吴裕雄 python 机器学习——岭回归
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets, linear_model
from sklearn.model_selection import train_test_split def load_data():
diabetes = datasets.load_diabetes()
return train_test_split(diabetes.data,diabetes.target,test_size=0.25,random_state=0) #岭回归
def test_Ridge(*data):
X_train,X_test,y_train,y_test=data
regr = linear_model.Ridge()
regr.fit(X_train, y_train)
print('Coefficients:%s, intercept %.2f'%(regr.coef_,regr.intercept_))
print("Residual sum of squares: %.2f"% np.mean((regr.predict(X_test) - y_test) ** 2))
print('Score: %.2f' % regr.score(X_test, y_test)) # 产生用于回归问题的数据集
X_train,X_test,y_train,y_test=load_data()
# 调用 test_Ridge
test_Ridge(X_train,X_test,y_train,y_test) def test_Ridge_alpha(*data):
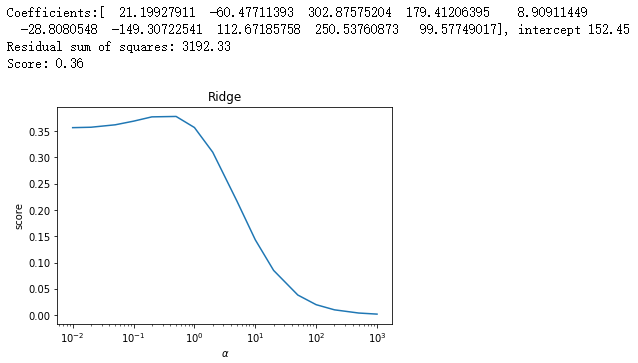
X_train,X_test,y_train,y_test=data
alphas=[0.01,0.02,0.05,0.1,0.2,0.5,1,2,5,10,20,50,100,200,500,1000]
scores=[]
for i,alpha in enumerate(alphas):
regr = linear_model.Ridge(alpha=alpha)
regr.fit(X_train, y_train)
scores.append(regr.score(X_test, y_test))
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(alphas,scores)
ax.set_xlabel(r"$\alpha$")
ax.set_ylabel(r"score")
ax.set_xscale('log')
ax.set_title("Ridge")
plt.show() test_Ridge_alpha(X_train,X_test,y_train,y_test) # 调用 test_Ridge_alpha
吴裕雄 python 机器学习——岭回归的更多相关文章
- 吴裕雄 python 机器学习——逻辑回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——ElasticNet回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——Lasso回归
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model from s ...
- 吴裕雄 python 机器学习——KNN回归KNeighborsRegressor模型
import numpy as np import matplotlib.pyplot as plt from sklearn import neighbors, datasets from skle ...
- 吴裕雄 python 机器学习——回归决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——模型选择回归问题性能度量
from sklearn.metrics import mean_absolute_error,mean_squared_error #模型选择回归问题性能度量mean_absolute_error模 ...
随机推荐
- 嵌入式C语言常见的错误
预处理的错误: #include “stdio.h” //引用符号错误 #inlcude <name> //自定义文件用 " " not find gcc -I ...
- gdb问题value optimized out
gdb正常print一个变量的值: 但如果gdb调试程序的时候打印变量值会出现<value optimized out> 情况: 可以在gcc编译的时候加上 -O0参数项,意思是不进行编译 ...
- Fibonacci_array
重新开始学习C&C++ Courage is resistance to fear, mastery of fear, not abscence of fear //斐波那契数列 Fibona ...
- h5课件是什么?h5(html5)怎样实现交互动画开发?-----浅谈h5交互动画课件的优势
目前很多交互课件,尤其幼儿类的交互课件以动画和交互相结合的类型居多,越来越多的教育机构发现了这种课件对于幼儿的吸引力远大于其他类型的课件,随着flash逐渐被市场淘汰,动画和交互相结合的html5跨平 ...
- Vue.js中ref ($refs)用法举例总结
原文地址:http://www.cnblogs.com/xueweijie/p/6907676.html <div id="app"> <input type=& ...
- Mha-Atlas-MySQL高可用
Mha-Atlas-MySQL高可用 一.MHA简介 1.软件介绍 MHA在MySQL高可用是一个相对成熟的解决方案,是一套优秀的作为mysql高可用环境下故障切换和主从提升的高可用软件,在MySQL ...
- 恢复Windows 10自带的微软正黑字体
突然发现 在word中 Microsoft JhengHei 字体没有了,一查在C:\windows\fonts\msjh.ttc文件还在. Windows Registry Editor Vers ...
- hive 的map数和reduce如何确定(转)
转自博客:https://blog.csdn.net/u013385925/article/details/78245011(没找到原创者,该博客也是转发) 一. 控制hive任务中的map ...
- Error in loadNamespace 的解决之道
Error in loadNamespace(j <- i[[1L]], c(lib.loc, .libPaths()), versionCheck = vI[[j]]) 在构建比较复杂的环 ...
- logback.xml例子
我项目中一直使用这样的模板,留档,并纪念. <?xml version="1.0" encoding="UTF-8"?> <configura ...