MapReduce之自定义OutputFormat
@
OutputFormat接口实现类
OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了OutputFormat接口。下面介绍几种常见的OutputFormat实现类。
文本输出
TextoutputFormat
默认的输出格式是TextOutputFormat,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toString()方法把它们转换为字符串。SequenceFileOutputFormat
将SecquenceFileOutputFormat输出作为后续MapReduce任务的输入,这便是一种好的输出格式,因为它的格式紧凑,很容易被压缩。自定义OutputFormat
根据用户需求,自定义实现输出。
自定义OutputFormat使用场景及步骤
使用场景
- 为了实现控制最终文件的输出路径和输出格式,可以自定义OutputFormat。
例如:要在一个MapReduce程序中根据数据的不同输出两类结果到不同目录,这类灵活的输出需求可以通过自定义OutputFormat来实现。 - 自定义OutputFormat步骤
(1)自定义一个类继承FileOutputFormat。
(2)改写RecordWriter,具体改写输出数据的方法write()。
自定义OutputFormat 案例实操
需求
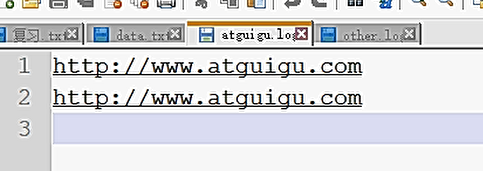
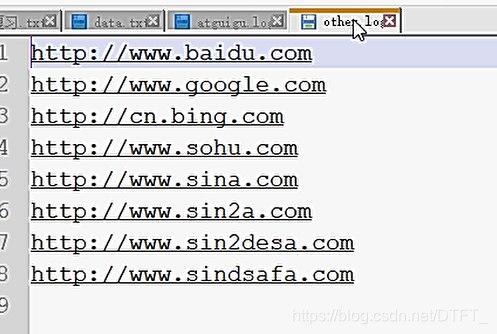
过滤输入的log日志,包含atguigu的网站输出到e:/atguigu.log,不包含atguigu的网站输出到e:/other.log。
输入数据

什么时候需要Reduce
①合并
②需要对数据排序
所以本案例不需要Reduce阶段,key-value不需要实现序列化
CustomOFMapper.java
public class CustomOFMapper extends Mapper<LongWritable, Text, String, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, String, NullWritable>.Context context) throws IOException, InterruptedException {
String content = value.toString();
//value不需要,但是不能用Null这个关键字,要使用NullWritable对象
context.write(content+"\r\n", NullWritable.get());
}
}
MyOutPutFormat.java
public class MyOutPutFormat extends FileOutputFormat<String, NullWritable>{
@Override
public RecordWriter<String, NullWritable> getRecordWriter(TaskAttemptContext job)
throws IOException, InterruptedException {
return new MyRecordWriter(job);//传递job对象,才能在RecordWriter中获取配置
}
}
MyRecordWriter.java
public class MyRecordWriter extends RecordWriter<String, NullWritable> {
private Path atguiguPath=new Path("e:/atguigu.log");
private Path otherPath=new Path("e:/other.log");
private FSDataOutputStream atguguOS ;
private FSDataOutputStream otherOS ;
private FileSystem fs;
private TaskAttemptContext context;
public MyRecordWriter(TaskAttemptContext job) throws IOException {
context=job;
Configuration conf = job.getConfiguration();
fs=FileSystem.get(conf);
atguiguOS = fs.create(atguiguPath);
otherOS = fs.create(otherPath);
}
// 将key-value写出到文件
@Override
public void write(String key, NullWritable value) throws IOException, InterruptedException {
if (key.contains("atguigu")) {
atguguOS.write(key.getBytes());//写到atguigu.log
//统计输出的含有atguigu字符串的key-value个数
context.getCounter("MyCounter", "atguiguCounter").increment(1);
}else {
otherOS.write(key.getBytes());//写到other.log
context.getCounter("MyCounter", "otherCounter").increment(1);
}
}
// 关闭流
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
if (atguguOS != null) {
IOUtils.closeStream(atguguOS);
}
if (otherOS != null) {
IOUtils.closeStream(otherOS);
}
if (fs != null) {
fs.close();
}
}
}
CustomOFDriver.java
public class CustomOFDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("e:/mrinput/outputformat");
Path outputPath=new Path("e:/mroutput/outputformat");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
//重点,设置为自定义的输出格式
job.setJarByClass(CustomOFDriver.class);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(CustomOFMapper.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 设置输入和输出格式
job.setOutputFormatClass(MyOutPutFormat.class);
// 取消reduce阶段。设置为0,默认为1
job.setNumReduceTasks(0);
// ③运行Job
job.waitForCompletion(true);
}
}
输出文件:
MapReduce之自定义OutputFormat的更多相关文章
- 第3节 mapreduce高级:7、自定义outputformat实现输出到不同的文件夹下面
2.1 需求 现在有一些订单的评论数据,需求,将订单的好评与差评进行区分开来,将最终的数据分开到不同的文件夹下面去,数据内容参见资料文件夹,其中数据第九个字段表示好评,中评,差评.0:好评,1:中评, ...
- Hadoop案例(五)过滤日志及自定义日志输出路径(自定义OutputFormat)
过滤日志及自定义日志输出路径(自定义OutputFormat) 1.需求分析 过滤输入的log日志中是否包含xyg (1)包含xyg的网站输出到e:/xyg.log (2)不包含xyg的网站输出到e: ...
- Hadoop_27_MapReduce_运营商原始日志增强(自定义OutputFormat)
1.需求: 现有一些原始日志需要做增强解析处理,流程: 1. 从原始日志文件中读取数据(日志文件:https://pan.baidu.com/s/12hbDvP7jMu9yE-oLZXvM_g) 2. ...
- hadoop 自定义OutputFormat
1.继承FileOutputFormat,复写getRecordWriter方法 /** * @Description:自定义outputFormat,输出数据到不同的文件 */ public cla ...
- 关于spark写入文件至文件系统并制定文件名之自定义outputFormat
引言: spark项目中通常我们需要将我们处理之后数据保存到文件中,比如将处理之后的RDD保存到hdfs上指定的目录中,亦或是保存在本地 spark保存文件: 1.rdd.saveAsTextFile ...
- 关于MapReduce中自定义分区类(四)
MapTask类 在MapTask类中找到run函数 if(useNewApi){ runNewMapper(job, splitMetaInfo, umbilical, reporter ...
- 关于MapReduce中自定义分组类(三)
Job类 /** * Define the comparator that controls which keys are grouped together * for a single ...
- 关于MapReduce中自定义带比较key类、比较器类(二)——初学者从源码查看其原理
Job类 /** * Define the comparator that controls * how the keys are sorted before they * are pa ...
- 关于MapReduce中自定义Combine类(一)
MRJobConfig public static fina COMBINE_CLASS_ATTR 属性COMBINE_CLASS_ATTR = "mapreduce.j ...
随机推荐
- 在spyder中无法import module
如果在anaconda中下载安装了模块,但是在spyder中无法import,可能是因为两个python环境并不一致,在promote重新conda install spyder即可
- L-BFGS算法详解(逻辑回归的默认优化算法)
python信用评分卡建模(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_ca ...
- Shaderlab-10chapter-立方体纹理、玻璃效果
10.1.1天空盒子 window - Lighting - skyMaterial 创建mat,shader选自带的6 side shader 确保相机选skybox 如果某个相机需要覆盖,添加sk ...
- [Qt2D绘图]-05绘图设备-QPixmap&&QBitmap&&QImage&&QPicture
这篇笔记记录的是QPainterDevice(绘图设备,可以理解为一个画板) 大纲: 绘图设备相关的类:QPixmap QBitmap QImage QPicture QPixmap ...
- QQ音乐Android客户端Web页面通用性能优化实践
QQ音乐 Android 客户端的 Web 页面日均 PV 达到千万量级,然而页面的打开耗时与 Native 页面相距甚远,需要系统性优化.本文将介绍 QQ 音乐 Android 客户端在进行 Web ...
- pyenv虚拟环境安装
安装过程 配置yum源 # curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo ...
- java8之Stream流处理
简介 Stream 流处理,首先要澄清的是 java8 中的 Stream 与 I/O 流 InputStream 和 OutputStream 是完全不同的概念. Stream 机制是针对集合迭代器 ...
- JAXB XML生成CDATA类型的节点
试了好久才找到一个解决办法,我是用的JAXB的,如果你们也是用JAXB那么可以直接借鉴此方法,别的方式你们自行测试吧 第一步:新增一个适配器类 package com.message.util; im ...
- git的核心命令使用和底层原理解析
文章目录: GIT体系概述 GIT 核心命令使用 GIT 底层原理 一.GIT体系概述 GIT 与 svn 主要区别: 存储方式不一样 使用方式不一样 管理模式不一样 1.存储方式区别 GIT把内容按 ...
- Eclipse创建Web项目后新建Servlet时报红叉错误 or 导入别人Web项目时报红叉错误 的解决办法
如图,出现类似红叉错误. 1.在项目名称上点击右键->Build Path->Configure Build Path 2.在弹出来的框中点击Add Library,如图 3.接下来选择U ...