一个 ...
- python3爬取墨迹天气并发送给微信好友,附源码
需求: 1. 爬取墨迹天气的信息,包括温湿度.风速.紫外线.限号情况,生活tips等信息 2. 输入需要查询的城市,自动爬取相应信息 3. 链接微信,发送给指定好友 思路比较清晰,主要分两块,一是爬虫 ...
- 初识python 之 爬虫:爬取中国天气网数据
用到模块: 获取网页并解析:import requests,html5lib from bs4 import BeautifulSoup 使用pyecharts的Bar可视化工具"绘制图表& ...
- python爬取中国天气网站数据并对其进行数据可视化
网址:http://www.weather.com.cn/textFC/hb.shtml 解析:BeautifulSoup4 爬取所有城市的最低天气 对爬取的数据进行可视化处理 按温度对城市进行排 ...
- scrapy实例:爬取中国天气网
1.创建项目 在你存放项目的目录下,按shift+鼠标右键打开命令行,输入命令创建项目: PS F:\ScrapyProject> scrapy startproject weather # w ...
随机推荐
- config.GetSection(key)编译不通过
要安装这个版本
- rabbitmq的安装与使用
1.RabbitMQ的安装,rabbitmq为erlang语言开发,所以先安装erlang语言开发包,现在电脑一般都是64位的,所以下载64位的都行了.红色框可以选择版本,箭头选择64位的进行下载.下 ...
- dom操作节点之常用方法
DOM:获取节点:{1. document.getElementById (元素id):通过元素id找到节点2. document.getElementsByClassName (元素类名classN ...
- Java集合中List,Set以及Map等集合体系详解(史上最全)
https://blog.csdn.net/zhangqunshuai/article/details/80660974
- Note for "Some Remarks on Writing Mathematical Proofs"
John M. Lee is a famous mathematician, who bears the reputation of writing the classical book " ...
- [转]xshell使用技巧
https://yq.aliyun.com/articles/44721 xshell是我用过的最好用的ssh客户端工具,没有之一.这个软件完全免费,简单易用,可以满足通过ssh管理linux vps ...
- Python学习(四) —— 编码
一.枚举 enumerate,for i in enumerate(可迭代对象),返回元组,内容是(序列号,可迭代的每一个元素) for i,j in enumerate(可迭代对象,开 ...
- CF552 E. Two Teams
题意:给出一串n个数 为1-n的乱序 一共有两个教练 教练一的队伍是1队 二是二队 教练一选择 当前队列中剩余人数的最大序号 将其和左边k个人 和右边k个人 变为一队 如此反复直到所有人 ...
- day 69 orm操作之表关系,多对多,多对一(wusir总结官网的API)
对象 关系 模型 wusir博客地址orm官网API总结 django官网orm-API orm概要: ORM 跨表查询 class Book(models.Model): title = mod ...
- TensorFlow卷积层-函数
函数1:tf.nn.conv2d是TensorFlow里面实现卷积的函数,实际上这是搭建卷积神经网络比较核心的一个方法 函数原型: tf.nn.conv2d(input,filter,strides, ...