强化学习、分布式计算方向的phd毕业后去企业的要求
实验室慕师弟马上要phd毕业了,虽然我是遥遥无期,但是看到身边同学可以上岸还是提师弟高兴。由于师弟准备去企业工作,于是乎我也不免好奇起来phd毕业后去公司会有什么样的要求,于是网上找了找招聘信息,挑了几个不错的招聘岗位,这里mark下。
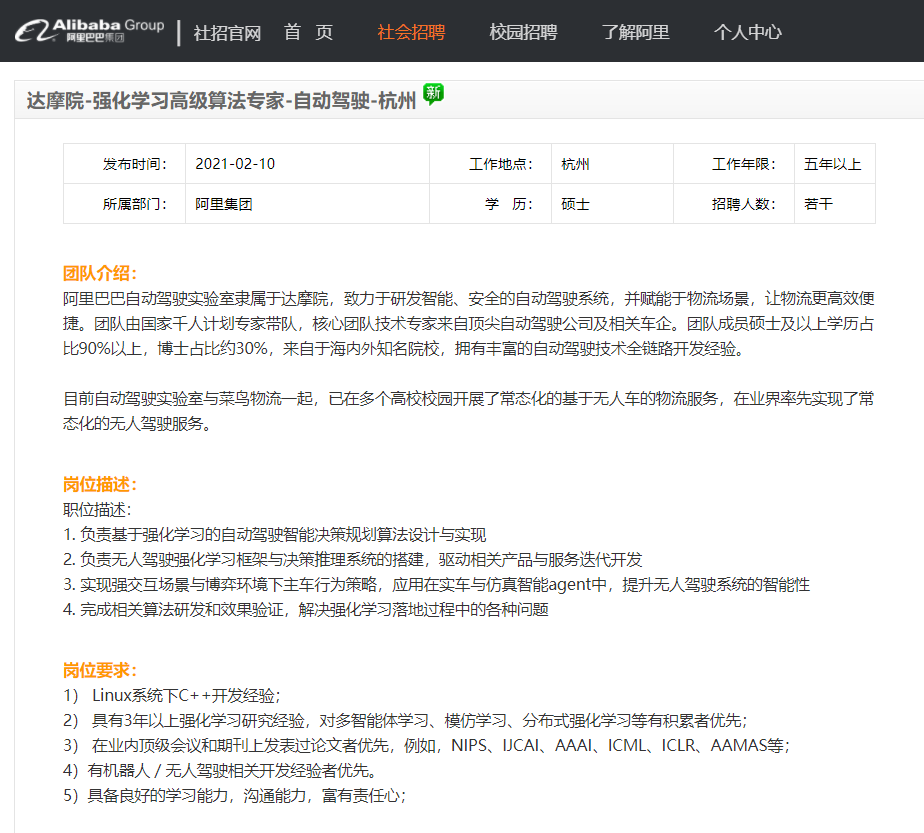
1. 强化学习方向的(自动驾驶)
虽然要求硕士学历就可以,不过看到其中的顶会论文要求便知道这个岗位也是不容易get到的。
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP705939
======================================================
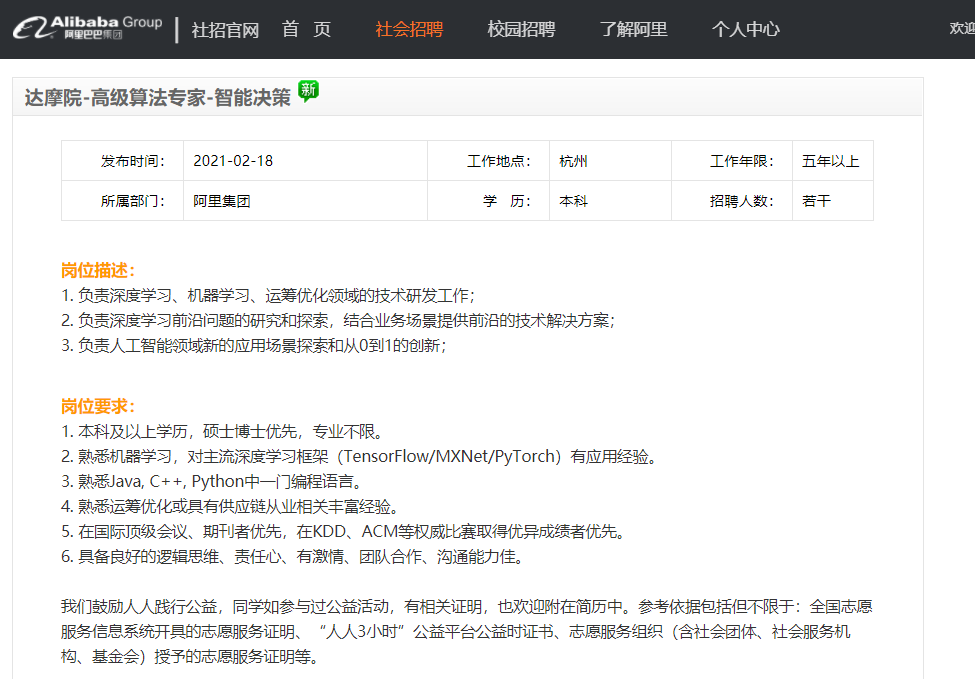
2. 智能决策方向
要求论文或比赛经历,要求比第一个貌似低些。
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP635511
=============================================
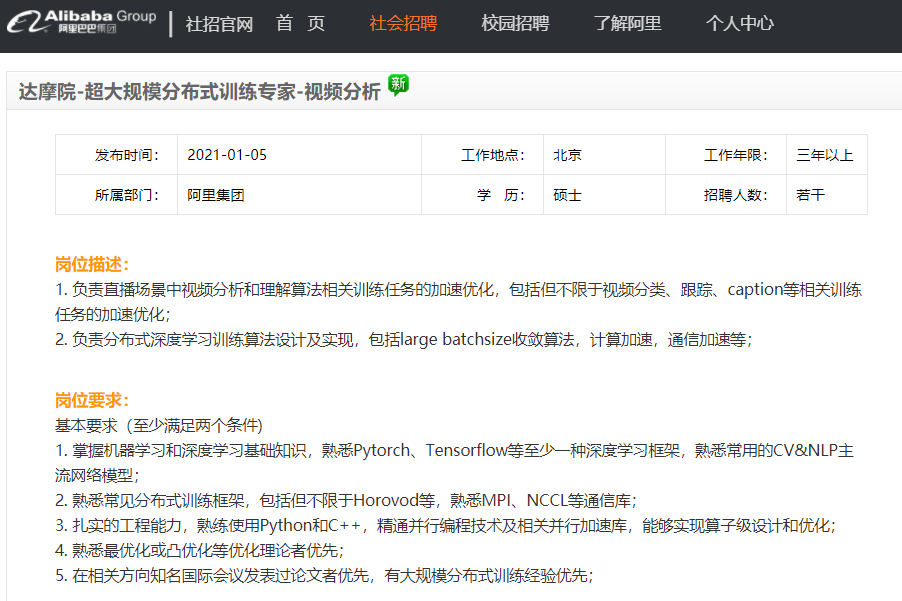
3. 分布式人工智能算法工程师
在对论文等有要求外还希望有较好的相关编程经验(分布式:MPI,NCCL等)
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP630418
============================================
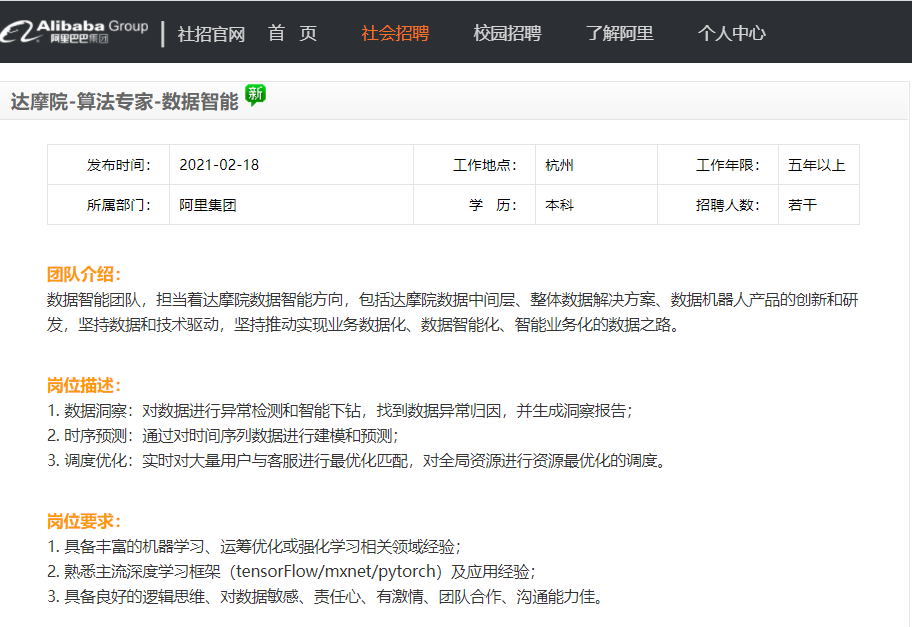
4. 数据智能
要求较低。
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP626894
===============================================
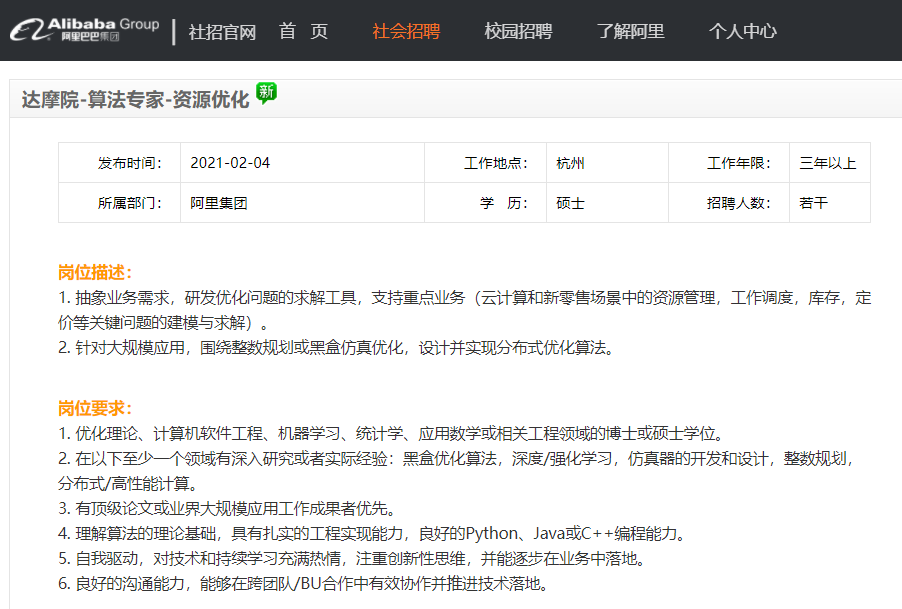
5. 资源优化( 算法工程师 )
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP634344
==============================================
强化学习、分布式计算方向的phd毕业后去企业的要求的更多相关文章
- 强化学习 1 --- 马尔科夫决策过程详解(MDP)
强化学习 --- 马尔科夫决策过程(MDP) 1.强化学习介绍 强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体而言:机器处在一个环境 ...
- 强化学习(二)马尔科夫决策过程(MDP)
在强化学习(一)模型基础中,我们讲到了强化学习模型的8个基本要素.但是仅凭这些要素还是无法使用强化学习来帮助我们解决问题的, 在讲到模型训练前,模型的简化也很重要,这一篇主要就是讲如何利用马尔科夫决策 ...
- 强化学习 CartPole实验的一些启发 有没有可能设计一个新的实验呢?(杆子可以向360度方向倾倒,可行吗?)
最近在看强化学习方面的东西,突然想到了这么一个事情,那就是经典的CartPole游戏我们改变一下,或者说升级一下,那么使用强化学习是否能得到不错的效果呢? 原始游戏如图: 一点个人的想法: ===== ...
- 【整理】强化学习与MDP
[入门,来自wiki] 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的 ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 强化学习(十三) 策略梯度(Policy Gradient)
在前面讲到的DQN系列强化学习算法中,我们主要对价值函数进行了近似表示,基于价值来学习.这种Value Based强化学习方法在很多领域都得到比较好的应用,但是Value Based强化学习方法也有很 ...
- 强化学习(八)价值函数的近似表示与Deep Q-Learning
在强化学习系列的前七篇里,我们主要讨论的都是规模比较小的强化学习问题求解算法.今天开始我们步入深度强化学习.这一篇关注于价值函数的近似表示和Deep Q-Learning算法. Deep Q-Lear ...
- 强化学习(六)时序差分在线控制算法SARSA
在强化学习(五)用时序差分法(TD)求解中,我们讨论了用时序差分来求解强化学习预测问题的方法,但是对控制算法的求解过程没有深入,本文我们就对时序差分的在线控制算法SARSA做详细的讨论. SARSA这 ...
- 强化学习(三)用动态规划(DP)求解
在强化学习(二)马尔科夫决策过程(MDP)中,我们讨论了用马尔科夫假设来简化强化学习模型的复杂度,这一篇我们在马尔科夫假设和贝尔曼方程的基础上讨论使用动态规划(Dynamic Programming, ...
随机推荐
- ES进阶
https://www.elastic.co/guide/en/elasticsearch/reference/current/cat.html 1.监控接口 访问es的_cat接口,获取不同的属性 ...
- SVG <pattern> 标签的用法和应用场景
通过使用 <pattern> 标签,可以在 SVG 图像内部定义可重复使用的任意图案.这些图案可以通过 fill 属性或 stroke 属性进行引用. 使用场景 例如我们要在 <sv ...
- POJ2247,hdu1058(Humble Numbers)
Problem Description A number whose only prime factors are 2,3,5 or 7 is called a humble number. The ...
- 2019南京区域赛ABCHJK题解 & KM-bfs(O(n^3))板子
A.Hard Problem 题目大意:给你一个数n,然后让你计算一个子集大小,这个大小的子集要保证一定存在一个数是另一个数的约数,求出这个最小的数. 做法:显然后面的\(\frac{n}{2}\)个 ...
- Chrome插件:Postman Interceptor 调试的终极利器
今天给大家介绍一款非常实用的工具--Postman Interceptor. 这个工具可以捕捉任何网站的请求,并将其发送到Postman客户端. 对于经常和API打交道的程序员来说,Postman I ...
- NXP i.MX 8M Mini工业级核心板规格书(四核ARM Cortex-A53 + 单核ARM Cortex-M4,主频1.6GHz)
1 核心板简介 创龙科技SOM-TLIMX8是一款基于NXP i.MX 8M Mini的四核ARM Cortex-A53 + 单核ARM Cortex-M4异构多核处理器设计的高端工业级核心板,AR ...
- 数据结构—包(Bag)
数据结构中的包,其实是对现实中的包的一种抽象. 想像一下现实中的包,比如书包,它能做什么?有哪些功能?首先它用来装东西,里面的东西可以随便放,没有规律,没有顺序,当然,可以放多个相同的东西.其次,东西 ...
- vulnhub - hackme1
vulnhub - hackme1 信息收集 端口扫描 详细扫描 目录扫描跟漏洞探测没发现什么可用信息,除了登录还有一个uploads目录应该是进入后台之后才能使用 web主页是个登录注册页面,爆了一 ...
- 树莓派安装OpenCv
树莓派安装OpenCv 更换树莓派软件源 我们选择将树莓派的软件源切换到清华大学镜像站,据笔者亲测,通过此站可以顺利安装openCV. 切换软件源需要修改两个软件源配置文件的内容. 第一个需要修改是「 ...
- mac navicat免激活版
Navicat 12 第一步:终端执行 sudo spctl --master-disable 第二步:下载安装即可使用 https://pan.baidu.com/s/1tHq-wqAIggD0Fo ...