htmlunit+fastjson抓取酷狗音乐 qq音乐链接及下载
上次学了jsoup之后,发现一些动态生成的网页内容是无法抓取的,于是又学习了htmlunit,下面是抓取酷狗音乐与qq音乐链接的例子:
酷狗音乐:
import java.io.BufferedInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.net.URL;
import java.net.URLEncoder;
import java.util.UUID;
import java.util.regex.Matcher;
import java.util.regex.Pattern; import org.jsoup.nodes.Element; import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient; public class worm7 {
private static String name="离骚";
public static WebClient getWebClient(boolean flag){
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_45);
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setAppletEnabled(false);
webClient.getOptions().setJavaScriptEnabled(flag);
webClient.getOptions().setTimeout(60000);
webClient.getOptions().setPrintContentOnFailingStatusCode(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
return webClient;
}
public static String getMp3Url(WebClient webClient){
FileOutputStream outputStream = null;
InputStream inputStream = null;
BufferedInputStream bis = null;
try {
Page page=webClient.getPage("http://songsearch.kugou.com/song_search_v2?"
+ "callback=jQuery112408395432201569397_1532930925600"
+ "&keyword="+URLEncoder.encode(name, "utf-8")
+ "&page=1"
+ "&pagesize=30"
+ "&userid=-1"
+ "&clientver="
+ "&platform=WebFilter"
+ "&tag=em"
+ "&filter=2"
+ "&iscorrection=1"
+ "&privilege_filter=0"
+ "&_="+System.currentTimeMillis());
//System.out.println(page.getWebResponse().getContentAsString());
//System.out.println(zzee(page.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))"));
JSONObject job=JSONObject.parseObject("{"+zzee(page.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))")+"}").getJSONObject("data");
System.out.println("job:"+job);
JSONArray list=job.getJSONArray("lists");
System.out.println("list"+list);
for(int i=0;i<list.size();i++){
String id1=list.getJSONObject(i).getString("FileHash");
String id2=list.getJSONObject(i).getString("AlbumID");
String detailUrl="http://www.kugou.com/yy/index.php?r=play/getdata"
+ "&hash="+id1
+ "&album_id="+id2
+ "&_="+System.currentTimeMillis();
Page page2=webClient.getPage(detailUrl);
JSONObject job2=JSONObject.parseObject(page2.getWebResponse().getContentAsString()).getJSONObject("data");
System.out.println("标题:"+job2.getString("audio_name"));
//System.out.println("歌词:"+job2.getString("lyrics"));
System.out.println("mp3:"+job2.getString("play_url")); String outImage = job2.getString("audio_name")+ ".mp3";
URL imgUrl = new URL(job2.getString("play_url"));//获取输入流
inputStream = imgUrl.openConnection().getInputStream();
//将输入流信息放入缓冲流提升读写速度
bis = new BufferedInputStream(inputStream);
//读取字节娄
byte[] buf = new byte[1024];
//生成文件
outputStream = new FileOutputStream("f://"+ outImage);
int size = 0;
//边读边写
while ((size = bis.read(buf)) != -1) {
outputStream.write(buf, 0, size);
}
//刷新文件流
outputStream.flush(); }
} catch (Exception e) {
e.printStackTrace();
}
return name; }
private static String zzee(String str, String zz) {
String list = null;
Pattern p = Pattern.compile(zz);
Matcher m = p.matcher(str);
while (m.find()) {
list = m.group();
} return list;
}
public static void main(String[] args) {
WebClient webClient=getWebClient(false);
getMp3Url(webClient);
}
}
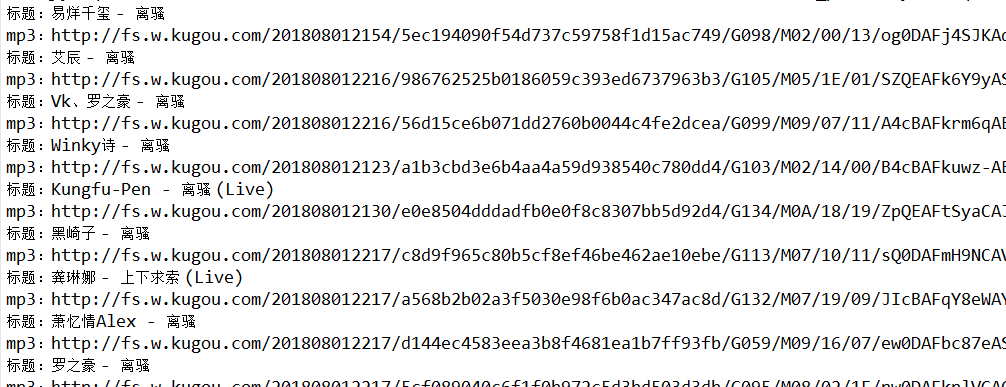
运行结果:
qq音乐抓取实例:
import java.io.BufferedInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLEncoder;
import java.util.UUID;
import java.util.regex.Matcher;
import java.util.regex.Pattern; import org.jsoup.nodes.Element; import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient; public class worm6 {
private static String name="离骚";
static String id1=null;
static String id2=null;
static String id3=null;
static String id4=null;
static String name1=null;
static String name2=null;
static String url = null;
static JSONObject job2=null;
public static WebClient getWebClient(boolean flag){
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_45);
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setAppletEnabled(false);
webClient.getOptions().setJavaScriptEnabled(flag);
webClient.getOptions().setTimeout(60000);
webClient.getOptions().setPrintContentOnFailingStatusCode(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
return webClient;
}
public static String getMp3Url(WebClient webClient){ try {
Page page=webClient.getPage("https://c.y.qq.com/soso/fcgi-bin/client_search_cp?"
+ "ct=24"
+ "&qqmusic_ver=1298"
+ "&new_json=1"
+ "&remoteplace=txt.yqq.center"
+ "&searchid=36047978388657978"
+ "&t=0"
+ "&aggr=1"
+ "&cr=1"
+ "&catZhida=1"
+ "&lossless=0"
+ "&p=1"
+ "&n=20"
+ "&w="+URLEncoder.encode(name, "utf-8")
+ "&g_tk=5381"
+ "&jsonpCallback=MusicJsonCallback6176591962889693"
+ "&loginUin=0"
+ "&hostUin=0"
+ "&format=jsonp"
+ "&inCharset=utf8"
+ "&outCharset=utf-8"
+ "¬ice=0"
+ "&platform=yqq"
+ "&needNewCode=0"
);
//System.out.println("page:"+page);
//System.out.println("------"+page.getWebResponse().getContentAsString());
//System.out.println("======"+zzee(page.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))")); JSONObject job=JSONObject.parseObject("{"+zzee(page.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))")+"}").getJSONObject("data");
//System.out.println("job:"+job);
String job0=job.getString("song");
//System.out.println("job0"+job0);
job=JSON.parseObject(job0);
JSONArray list=job.getJSONArray("list");
//System.out.println("list:"+list);
for(int i=0;i<list.size();i++){
id1=list.getJSONObject(i).getString("mid");
//System.out.println("id1"+id1);
id2=list.getJSONObject(i).getString("file");
//System.out.println("id"+id2);
id2="C400"+JSONObject.parseObject(id2).getString("media_mid")+".m4a";
//System.out.println("id"+id2);
name1=list.getJSONObject(i).getString("title");
name2=list.getJSONObject(i).getString("singer");
//System.out.println(name2);
JSONArray name=JSON.parseArray(name2);
//System.out.println("job4:"+name);
name2=name.getJSONObject(0).getString("name");
//System.out.println(name.getJSONObject(0).getString("name")); /*String detailUrl="https://c.y.qq.com/v8/fcg-bin/fcg_play_single_song.fcg?"
+ "songmid="+id1
+ "&tpl=yqq_song_detail&format=jsonp&callback=getOneSongInfoCallback&g_tk=5381&jsonpCallback=getOneSongInfoCallback&loginUin=0&hostUin=0&format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0"
;
Page page2=webClient.getPage(detailUrl);
//System.out.println(page2);
String b="{"+zzee(page2.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))")+"}";
//System.out.println("b"+b);
JSONObject job1=JSONObject.parseObject("{"+zzee(page2.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))")+"}").getJSONObject("url");
System.out.println("job1:"+job1);
String job2=job1.getString(id2); System.out.println("job2"+job2);*/
String url1="https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg?g_tk=5381&jsonpCallback=MusicJsonCallback32651599216689386&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0&cid=205361747&callback=MusicJsonCallback32651599216689386&uin=0"
+"&songmid="+id1
+"&filename="+id2
+"&guid=2241489759";
;
Page page2=webClient.getPage(url1);
//System.out.println("page2"+page2);
JSONObject job2=JSONObject.parseObject("{"+zzee(page2.getWebResponse().getContentAsString(),"(?<=\\(\\{).*?(?=\\}\\))")+"}").getJSONObject("data");
//System.out.println("标题:"+job2.getString("items"));
String job3=job2.getString("items");
JSONArray job4=JSON.parseArray(job3);
//System.out.println("job4:"+job4);
//System.out.println(job4.getJSONObject(0).getString("vkey"));
url ="http://dl.stream.qqmusic.qq.com/"+id2+"?vkey="+job4.getJSONObject(0).getString("vkey")+"&guid=2241489759&uin=0&fromtag=66";
System.out.println("name:"+name1+"--"+name2);
System.out.println("url:"+url); download();
} } catch (Exception e) {
e.printStackTrace();
}
return name; }
private static String zzee(String str, String zz) {
String list = null;
Pattern p = Pattern.compile(zz);
Matcher m = p.matcher(str);
while (m.find()) {
list = m.group();
} return list;
}
private static void download() throws IOException{
FileOutputStream outputStream = null;
InputStream inputStream = null;
BufferedInputStream bis = null;
String outImage = name1+"--"+name2+ ".mp3";
URL imgUrl = new URL(url);//获取输入流
inputStream = imgUrl.openConnection().getInputStream();
//将输入流信息放入缓冲流提升读写速度
bis = new BufferedInputStream(inputStream);
//读取字节娄
byte[] buf = new byte[1024];
//生成文件
outputStream = new FileOutputStream("f://"+ outImage);
int size = 0;
//边读边写
while ((size = bis.read(buf)) != -1) {
outputStream.write(buf, 0, size);
}
//刷新文件流
outputStream.flush();
}
public static void main(String[] args) {
WebClient webClient=getWebClient(false);
getMp3Url(webClient);
}
}
运行结果: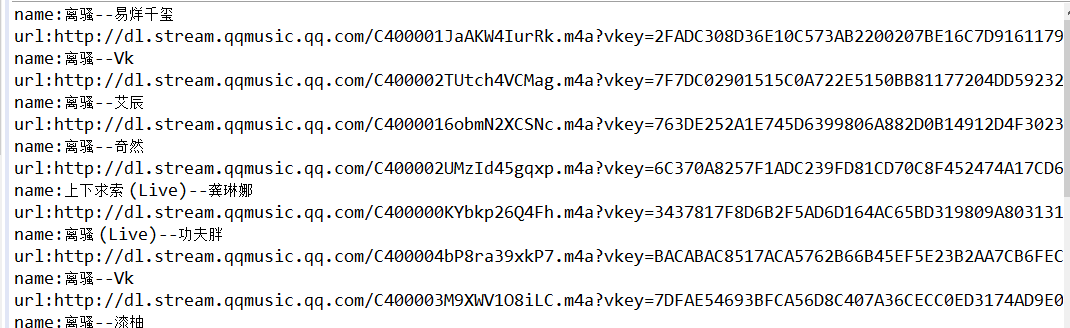
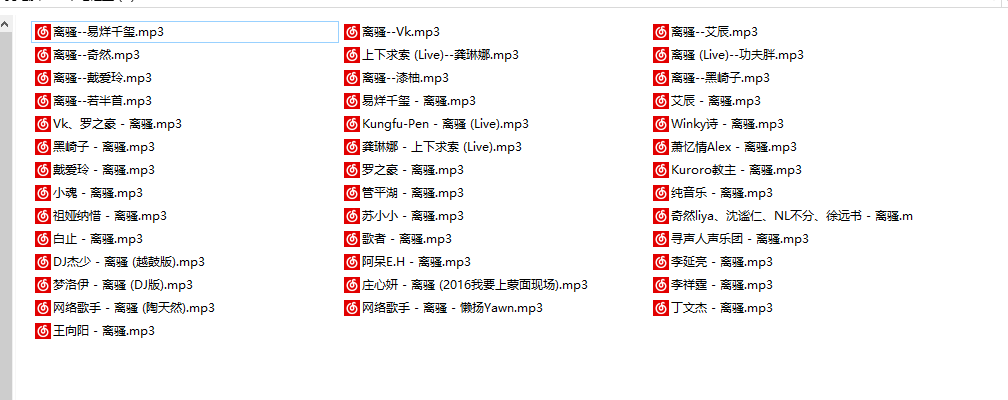
相比之下,酷狗音乐相对好爬一些,QQ音乐有些繁琐。。。
htmlunit+fastjson抓取酷狗音乐 qq音乐链接及下载的更多相关文章
- Python 爬虫-抓取中小企业股份转让系统公司公告的链接并下载
系统运行系统:MAC 用到的python库:selenium.phantomjs等 由于中小企业股份转让系统网页使用了javasvript,无法用传统的requests.BeautifulSoup库获 ...
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- 酷狗、QQ、天天动听——手机音乐播放器竞品对比
如果说什么艺术与人们生活最贴近,那应该属音乐了,因此当代人不离身的手机里必然会有自己喜欢的音乐播放器APP存在. 在当今无论PC端还是手机端音乐播放器都越来越同质化,我们应该选择哪款手机音乐播放器?它 ...
- python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- Python爬取酷狗飙升榜前十首(100)首,写入CSV文件
酷狗飙升榜,写入CSV文件 爬取酷狗音乐飙升榜的前十首歌名.歌手.时间,是一个很好的爬取网页内容的例子,对爬虫不熟悉的读者可以根据这个例子熟悉爬虫是如何爬取网页内容的. 需要用到的库:requests ...
- 【Python】【爬虫】爬取酷狗TOP500
好啦好啦,那我们来拉开我们的爬虫之旅吧~~~ 这一只小爬虫是爬取酷狗TOP500的,使用的爬取手法简单粗暴,目的是帮大家初步窥探爬虫长啥样,后期会慢慢变得健壮起来的. 环境配置 在此之前需要下载一个谷 ...
- 使用Xpath爬取酷狗TOP500的歌曲信息
使用xpath爬取酷狗TOP500的歌曲信息, 将排名.歌手名.歌曲名.歌曲时长,提取的结果以文件形式保存下来.参考网址:http://www.kugou.com/yy/rank/home/1-888 ...
- python爬取酷狗音乐
url:https://www.kugou.com/yy/html/rank.html 我们随便访问一个歌曲可以看到url有个hash https://www.kugou.com/song/#hash ...
随机推荐
- vue项目上传Github预览
最近在用Vue仿写cnode社区,想要上传到github,并通过Github pages预览,在这个过程中遇到了一些问题,因此写个笔记,以便查阅. 完成Vue项目以后,在上传到github之前,需要修 ...
- bugku web 管理员系统
页面是一个登陆表单,需要账号密码,首先f12查看源代码,发现有一段可疑的注释,明显是base64,解码得到test123,似乎是一个类似于密码的东西,既然是管理员,就猜测用户名是admin,填上去试一 ...
- [搬运] 将 Visual Studio 的代码片段导出到 VS Code
原文 : A Visual Studio to Visual Studio Code Snippet Converter 作者 : Rick Strahl 译者 : 张蘅水 导语 和原文作者一样,水弟 ...
- Centos 6.5下mysql 8.0.11的rpm包的安装方式
1.系统版本及mysql下载地址 操作系统:Centos 6.5(Centos 7.4下载对应的mysql版本安装同理) mysql数据库版本:mysql8.0.11 mysql官方网站:http:/ ...
- Linux下MySql的登陆和管理操作
一.mysql数据库启停1.linux下启动mysql的命令: mysqladmin start/ect/init.d/mysql start (前面为mysql的安装路径)2.linux下重启 ...
- Vscode生成verilog例化
前言 手动例化又慢又容易出错,孩子老犯错怎么办? 当然是脚本一劳永逸. 流程 (1)在vscode中安装如下插件. (2)在电脑中安装python3以上的环境. 下载地址:https://www.py ...
- 【CF715E】Complete the Permutations 第一类斯特林数
题目大意 有两个排列 \(p,q\),其中有一些位置是空的. 你要补全这两个排列. 定义 \(s(p,q)\) 为 每次交换 \(p\) 中的两个数,让 \(p=q\) 的最小操作次数. 求 \(s( ...
- Luogu3768简单的数学题
题目描述 题解 我们在一通化简上面的式子之后得到了这么个东西. 前面的可以除法分块做,后面的∑T2∑dµ(T/d)是积性函数,可以线性筛. 然后这个数据范围好像不太支持线性筛,所以考虑杜教筛. 后面那 ...
- CF1152E Neko and Flashback--欧拉路径
RemoteJudge 第一次见到欧拉路径的题 注意到\(b\)和\(c\)的构造方法很特殊,即对于一个位置(经过\(p\)作用后)\(i\),若两个数分别为\(b_i\)和\(c_i\),那么在\( ...
- linux系统中日常运维常用命令汇总一
一.查看日志和机器相关信息常用命令 1.cat cat 命令连接文件并打印到标准输出设备上,cat经常用来显示文件的内容,类似于下的type命令注意:当文件较大时,文本在屏幕上迅速闪过(滚屏),用户往 ...