入门大数据---SparkSQL联结操作
一、 数据准备
本文主要介绍 Spark SQL 的多表连接,需要预先准备测试数据。分别创建员工和部门的 Datafame,并注册为临时视图,代码如下:
val spark = SparkSession.builder().appName("aggregations").master("local[2]").getOrCreate()
val empDF = spark.read.json("/usr/file/json/emp.json")
empDF.createOrReplaceTempView("emp")
val deptDF = spark.read.json("/usr/file/json/dept.json")
deptDF.createOrReplaceTempView("dept")
两表的主要字段如下:
emp 员工表
|-- ENAME: 员工姓名
|-- DEPTNO: 部门编号
|-- EMPNO: 员工编号
|-- HIREDATE: 入职时间
|-- JOB: 职务
|-- MGR: 上级编号
|-- SAL: 薪资
|-- COMM: 奖金
dept 部门表
|-- DEPTNO: 部门编号
|-- DNAME: 部门名称
|-- LOC: 部门所在城市
注:emp.json,dept.json 可以在本仓库的resources 目录进行下载。
二、连接类型
Spark 中支持多种连接类型:
- Inner Join : 内连接;
- Full Outer Join : 全外连接;
- Left Outer Join : 左外连接;
- Right Outer Join : 右外连接;
- Left Semi Join : 左半连接;
- Left Anti Join : 左反连接;
- Natural Join : 自然连接;
- Cross (or Cartesian) Join : 交叉 (或笛卡尔) 连接。
其中内,外连接,笛卡尔积均与普通关系型数据库中的相同,如下图所示:
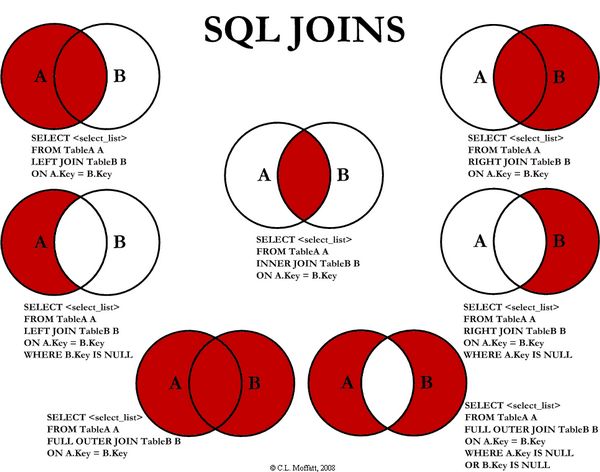
这里解释一下左半连接和左反连接,这两个连接等价于关系型数据库中的 IN 和 NOT IN 字句:
-- LEFT SEMI JOIN
SELECT * FROM emp LEFT SEMI JOIN dept ON emp.deptno = dept.deptno
-- 等价于如下的 IN 语句
SELECT * FROM emp WHERE deptno IN (SELECT deptno FROM dept)
-- LEFT ANTI JOIN
SELECT * FROM emp LEFT ANTI JOIN dept ON emp.deptno = dept.deptno
-- 等价于如下的 IN 语句
SELECT * FROM emp WHERE deptno NOT IN (SELECT deptno FROM dept)
所有连接类型的示例代码如下:
2.1 INNER JOIN
// 1.定义连接表达式
val joinExpression = empDF.col("deptno") === deptDF.col("deptno")
// 2.连接查询
empDF.join(deptDF,joinExpression).select("ename","dname").show()
// 等价 SQL 如下:
spark.sql("SELECT ename,dname FROM emp JOIN dept ON emp.deptno = dept.deptno").show()
2.2 FULL OUTER JOIN
empDF.join(deptDF, joinExpression, "outer").show()
spark.sql("SELECT * FROM emp FULL OUTER JOIN dept ON emp.deptno = dept.deptno").show()
2.3 LEFT OUTER JOIN
empDF.join(deptDF, joinExpression, "left_outer").show()
spark.sql("SELECT * FROM emp LEFT OUTER JOIN dept ON emp.deptno = dept.deptno").show()
2.4 RIGHT OUTER JOIN
empDF.join(deptDF, joinExpression, "right_outer").show()
spark.sql("SELECT * FROM emp RIGHT OUTER JOIN dept ON emp.deptno = dept.deptno").show()
2.5 LEFT SEMI JOIN
empDF.join(deptDF, joinExpression, "left_semi").show()
spark.sql("SELECT * FROM emp LEFT SEMI JOIN dept ON emp.deptno = dept.deptno").show()
2.6 LEFT ANTI JOIN
empDF.join(deptDF, joinExpression, "left_anti").show()
spark.sql("SELECT * FROM emp LEFT ANTI JOIN dept ON emp.deptno = dept.deptno").show()
2.7 CROSS JOIN
empDF.join(deptDF, joinExpression, "cross").show()
spark.sql("SELECT * FROM emp CROSS JOIN dept ON emp.deptno = dept.deptno").show()
2.8 NATURAL JOIN
自然连接是在两张表中寻找那些数据类型和列名都相同的字段,然后自动地将他们连接起来,并返回所有符合条件的结果。
spark.sql("SELECT * FROM emp NATURAL JOIN dept").show()
以下是一个自然连接的查询结果,程序自动推断出使用两张表都存在的 dept 列进行连接,其实际等价于:
spark.sql("SELECT * FROM emp JOIN dept ON emp.deptno = dept.deptno").show()
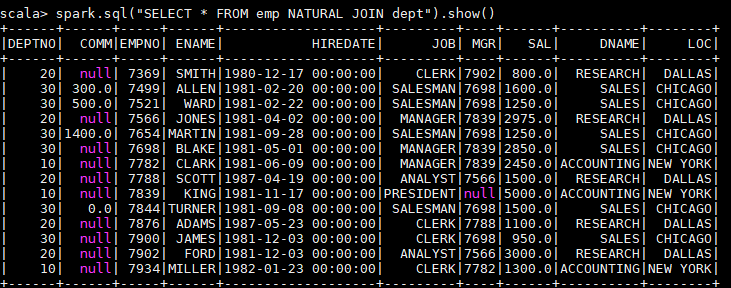
由于自然连接常常会产生不可预期的结果,所以并不推荐使用。
三、连接的执行
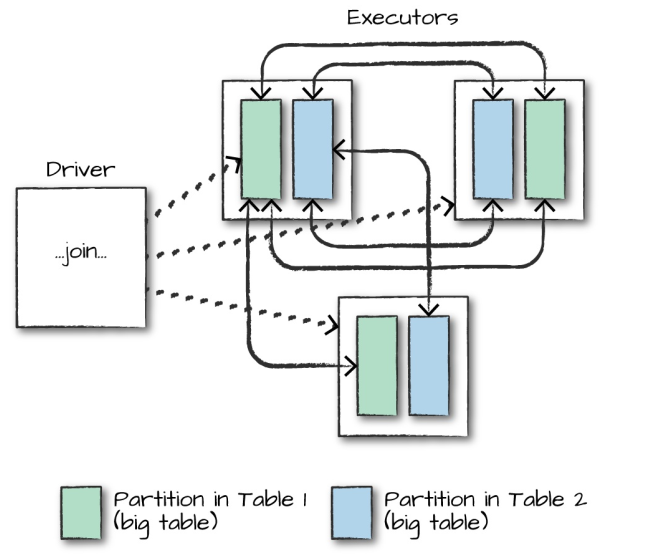
在对大表与大表之间进行连接操作时,通常都会触发 Shuffle Join,两表的所有分区节点会进行 All-to-All 的通讯,这种查询通常比较昂贵,会对网络 IO 会造成比较大的负担。
而对于大表和小表的连接操作,Spark 会在一定程度上进行优化,如果小表的数据量小于 Worker Node 的内存空间,Spark 会考虑将小表的数据广播到每一个 Worker Node,在每个工作节点内部执行连接计算,这可以降低网络的 IO,但会加大每个 Worker Node 的 CPU 负担。
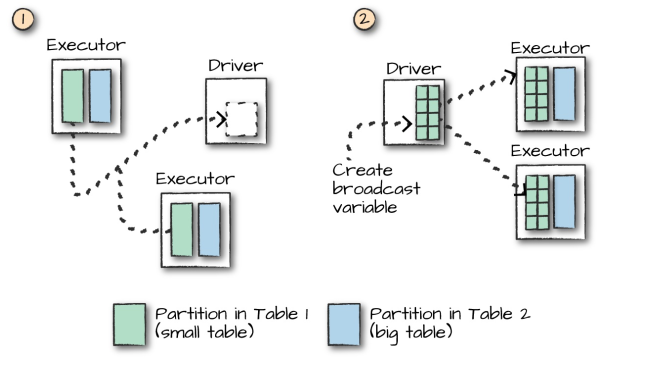
是否采用广播方式进行 Join 取决于程序内部对小表的判断,如果想明确使用广播方式进行 Join,则可以在 DataFrame API 中使用 broadcast 方法指定需要广播的小表:
empDF.join(broadcast(deptDF), joinExpression).show()
参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
入门大数据---SparkSQL联结操作的更多相关文章
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---SparkSQL常用聚合函数
一.简单聚合 1.1 数据准备 // 需要导入 spark sql 内置的函数包 import org.apache.spark.sql.functions._ val spark = SparkSe ...
- 入门大数据---MapReduce-API操作
一.环境 Hadoop部署环境: Centos3.10.0-327.el7.x86_64 Hadoop2.6.5 Java1.8.0_221 代码运行环境: Windows 10 Hadoop 2.6 ...
- 入门大数据---Spark整体复习
一. Spark简介 1.1 前言 Apache Spark是一个基于内存的计算框架,它是Scala语言开发的,而且提供了一站式解决方案,提供了包括内存计算(Spark Core),流式计算(Spar ...
- 入门大数据---Spark_RDD
一.RDD简介 RDD 全称为 Resilient Distributed Datasets,是 Spark 最基本的数据抽象,它是只读的.分区记录的集合,支持并行操作,可以由外部数据集或其他 RDD ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- Dapper学习(四)之Dapper Plus的大数据量的操作
这篇文章主要讲 Dapper Plus,它使用用来操作大数量的一些操作的.比如插入1000条,或者10000条的数据时,再使用Dapper的Execute方法,就会比较慢了.这时候,可以使用Dappe ...
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
随机推荐
- 【极客思考】计算机网络:Wireshark抓包分析TCP中的三次握手与四次挥手
[摘要]本文重点分析计算机网络中TCP协议中的握手和挥手的过程. [前提说明] 前段时间突然看到了一篇关于TCP/IP模型的文章,心想这段时间在家里也用wireshark抓了点包,那么想着想着就觉得需 ...
- Rocket - tilelink - Nodes
https://mp.weixin.qq.com/s/KJ8pVH76rdxPOZ1vE3QlKA 简单介绍tilelink对Diplomacy Nodes的实现. 1. TLImp ...
- Java实现 LeetCode 826 安排工作以达到最大收益(暴力DP)
826. 安排工作以达到最大收益 有一些工作:difficulty[i] 表示第i个工作的难度,profit[i]表示第i个工作的收益. 现在我们有一些工人.worker[i]是第i个工人的能力,即该 ...
- Java实现 LeetCode 798 得分最高的最小轮调 (暴力分析)
798. 得分最高的最小轮调 给定一个数组 A,我们可以将它按一个非负整数 K 进行轮调,这样可以使数组变为 A[K], A[K+1], A{K+2], - A[A.length - 1], A[0] ...
- Java实现 蓝桥杯VIP 算法训练 矩阵加法
时间限制:1.0s 内存限制:512.0MB 问题描述 给定两个N×M的矩阵,计算其和.其中: N和M大于等于1且小于等于100,矩阵元素的绝对值不超过1000. 输入格式 输入数据的第一行包含两个整 ...
- Java实现 蓝桥杯 算法提高 快速排序
试题 算法提高 快速排序 资源限制 时间限制:1.0s 内存限制:256.0MB 问题描述 用递归来实现快速排序(quick sort)算法.快速排序算法的基本思路是:假设要对一个数组a进行排序,且a ...
- TZOJ Start
描述 After the Online Round contest, we believe that you have already known how to write programs in A ...
- 总结梳理:webpack中如何使用vue
1. 安装vue的包 cnpm i vue -S 2. 由于在webpack中,推荐使用 .vue这个组件模板文件定义的组件,所以,需要安装, 能解析这个文件的loader: cnpm i vu ...
- ASP.NET Core Blazor WebAssembly实现一个简单的TODO List
基于blazor实现的一个简单的TODO List 最近看到一些大佬都开始关注blazor,我也想学习一下.做了一个小的demo,todolist,仅是一个小示例,参考此vue项目的实现http:// ...
- 安装fail2ban,防止ssh爆破及cc攻击
背景:之前写过shell脚本防止服务器ssh爆破,但是对于服务器的cpu占用较多,看来下资料安装fail2ban 可以有效控制ssh爆破 1:fail2ban 安装(环境:centos6 宝塔) y ...