吴裕雄 python 机器学习——KNN回归KNeighborsRegressor模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import neighbors, datasets
from sklearn.model_selection import train_test_split def create_regression_data(n):
'''
创建回归模型使用的数据集
'''
X =5 * np.random.rand(n, 1)
y = np.sin(X).ravel()
# 每隔 5 个样本就在样本的值上添加噪音
y[::5] += 1 * (0.5 - np.random.rand(int(n/5)))
# 进行简单拆分,测试集大小占 1/4
return train_test_split(X, y,test_size=0.25,random_state=0) #KNN回归KNeighborsRegressor模型
def test_KNeighborsRegressor(*data):
X_train,X_test,y_train,y_test=data
regr=neighbors.KNeighborsRegressor()
regr.fit(X_train,y_train)
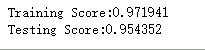
print("Training Score:%f"%regr.score(X_train,y_train))
print("Testing Score:%f"%regr.score(X_test,y_test)) #获取回归模型的数据集
X_train,X_test,y_train,y_test=create_regression_data(1000)
# 调用 test_KNeighborsRegressor
test_KNeighborsRegressor(X_train,X_test,y_train,y_test)
def test_KNeighborsRegressor_k_w(*data):
'''
测试 KNeighborsRegressor 中 n_neighbors 和 weights 参数的影响
'''
X_train,X_test,y_train,y_test=data
Ks=np.linspace(1,y_train.size,num=100,endpoint=False,dtype='int')
weights=['uniform','distance'] fig=plt.figure()
ax=fig.add_subplot(1,1,1)
### 绘制不同 weights 下, 预测得分随 n_neighbors 的曲线
for weight in weights:
training_scores=[]
testing_scores=[]
for K in Ks:
regr=neighbors.KNeighborsRegressor(weights=weight,n_neighbors=K)
regr.fit(X_train,y_train)
testing_scores.append(regr.score(X_test,y_test))
training_scores.append(regr.score(X_train,y_train))
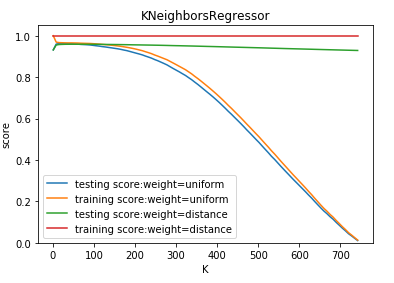
ax.plot(Ks,testing_scores,label="testing score:weight=%s"%weight)
ax.plot(Ks,training_scores,label="training score:weight=%s"%weight)
ax.legend(loc='best')
ax.set_xlabel("K")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.set_title("KNeighborsRegressor")
plt.show() # 调用 test_KNeighborsRegressor_k_w
test_KNeighborsRegressor_k_w(X_train,X_test,y_train,y_test)
def test_KNeighborsRegressor_k_p(*data):
'''
测试 KNeighborsRegressor 中 n_neighbors 和 p 参数的影响
'''
X_train,X_test,y_train,y_test=data
Ks=np.linspace(1,y_train.size,endpoint=False,dtype='int')
Ps=[1,2,10] fig=plt.figure()
ax=fig.add_subplot(1,1,1)
### 绘制不同 p 下, 预测得分随 n_neighbors 的曲线
for P in Ps:
training_scores=[]
testing_scores=[]
for K in Ks:
regr=neighbors.KNeighborsRegressor(p=P,n_neighbors=K)
regr.fit(X_train,y_train)
testing_scores.append(regr.score(X_test,y_test))
training_scores.append(regr.score(X_train,y_train))
ax.plot(Ks,testing_scores,label="testing score:p=%d"%P)
ax.plot(Ks,training_scores,label="training score:p=%d"%P)
ax.legend(loc='best')
ax.set_xlabel("K")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.set_title("KNeighborsRegressor")
plt.show() # 调用 test_KNeighborsRegressor_k_p
test_KNeighborsRegressor_k_p(X_train,X_test,y_train,y_test)

吴裕雄 python 机器学习——KNN回归KNeighborsRegressor模型的更多相关文章
- 吴裕雄 python 机器学习——KNN分类KNeighborsClassifier模型
import numpy as np import matplotlib.pyplot as plt from sklearn import neighbors, datasets from skle ...
- 吴裕雄 python 机器学习——支持向量机非线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——半监督学习LabelSpreading模型
import numpy as np import matplotlib.pyplot as plt from sklearn import metrics from sklearn import d ...
- 吴裕雄 python 机器学习——支持向量机线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——逻辑回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——ElasticNet回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——Lasso回归
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model from s ...
- 吴裕雄 python 机器学习——岭回归
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model from s ...
- 吴裕雄 python 机器学习——层次聚类AgglomerativeClustering模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
随机推荐
- pytest-fixture之conftest.py
场景: 对于一个py文件中某些用例需要前置条件,某些用例不需要前置条件的情况,使用setup/teardown肯定是不方便的, 这时就需要自定义测试用例的前置条件. 1.fixture优点: 命名不局 ...
- TensorFlow入门(常量变量及其基本运算)
1.tensorflow常量变量的定义 测试代码如下: # encoding:utf-8 # OpenCV tensorflow # 类比 语法 api 原理 # 基础数据类型 运算符 流程 字典 数 ...
- STL标准库面试题(转)
一.vector的底层(存储)机制 二.vector的自增长机制 三.list的底层(存储)机制 四.什么情况下用vector,什么情况下用list 五.list自带排序函数的排序原理 六.deque ...
- PP: Tripoles: A new class of relationships in time series data
Problem: ?? mining relationships in time series data; A new class of relationships in time series da ...
- C++类this指针为空时的几个误区
代码: class test{ public: static void f1(){cout<<y<<endl;} void f2(){cout<<y<< ...
- AcWing 482. 合唱队形
#include<iostream> using namespace std ; ; int f[N],g[N]; int w[N]; int main() { int n; cin> ...
- 算法竞赛入门经典第二版 TeX中的引号 P47
#include<bits/stdc++.h> using namespace std; int main(){ ; while( (c = getchar()) !=EOF) //get ...
- vue老项目升级vue-cli3.0
第一步我们卸载全局的vue2.0然后: 打开命令行 输入npm install -g @vue/cli-init 这个就是会安装全局的vue3.0版本.安装好之后我们也可以vue -V查看当前vu ...
- 动态规划(Dynamic Programming, DP)---- 最大连续子序列和
动态规划(Dynamic Programming, DP)是一种用来解决一类最优化问题的算法思想,简单来使,动态规划是将一个复杂的问题分解成若干个子问题,或者说若干个阶段,下一个阶段通过上一个阶段的结 ...
- Python实现求多个集合之间的并集
目的:求多个集合之前的并集,例如:现有四个集合C1 = {11, 22, 13, 14}.C2 = {11, 32, 23, 14, 35}.C3 = {11, 22, 38}.C4 = {11, ...