Flink读写Redis(一)-写入Redis
项目pom文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.jike.flink</groupId>
<artifactId>flink-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<flink.version>1.10.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- flink 11中需要手动添加
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.11.2</version>
</dependency>
-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.5</version>
<scope>system</scope>
<systemPath>${basedir}/lib/flink-connector-redis_2.11-1.1.5.jar</systemPath>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
</project>
实现flink写入redis
实现wordcount功能,并将结果实时写入redis,这里使用了第三方依赖flink-connector-redis_2.11,该依赖提供了RedisSink可以直接使用,具体代码如下:
代码
首先定义数据源处理实现类LineSplitter,该类将一行数据分词,输出<单词,1>元祖
package com.jike.flink.examples.redis;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class LineSplitter implements FlatMapFunction<String, Tuple2<String,Integer>> {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] tokens = s.toLowerCase().split("\\W+");
for(String token : tokens){
if(token.length() > 0){
collector.collect(new Tuple2<String,Integer>(token,1));
}
}
}
}
然后定义数据写入Redis的配置类,这里面将统计后的所有信息词频写入一个哈希表,哈希表的key为"flink",作为测试使用,哈希表中每个元素key为单词,value为词频
package com.jike.flink.examples.redis;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
public class SinkRedisMapper implements RedisMapper<Tuple2<String,Integer>> {
@Override
public RedisCommandDescription getCommandDescription() {
//hset
return new RedisCommandDescription(RedisCommand.HSET,"flink");
}
@Override
public String getKeyFromData(Tuple2<String, Integer> stringIntegerTuple2) {
return stringIntegerTuple2.f0;
}
@Override
public String getValueFromData(Tuple2<String, Integer> stringIntegerTuple2) {
return stringIntegerTuple2.f1.toString();
}
}
最后编写主程序类,该类中使用了socketTextStream数据源,通过前面定义LineSplitter完成解析,然后根据单词进行分组统计,最后写入redis
package com.jike.flink.examples.redis;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
public class Sink2Redis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataStreamSource = executionEnvironment.socketTextStream("实际IP",12345);
DataStream<Tuple2<String,Integer>> counts = dataStreamSource.flatMap(new LineSplitter()).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0;
}
}).sum(1);
//控制台打印
counts.print().setParallelism(1);
//定义redis服务器信息
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("redis服务器ip").setPort(redis服务端口).setPassword("redis服务密码").build();
counts.addSink(new RedisSink<>(conf,new SinkRedisMapper()));
executionEnvironment.execute();
}
}
运行效果
通过nc -l 12345,命令模拟数据源,并输入一些数据

IDEA中查看打印记录
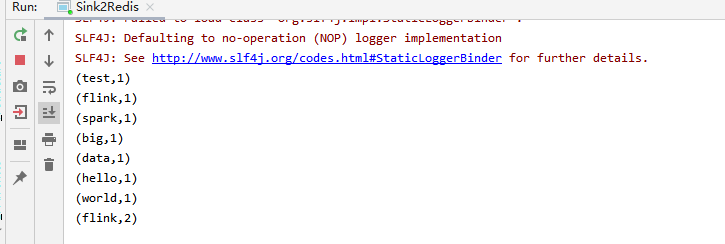
查看redis

可以发现数据已写入redis
总结
flink-connector-redis_2.11中提供了RedisSink类,该类实现了RichSinkFunction,可以直接使用,如果有特殊需求,可以自定义Sink类,继承RichSinkFunction,实现特殊处理。flink-connector-redis_2.11的源码比较简洁,下一篇打算分析学习下。
Flink读写Redis(一)-写入Redis的更多相关文章
- Flink读写Redis(三)-读取redis数据
自定义flink的RedisSource,实现从redis中读取数据,这里借鉴了flink-connector-redis_2.11的实现逻辑,实现对redis读取的逻辑封装,flink-connec ...
- Flink读写Redis(二)-flink-redis-connector代码学习
源码结构 RedisSink package org.apache.flink.streaming.connectors.redis; import org.apache.flink.configur ...
- Redis学习笔记~Redis主从服务器,读写分离
回到目录 Redis这个Nosql的存储系统一般会被部署到linux系统中,我们可以把它当成是一个数据服务器,对于并发理大时,我们会使用多台服务器充当Redis服务器,这时,各个Redis之间也是分布 ...
- redis作为缓存场景使用,内存耗尽时,突然出现大量的逐出,在这个逐出的过程中阻塞正常的读写请求,导致 redis 短时间不可用
redis 突然大量逐出导致读写请求block 内容目录: 现象 背景 原因 解决方案 ref 现象 redis作为缓存场景使用,内存耗尽时,突然出现大量的逐出,在这个逐出的过程中阻塞正常的读写请 ...
- flink04 -----1 kafkaSource 2. kafkaSource的偏移量的存储位置 3 将kafka中的数据写入redis中去 4 将kafka中的数据写入mysql中去
1. kafkaSource 见官方文档 2. kafkaSource的偏移量的存储位置 默认存在kafka的特殊topic中,但也可以设置参数让其不存在kafka的特殊topic中 3 将k ...
- 批量写入redis
批量写入redis key := GetSeriesKey(series.Id) idNames = append(idNames, key, series.Name) == { err = Mset ...
- ELKStack入门篇(三)之logstash收集日志写入redis
1.部署Redis 1.1.下载redis [root@linux-node2 ~]# wget http://download.redis.io/releases/redis-4.0.6.tar.g ...
- ELK之logstash收集日志写入redis及读取redis
logstash->redis->logstash->elasticsearch 1.安装部署redis cd /usr/local/src wget http://download ...
- Redis原子性写入HASH结构数据并设置过期时间
Redis中提供了原子性命令SETEX或SET来写入STRING类型数据并设置Key的过期时间: > SET key value EX NX ok > SETEX key value ok ...
随机推荐
- python-基础入门-7基础
1.语法和语句 Python中有一些基本规则和特殊字符 1)#符号之后的表示注释 2)\n符号表示换行 3)\继续上一行的内容 推荐使用括号,这样可读性更好 4):将两个语句链接在一行中 类似于c语言 ...
- 深入学习synchronized
synchronized 并发编程中的三个问题: 可见性(Visibility) 是指一个线程对共享变量进行修改,另一个先立即得到修改后的最新值. 代码演示: public class Test01V ...
- 使用iOS 设备管理器 iMazing导出苹果设备中的录音文件
iMazing是一款功能强大的苹果设备管理软件,能为用户提供便捷的录音文件导出功能.用户可以直接将录音文件从苹果设备中导出,接下来,就让小编为大家演示一下如何操作吧. 图1:iMazing界面 1.打 ...
- MathType如何输入微分上的点
作为被老师们青睐的公式编辑器,MathType可以帮助插入各种数学符号和编辑数学公式,从而提高数学试卷的编写效率.但是作为新手,在编辑公式的时候难免有困难,比如就有人问:如何输入微分上的点?其实也是有 ...
- MySQL常用命令与语句
目录 Shell命令 查看系统信息 查看系统变量 设置系统变量 数据库操作 查看表信息 修改表语句 操作表 操作索引 操作约束 操作列 查询常用语句 Shell命令 mysql -uroot -p12 ...
- 从数据仓库双集群系统模式探讨,看GaussDB(DWS)的容灾设计
摘要:本文主要是探讨OLAP关系型数据库框架的数据仓库平台如何设计双集群系统,即增强系统高可用的保障水准,然后讨论一下GaussDB(DWS)的容灾应该如何设计. 当前社会.企业运行当中,大数据分析. ...
- yii2.0 关于 ActiveForm 中 checkboxList 的使用
在视图中创建复选框,列出复选框内的内容其中$id 为 列出在复选框中的数组 //$ids:所有要显示的checkbox(Array)<?=$form->field($model, 'id' ...
- try-with-resources和multi-catch的使用
1.首先说一下以前开发中我们在处理异常时,我们会使用try-catch-finally来处理异常. //使用try-catch-finallypublic static void main(Strin ...
- 三. Vue组件化
1. 认识组件化 1.1 什么是组件化 人面对复杂问题的处理方式 任何一个人处理信息的逻辑能力都是有限的,所以当面对一个非常复杂的问题时我们不太可能一次性搞定一大堆的内容. 但是我们人有一种天生的能力 ...
- 关于String的matches方法
弊端: 虽然String.matches方法最易于看一个字符串是否与正则表达式相匹配.但并不适合在注重性能的情形中重复使用. 问题在于,它内部为正则表达式创建了一个Pattern实例,却只用一次,之后 ...