用python+selenium抓取豆瓣读书中最受关注图书并按评分排序
抓取豆瓣读书中的(http://book.douban.com/)最受关注图书,按照评分排序,并保存至txt文件中,需要抓取书籍的名称,作者,评分,体裁和一句话评
方法一:
#coding=utf-8
from selenium import webdriver
from time import sleep
class DoubanPopularBook:
def __init__(self):
self.dr = webdriver.Chrome()
self.popular_books_list = self.get_douban_popular_books()
def get_douban_popular_books(self):
self.dr.get('https://book.douban.com/')
sleep(3)
popular_books_list = [] #定义一个空list用于存放获取的书籍信息
i = 0
while i < 10: #总共10本书
book_info = self.dr.find_elements_by_css_selector("[class='list-col list-col2 list-summary s']>li")[i].text #通过css用class属性和标签li组合来获取书籍所有文本信息
popular_books_list.append(book_info.split('\n')) #向空list追加书籍信息用并换行符隔开
i += 1 #每本书籍的li标签间隔为1
#popular_books_list.sort(key=lambda x:float(x[1][0:3]), reverse=True) #用sort中key方法根据书籍评分从高到低进行排序
popular_books_list = sorted(popular_books_list, key=lambda book:float(book[1][0:3]), reverse=True)
return popular_books_list
def get_popular_books_rank_file(self):
self.file_title = '豆瓣最受关注图书榜之评分排行'
self.file = open(self.file_title + '.txt', 'wb')
for item in self.popular_books_list:
separate_line = '~~~~~~~~~~~~~~~~~~~~~~~~\n'
self.file.write(separate_line.encode('utf-8'))
self.file.write(('书籍名称:'+item[0]+'\n').encode('utf-8'))
self.file.write(('评分:'+item[1]+'\n').encode('utf-8'))
self.file.write((item[2]+'\n').encode('utf-8'))
self.file.write(('体裁:'+item[3]+'\n').encode('utf-8'))
if item[4] == '有电子书':
self.file.write(('一句话评论:'+item[5]+'\n').encode('utf-8'))
else:
self.file.write(('一句话评论:'+item[4]+'\n').encode('utf-8'))
self.file.close()
def quit(self):
self.dr.quit()
if __name__ == '__main__':
popular_books = DoubanPopularBook()
popular_books.get_popular_books_rank_file()
popular_books.quit()
方法二:
#coding=utf-8
from selenium import webdriver
from time import sleep
class DoubanPopularBook:
def __init__(self):
self.dr = webdriver.Chrome()
self.popular_books_list = self.get_douban_popular_books()
def get_douban_popular_books(self):
self.dr.get('https://book.douban.com/')
sleep(3)
popular_books_list = [] #定义一个空list用于存放获取的书籍信息
i = 0
while i < 10: #总共10本书
book_name = self.dr.find_elements_by_xpath("//h4[@class='title']/a")[i].text #定位书籍名称
book_grade = self.dr.find_elements_by_css_selector('.average-rating')[i].text #定位评分
book_auther = self.dr.find_elements_by_xpath("//p[@class='author']")[i].text #定位作者
book_genre = self.dr.find_elements_by_css_selector('.book-list-classification')[i].text #定位体裁
book_comment = self.dr.find_elements_by_css_selector('.reviews')[i].text #定位一句话评论
popular_books_list.append([book_name, book_grade, book_auther, book_genre, book_comment]) #向空list追加书籍信息
i += 1 #每本书籍间隔为1
popular_books_list = sorted(popular_books_list, key=lambda x:float(x[1]), reverse=True) #用sorted方法按评分从高到低排序
return popular_books_list
def get_popular_books_rank_file(self):
self.file_title = '豆瓣最受关注图书榜之评分排行'
self.file = open(self.file_title + '.txt', 'wb')
for item in self.popular_books_list:
separate_line = '~~~~~~~~~~~~~~~~~~~~~~~~\n'
self.file.write(separate_line.encode('utf-8'))
self.file.write(('书籍名称:'+item[0]+'\n').encode('utf-8'))
self.file.write(('评分:'+item[1]+'\n').encode('utf-8'))
self.file.write((''+item[2]+'\n').encode('utf-8'))
self.file.write(('体裁:'+item[3]+'\n').encode('utf-8'))
self.file.write(('一句话评论:'+item[4]+'\n').encode('utf-8'))
self.file.close()
def quit(self):
self.dr.quit()
if __name__ == '__main__':
popular_books = DoubanPopularBook()
popular_books.get_popular_books_rank_file()
popular_books.quit()
方法三:
# coding=utf-8
from selenium import webdriver
import unittest
from time import sleep
class DoubanBooks(unittest.TestCase):
def setUp(self):
self.dr = webdriver.Chrome()
self.popular_books_list = self.get_douban_popular_books()
self.books = self.get_popular_books_rank_file()
def get_douban_popular_books(self):
self.dr.get("https://book.douban.com/")
sleep(5)
book_name = self.dr.find_elements_by_xpath("//h4[@class='title']/a") #定位书名
book_author = self.dr.find_elements_by_xpath("//p[@class='author']") #定位作者
book_grade = self.dr.find_elements_by_xpath("//span[@class='average-rating']") #定位评分
book_genre = self.dr.find_elements_by_xpath("//p[@class='book-list-classification']") #定位体裁
book_comment = self.dr.find_elements_by_xpath("//p[@class='reviews']") #定位评论
douban_most_popular_book_list = [] #定义空list用来放置书籍信息
x = 0
while x < len(book_name): #数目为书名的个数
douban_most_popular_book_list.append([book_name[x].text, book_author[x].text, book_grade[x].text, book_genre[x].text,book_comment[x].text])
x += 1
douban_most_popular_book_list = sorted(douban_most_popular_book_list, key=lambda book_grade: book_grade[2],reverse=True) #用sorted方法按评分从高到低排名
return douban_most_popular_book_list
def get_popular_books_rank_file(self):
self.file_title = '豆瓣最受关注图书榜之评分排行'
self.file = open(self.file_title + '.txt', 'wb')
for item in self.popular_books_list:
separate_line = '~~~~~~~~~~~~~~~~~~~~~~~~\n' #分隔符
self.file.write(separate_line.encode('utf-8'))
self.file.write(('书籍名称:'+item[0]+'\n').encode('utf-8'))
self.file.write((''+item[1]+'\n').encode('utf-8'))
self.file.write(('评分:'+item[2]+'\n').encode('utf-8'))
self.file.write(('体裁:'+item[3]+'\n').encode('utf-8'))
self.file.write(('一句话评论:'+item[4]+'\n').encode('utf-8'))
self.file.close()
def test_books(self):
pass
print("获取完毕")
def tearDown(self):
self.dr.quit()
if __name__ == "__main__":
unittest.main()
网页如下:
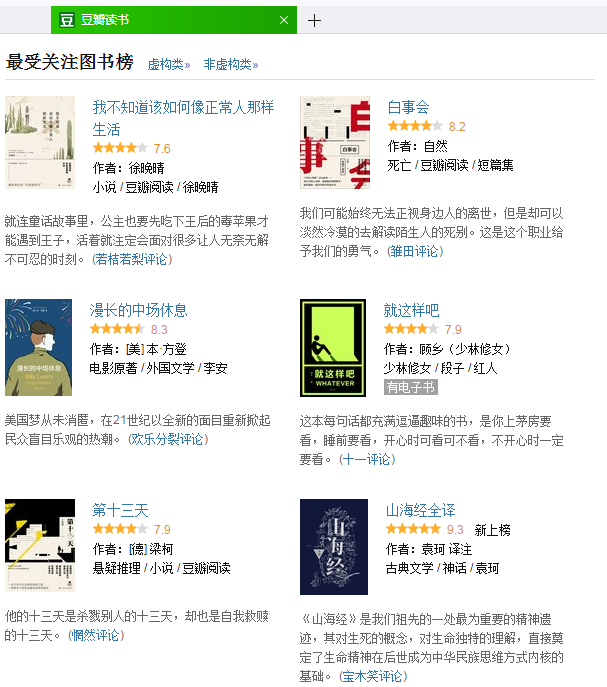

生成txt效果如下:

用python+selenium抓取豆瓣读书中最受关注图书并按评分排序的更多相关文章
- 用python+selenium抓取豆瓣电影中的正在热映前12部电影并按评分排序
抓取豆瓣电影(http://movie.douban.com/nowplaying/chengdu/)中的正在热映前12部电影,并按照评分排序,保存至txt文件 #coding=utf-8 from ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- 哪吒票房超复联4,100行python代码抓取豆瓣短评,看看网友怎么说
<哪吒之魔童降世>这部国产动画巅峰之作,上映快一个月时间,票房口碑双丰收. 迄今已有超一亿人次观看,票房达到42.39亿元,超过复联4,跻身中国票房纪录第三名,仅次于<战狼2> ...
- 用python+selenium抓取微博24小时热门话题的前15个并保存到txt中
抓取微博24小时热门话题的前15个,抓取的内容请保存至txt文件中,需要抓取排行.话题和阅读数 #coding=utf-8 from selenium import webdriver import ...
- 用python+selenium抓取知乎今日最热和本月最热的前三个问题及每个问题的首个回答并保存至html文件
抓取知乎今日最热和本月最热的前三个问题及每个问题的首个回答,保存至html文件,该html文件的文件名应该是20160228_zhihu_today_hot.html,也就是日期+zhihu_toda ...
- PHP抓取豆瓣读书爬虫代码
<?php//演示地址 http://asizu.sinaapp.com/reptile_douban.php//数据量不是特别大,没有写抓完数据便停止. 喜欢的朋友拿去自己改改就好了 head ...
- python爬虫抓取豆瓣电影
抓取电影名称以及评分,并排序(代码丑炸) import urllib import re from bs4 import BeautifulSoup def get(p): t=0 k=1 n=1 b ...
- Python爬虫爬取豆瓣读书
一,准备工作. 工具:win10+Python3.6 爬取目标:爬取图中红色方框的内容. 原则:能在源码中看到的信息都能爬取出来. 信息表现方式:CSV转Excel. 二,具体步骤. 先给出具体代码吧 ...
- Python抓取豆瓣电影top250!
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:404notfound 一直对爬虫感兴趣,学了python后正好看到 ...
随机推荐
- 作业调度框架 Quartz 学习笔记(三) -- Cron表达式 (转载)
前面两篇说的是简单的触发器(SimpleTrigger) , SimpleTrigger 只能处理简单的事件出发,如果想灵活的进行任务的触发,就要请出 CronTrigger 这个重要人物了. Cro ...
- Spring Framework的核心:IOC容器的实现
2.1 Spring IoC容器概述 2.1.1 IoC容器和依赖反转模式 依赖反转的要义,如果合作对象的引用或依赖关系的管理由具体对象来完成,会导致代码的高度耦合和可测性的降低.依赖控制反转的实 ...
- linux桌面的安装
在CentOS 7中提供了两种桌面"GNOME DESKTOP" 和 "KDE Plasa Workspaces",我们以安装"GNOME DESKT ...
- CentOS 7 64位的安装流程
若出现以下不支持虚拟机的问题: 表示虚拟机检测到CPU支不支持虚拟化,要去BIOS里设置虚拟化技术设置为enabled:重启电脑-按"F1或Fn+F1"-进入BIOS主界面-移至S ...
- (转)客户端触发Asp.net中服务端控件事件
第一章. Asp.net中服务端控件事件是如何触发的 Asp.net 中在客户端触发服务端事件分为两种情况: 一. WebControls中的Button 和HtmlControls中的Type为su ...
- 当在浏览器输入一个url访问后发生了什么
首先根据DNS获取该url的ip地址,ip地址的获取可能通过本地缓存,路由缓存等得到. 然后在网络层通过路由选择查找一条可达路径,最后利用tcp/ip协议来进行数据的传输. 其中在传输层将信息添加源端 ...
- mac brew mysql 启动之后报错
打开电脑 链接mysql 发现报错,连不上,应该是没自启动, 之前一直用windows电脑,就用mysql start 准备启动下,发现报错, p.p1 { margin: 0.0px 0.0px 0 ...
- 火狐和IE浏览器的兼容问题汇总
1.window.event code=(navigator.appName="Netscape")?event.which:event.keycode; 2.event.x mx ...
- javascript的实践
jQuery增强了css的选择器功能,是一个简洁快速的脚本库,能够使用短小的代码实现复杂的网页预览效果.如实现表格奇偶行异色 <script language="javascript& ...
- iOS学习之SKTagView的使用
SKTagView是一款支持自动布局的标签tag. 特性: -流式展示标签 -可以配置标签的颜色.事件.间隔.外边距等 -支持Auto layout -可以在UITableViewCell中良好展示 ...