PyQuery爬取历史天气信息
1.准备工作:
网址:https://lishi.tianqi.com/xian/index.html
爬虫类库:PyQuery,requests
2.网页分析:

红线部分可更改为需要爬取的城市名,如:beijing

红框选中部分即为我们所需要爬取的每个月份的信息. 目测应该是ui li,使用Chrome F12 查看下源代码
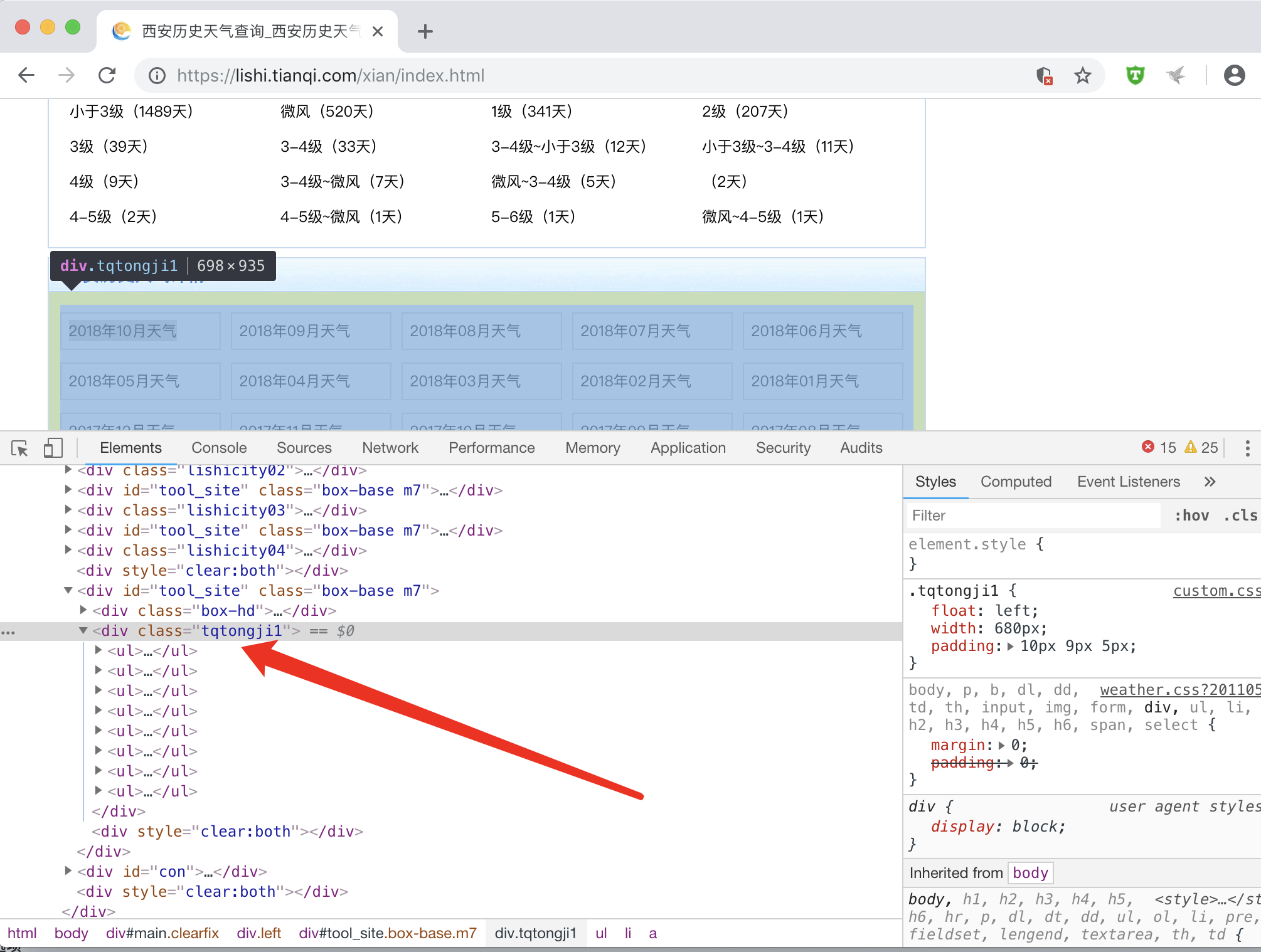
PyQuery的css 选择器可以起床了..
莫慌莫慌。在瞅瞅具体月份点击进入后的页面效果
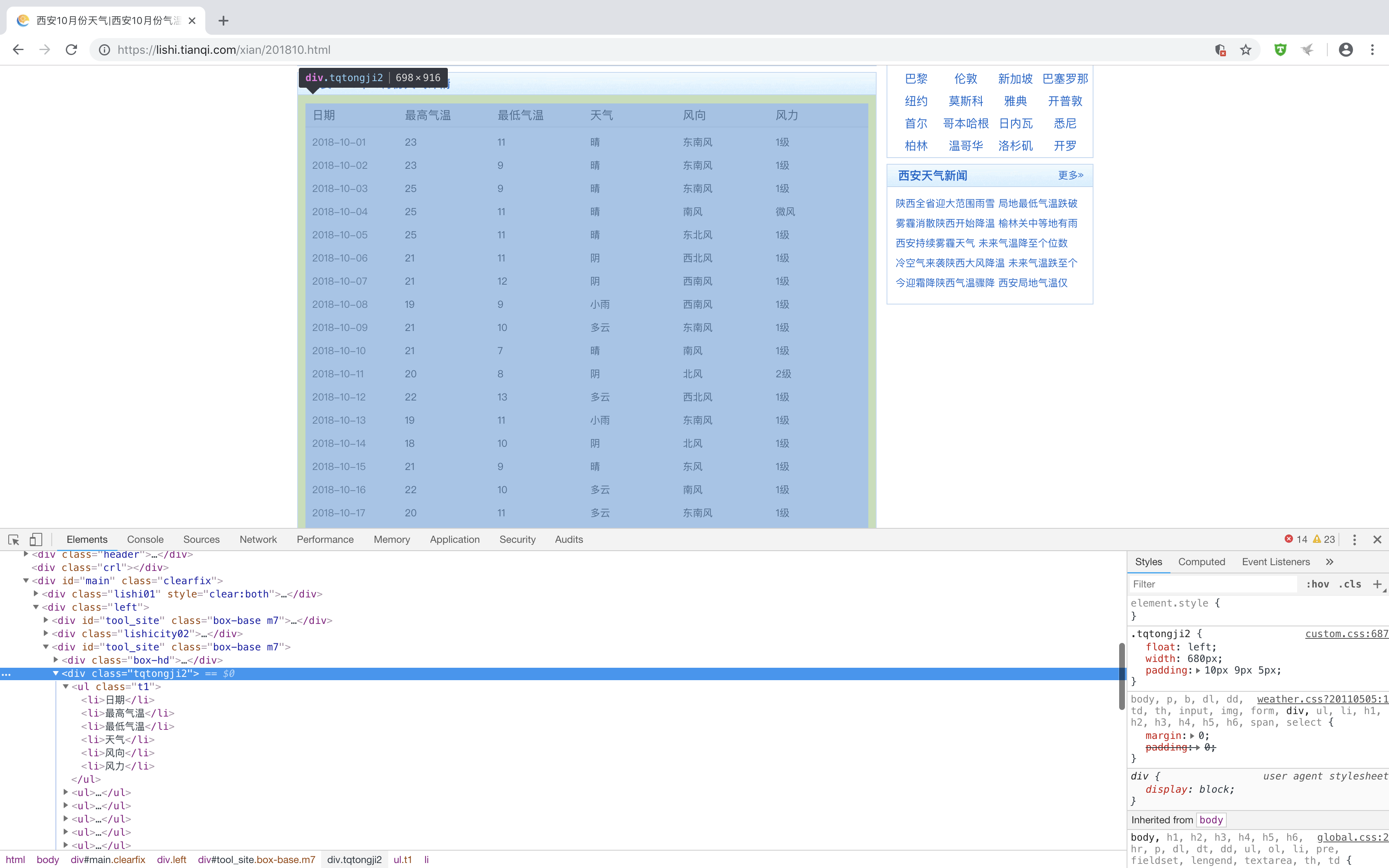
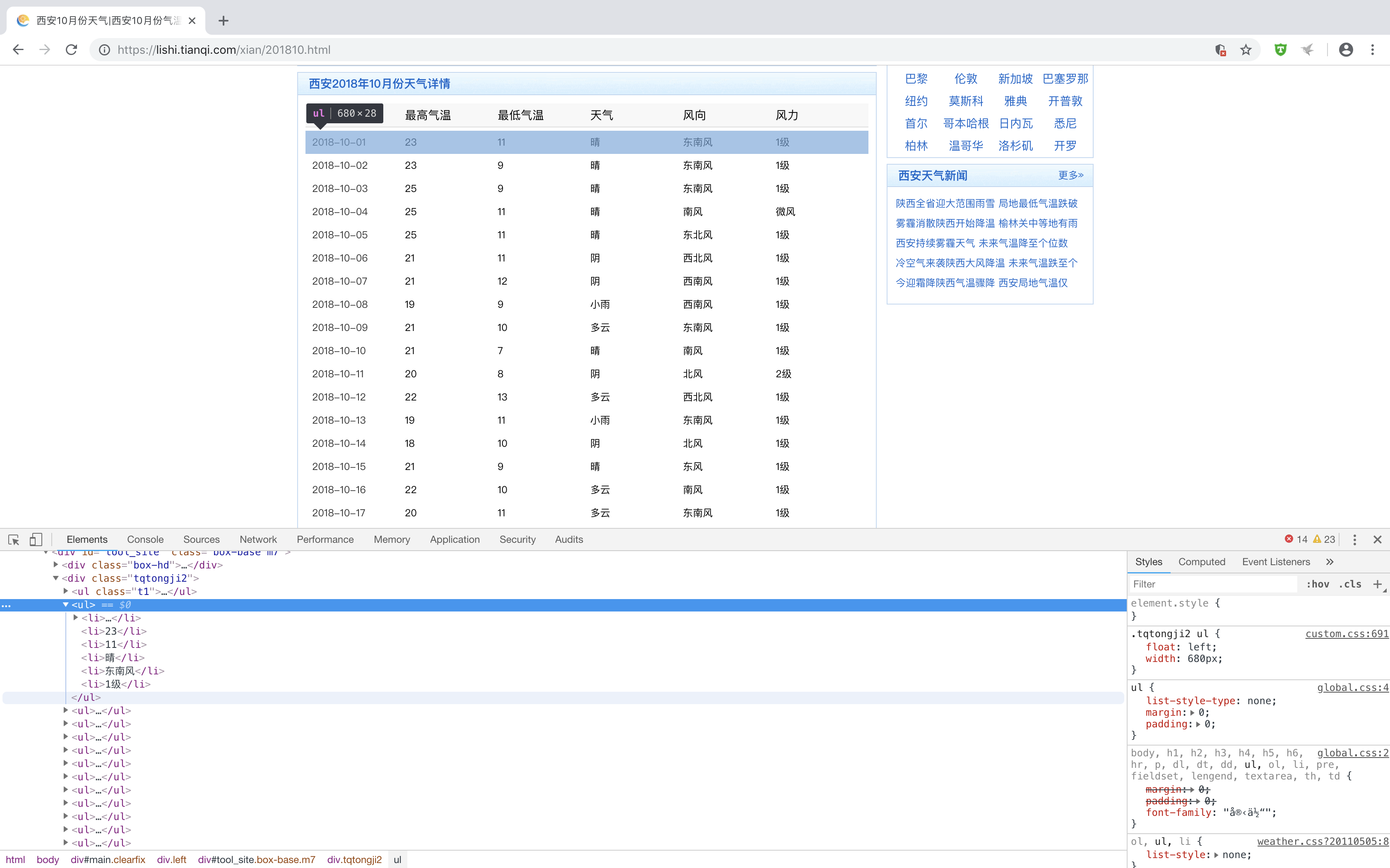
所有的具体每一天的天气信息都被包裹在ul li..
PyQuery.. 开工..
# 获取所有的月份的a标签连接。
def get_html():
links = []
url = 'https://lishi.tianqi.com/xian/index.html'
r1 = requests.get(url,headers)
html_doc = pq(r1.text)
ul = html_doc('.tqtongji1 > ul:nth-child(1)')
lis = ul('li').items()
for li in lis:
a = li('a')
links.append(a.attr('href'))
return links
# 获取详细页的具体天气信息
def get_detail(url):
r1 = requests.get(url,headers)
html_doc = pq(r1.text)
uls = html_doc('.tqtongji2').find('ul')
lis = uls.items('li')
list = []
l = '.'.join(li.text() for li in lis).split('.')
# 由于标题信息只有['日期', '最高气温', '最低气温', '天气', '风向', '风力']所以需要字符串截取
for i in range(len(l)):
if i%6 == 0:
temp = l[i:i+5]
list.append(temp)
return list
# 保存至weather.csv
def save_to_csv(data):
with open('weather.csv','a') as csv_file:
writer = csv.writer(csv_file)
for row in data:
writer.writerow(row)
考虑到需要源代码的小伙伴, 已上传至github.. https://github.com/shinefairy/spider/
git clone https://github.com/shinefairy/spider
end~
PyQuery爬取历史天气信息的更多相关文章
- PHP爬取历史天气
PHP爬取历史天气 PHP作为宇宙第一语言,爬虫也是非常方便,这里爬取的是从天气网获得中国城市历史天气统计结果. 程序架构 main.php <?php include_once(". ...
- python 爬取历史天气
python 爬取历史天气 官网:http://lishi.tianqi.com/luozhuangqu/201802.html # encoding:utf-8 import requests fr ...
- Scrapy实战篇(五)之爬取历史天气数据
本篇文章我们以抓取历史天气数据为例,简单说明数据抓取的两种方式: 1.一般简单或者较小量的数据需求,我们以requests(selenum)+beautiful的方式抓取数据 2.当我们需要的数据量较 ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- python爬取豆瓣视频信息代码
目录 一:代码 二:结果如下(部分例子) 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quote ...
- 一起学爬虫——使用selenium和pyquery爬取京东商品列表
layout: article title: 一起学爬虫--使用selenium和pyquery爬取京东商品列表 mathjax: true --- 今天一起学起使用selenium和pyquery爬 ...
- python爬虫实战(六)--------新浪微博(爬取微博帐号所发内容,不爬取历史内容)
相关代码已经修改调试成功----2017-4-13 详情代码请移步我的github:https://github.com/pujinxiao/sina_spider 一.说明 1.目标网址:新浪微博 ...
- python3爬取墨迹天气并发送给微信好友,附源码
需求: 1. 爬取墨迹天气的信息,包括温湿度.风速.紫外线.限号情况,生活tips等信息 2. 输入需要查询的城市,自动爬取相应信息 3. 链接微信,发送给指定好友 思路比较清晰,主要分两块,一是爬虫 ...
- 初识python 之 爬虫:爬取中国天气网数据
用到模块: 获取网页并解析:import requests,html5lib from bs4 import BeautifulSoup 使用pyecharts的Bar可视化工具"绘制图表& ...
随机推荐
- idea 快捷键汇总
1.IDEA常用快捷键 Alt+回车 导入包,自动修正 Ctrl+N 查找类 Ctrl+Shift+N 查找文件 Ctrl+Alt+L 格式化代码 Ctrl+Alt+O 优化导入的类和包 Alt+In ...
- Windows Server2003 关闭 关机信息、开机ctrl+alt+del
取消CTRL+ALT+DEL win+R 或从"开始"打开"运行",输入gpedit.msc打开"组策略编辑器",依次展开"计算机 ...
- Tcp协议介绍
前情提要:根据域名建立tcp链接之前要做两件事情,1 根据arp协议找到网管mac地址 2 通过dns服务器解析出域名的Ip地址,解析出域名的Ip地址之后就可以建立tcp链接了. tcp协议三个特点: ...
- 洛谷 P1546 最短网络 Agri-Net(最小生成树)
题目链接 https://www.luogu.org/problemnew/show/P1546 说过了不复制内容了 显然是个最小生成树. 解题思路 prim算法 Kruskal算法 prim算法很直 ...
- 【题解】Sigitseeing Tour
题目大意 有一张$n$个结点,$m$条混合边的图($1 \leq n \leq 200$,$1 \leq m \leq 1000$),求这张图是否存在欧拉回路. 题解 因为有混合边,所以我们要先给无向 ...
- hdu4352 XHXJ's LIS(数位dp)
题目传送门 XHXJ's LIS Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- 71.Edit Distance(编辑距离)
Level: Hard 题目描述: Given two words word1 and word2, find the minimum number of operations required ...
- ApacheHttpServer出现启动报错:the requested operation has failed解决办法
转自:https://www.jb51.net/article/21004.htm 原因一:80端口占用 例如IIS,另外就是迅雷.我的apache服务器就是被迅雷害得无法启用! 原因二:软件冲突 装 ...
- Mac版Navicat Premium激活教程
工具: Navicat Premium12.0.20 安装包 下载注册机工具包 链接:https://pan.baidu.com/s/1NS8gk780ds1Xn-zHrSIzIw 密码:dvke ...
- rpc - rpc 程序号数据库
SYNOPSIS /etc/rpc DESCRIPTION rpc 文件列出了rpc 程序的可读名, 可以此代替rpc 程序号. 每行包含如下信息: 运行rpc 程序的服务名 rpc 程序号 别名 各 ...