spark中groupByKey与reducByKey
【译】避免使用GroupByKey
by:leotse
译文
让我们来看两个wordcount的例子,一个使用了reduceByKey,而另一个使用groupByKey:
1 |
val words = Array("one", "two", "two", "three", "three", "three")
|
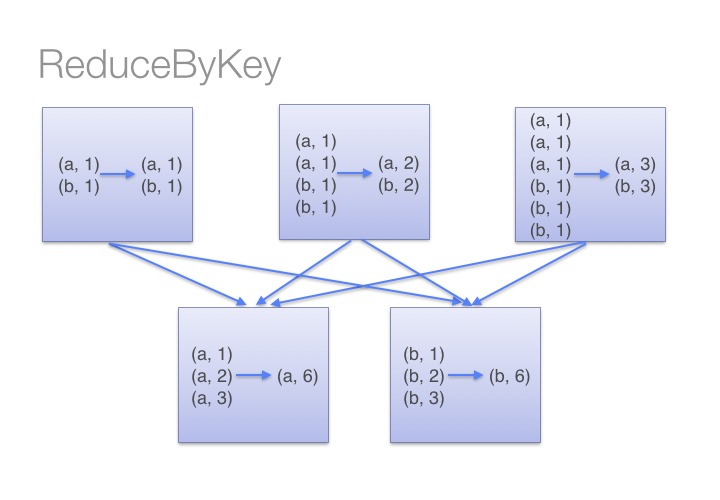
上面两个函数所得到的结果都是正确的,但是当数据集很大时,使用了reduceByKey的例子表现更佳。这是因为在shuffle输出的数据前,Spark会Combine每一个partition上具有相同key的输出结果。
看下图我们就能理解reduceByKey的工作流程。我们注意到同一台机器上数据shuffle之前,相同key的数据(通过调用传入reduceByKey的lambda函数)Combine在一起的,然后再一次调用这个lambda函数去reduce来自各个partition的全部值,从而得到最终的结果。
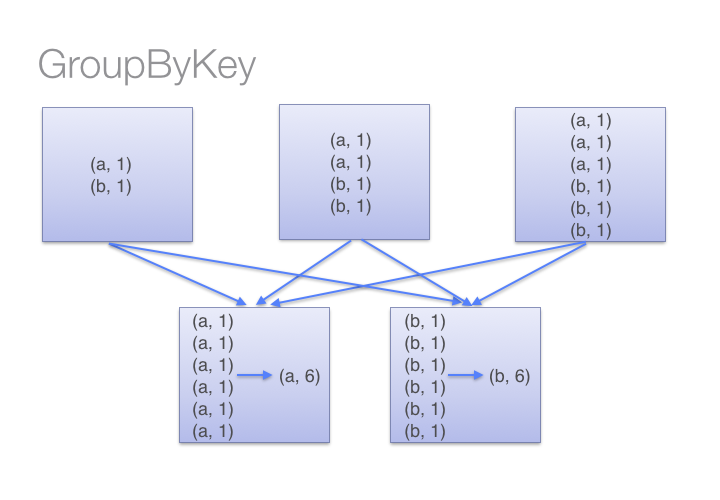
另一方面,当调用groupByKey的时候,所有的键值对都会进行shuffle,这将增加很多无谓的数据进行网络传输。
为了确定哪台机器将接受Shuffle后的键值对,Spark会针对该键值对数据的key调用一个分区函数。当某一台executor机器上的内存不足以保存过多的Shuffle后数据时,Spark就会溢写数据到磁盘上。然而,这种溢写磁盘会一次性将一个key的全部键值对数据写入磁盘,因此如果一个key拥有过多键值对数据——多到内存放不下时,将会抛出Out Of Memory异常。在之后发布的Spark中将会更加优雅地处理这种情况,使得这个job仍会继续运行,但是我们仍然需要避免(使用groupByKey)。当Spark需要溢写磁盘的时候,它的性能将受到严重影响。
如果你有一个非常大的数据集,那么reduceByKey和groupByKey进行shuffle的数据量之间的差异将会更加夸张。
下面是一些你可以用来替代groupByKey的函数:
1)当你在combine数据但是返回的数据类型因输入值的类型而异时,你可以使用combineByKey;
2)如果key使用到结合函数和“零值”,你可以用foldByKey函数合并value;
spark中groupByKey与reducByKey的更多相关文章
- Spark 中 GroupByKey 相对于 combineByKey, reduceByKey, foldByKey 的优缺点
避免使用GroupByKey 我们看一下两种计算word counts 的方法,一个使用reduceByKey,另一个使用 groupByKey: val words = Array("on ...
- Spark中groupByKey、reduceByKey与sortByKey
groupByKey把相同的key的数据分组到一个集合序列当中: [("hello",1), ("world",1), ("hello",1 ...
- 在Spark中尽量少使用GroupByKey函数(转)
原文链接:在Spark中尽量少使用GroupByKey函数 为什么建议尽量在Spark中少用GroupByKey,让我们看一下使用两种不同的方式去计算单词的个数,第一种方式使用reduceByKey ...
- Spark中的编程模型
1. Spark中的基本概念 Application:基于Spark的用户程序,包含了一个driver program和集群中多个executor. Driver Program:运行Applicat ...
- 关于Spark中RDD的设计的一些分析
RDD, Resilient Distributed Dataset,弹性分布式数据集, 是Spark的核心概念. 对于RDD的原理性的知识,可以参阅Resilient Distributed Dat ...
- Spark中的键值对操作-scala
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- Spark中的键值对操作
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- 【Spark篇】--Spark中的宽窄依赖和Stage的划分
一.前述 RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖. Spark中的Stage其实就是一组并行的任务,任务是一个个的task . 二.具体细节 窄依赖 父RDD和子RDD parti ...
- 020 Spark中分组后的TopN,以及Spark的优化(重点)
一:准备 1.源数据 2.上传数据 二:TopN程序编码 1.程序 package com.ibeifeng.bigdata.spark.core import java.util.concurren ...
随机推荐
- amazeui 后台模板
<!doctype html> <html class="no-js"> <head> <meta charset="utf-8 ...
- KeyTweak(笔记本键盘设置工具) V2.20 中文版
软件名称: KeyTweak(笔记本键盘设置工具)软件语言: 简体中文授权方式: 免费软件运行环境: Win 32位/64位软件大小: 50KB图片预览: 软件简介:KeyTweak 通过设置系统的注 ...
- 元素NULL判断
元素取值val() val()方法主要用来获取form元素的值像input select textarea.在对select取值的时候当没有option被选定时val()会返回null,至少一个opt ...
- hdu5573 二叉树找规律,二进制相关
input T 1<=T<=100 n k 1<=n<=1e9 n<=2^k<=2^60 output 从1走到第k层,下一层的数是上一层的数×2或者×2+1,每 ...
- 搭建Linux3.4.2内核编辑环境
(1)准备工作:1. 准备虚拟机2.安装工具链sudo tar xjf arm-linux-gcc-4.3.2.tar.bz2 -C /设置环境变量:sudo vi /etc/environment ...
- Android依赖注入:Google Guice on Android的使用及相关资源
本文转自:http://blog.csdn.net/sangming/article/details/8878104 RoboGuice 使用谷歌自己的Guice库,给Android带来了简单和易用的 ...
- 用js 将long类型转换成日期格式
//扩展Date的format方法 Date.prototype.format = function (format) { var o = { "M+": this.getMont ...
- windows 装 centos
windows下压缩一下空间 直接装centos 找到分配给linux的/boot目录,然后修改grub/menu.lst文件,更换一下位置即可
- Why isn't sizeof for a struct equal to the sum of sizeof of each member?
check here. Basically the compiler will insert unused memory into a structure so that data members a ...
- js纯ajax
var XMLHttpReq; function createXMLHttpRequest() { try { XMLHttpReq = new ActiveXObject("Msxml2. ...