[Python数据挖掘]第5章、挖掘建模(上)
一、分类和回归

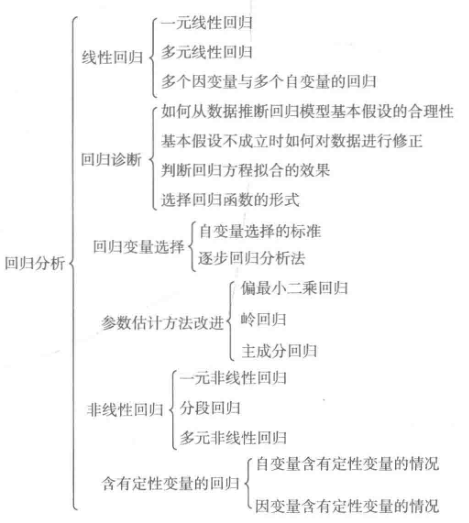
回归分析研究的范围大致如下:
1、逻辑回归

#逻辑回归 自动建模
import pandas as pd
from sklearn.linear_model import LogisticRegression as LR
from sklearn.linear_model import RandomizedLogisticRegression as RLR #参数初始化
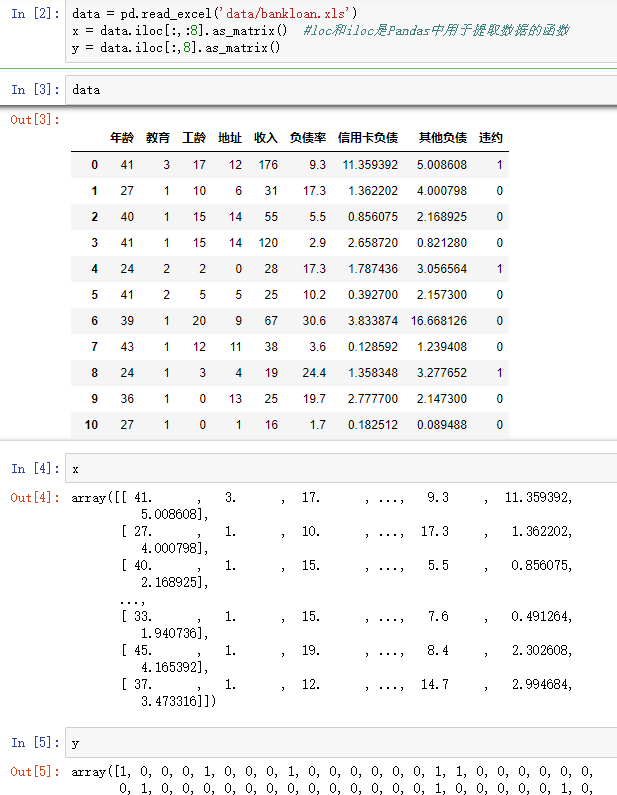
data = pd.read_excel('data/bankloan.xls')
x = data.iloc[:,:8].as_matrix() #loc和iloc是Pandas中用于提取数据的函数
y = data.iloc[:,8].as_matrix()
#复制一份,用作对比
x1=x
y1=y rlr = RLR() #建立随机逻辑回归模型,筛选变量
rlr.fit(x, y) #训练模型
rlr.get_support() #获取特征筛选结果,也可以通过.scores_方法获取各个特征的分数
print(u'通过随机逻辑回归模型筛选特征结束。')
print(u'有效特征为:%s' % ','.join(data.iloc[:,0:8].columns[rlr.get_support()])) #原代码此处报错
x = data[data.iloc[:,0:8].columns[rlr.get_support()]].as_matrix() #筛选好特征 lr = LR() #建立逻辑回归模型
lr.fit(x, y) #用筛选后的特征数据来训练模型
print(u'逻辑回归模型训练结束。')
print(u'筛选特征后,模型的平均正确率为:%s' % lr.score(x, y)) #给出模型的平均正确率,本例为81.4% lr1 = LR()
lr1.fit(x1, y1) #直接用原始数据来训练模型
print(u'未筛选特征,模型的平均正确率为:%s' % lr1.score(x1, y1))
通过随机逻辑回归模型筛选特征结束。
有效特征为:工龄,地址,负债率,信用卡负债
逻辑回归模型训练结束。
筛选特征后,模型的平均正确率为:0.814285714286
未筛选特征,模型的平均正确率为:0.805714285714
2、决策树

#使用ID3决策树算法预测销量高低
import pandas as pd #参数初始化
data = pd.read_excel('data/sales_data.xls', index_col = '序号') #导入数据 #数据是类别标签,要将它转换为数据
#用1来表示“好”、“是”、“高”这三个属性,用-1来表示“坏”、“否”、“低”
data.replace(['好','是','高','坏','否','低'],[1,1,1,-1,-1,-1],inplace=True)
x = data.iloc[:,:3]
y = data.iloc[:,3] from sklearn.tree import DecisionTreeClassifier as DTC
dtc = DTC(criterion='entropy') #建立决策树模型,基于信息熵
dtc.fit(x, y) #训练模型 #导入相关函数,可视化决策树。
#导出的结果是一个dot文件,需要安装Graphviz才能将它转换为pdf或png等格式。
from sklearn.tree import export_graphviz
x = pd.DataFrame(x)
from sklearn.externals.six import StringIO
x = pd.DataFrame(x)
with open("tree.dot", 'w') as f:
f = export_graphviz(dtc, feature_names = x.columns, out_file = f)
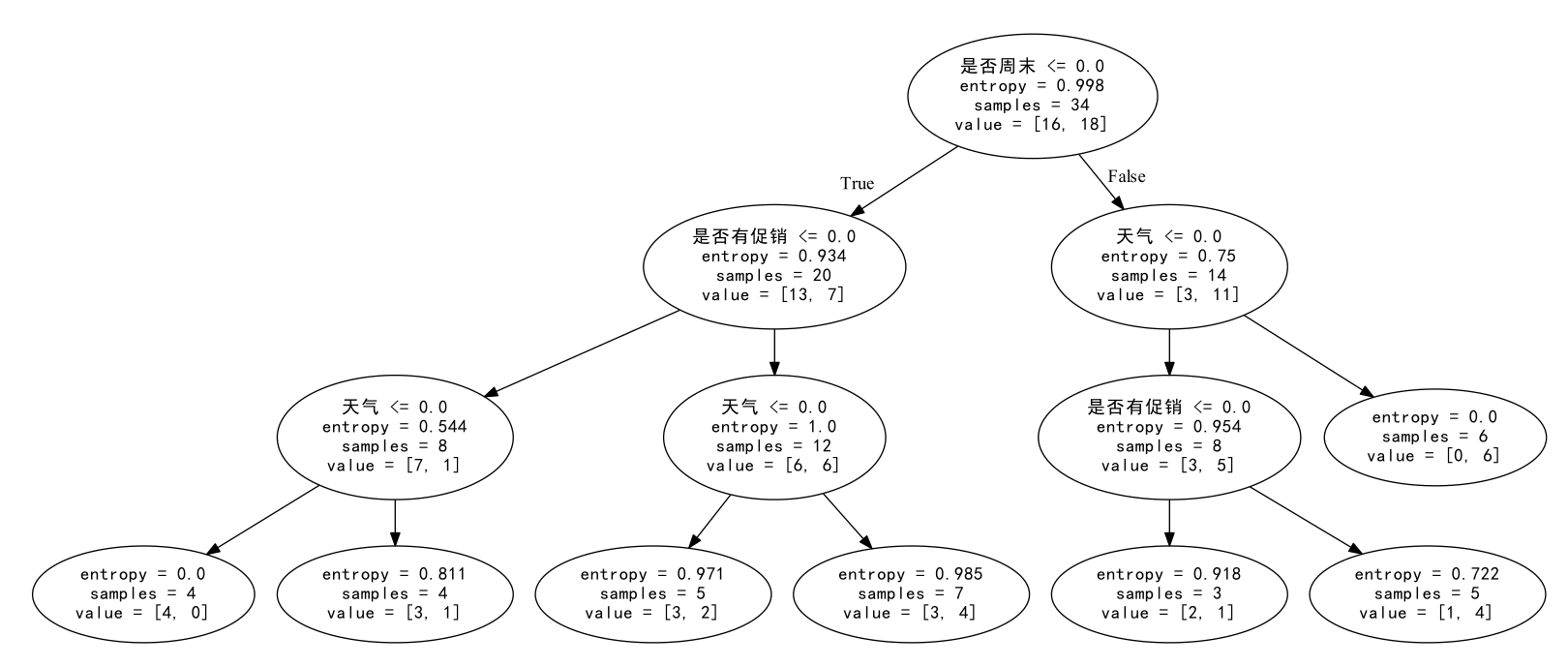
运行上述代码,生成tree.dot文件,对其稍作修改
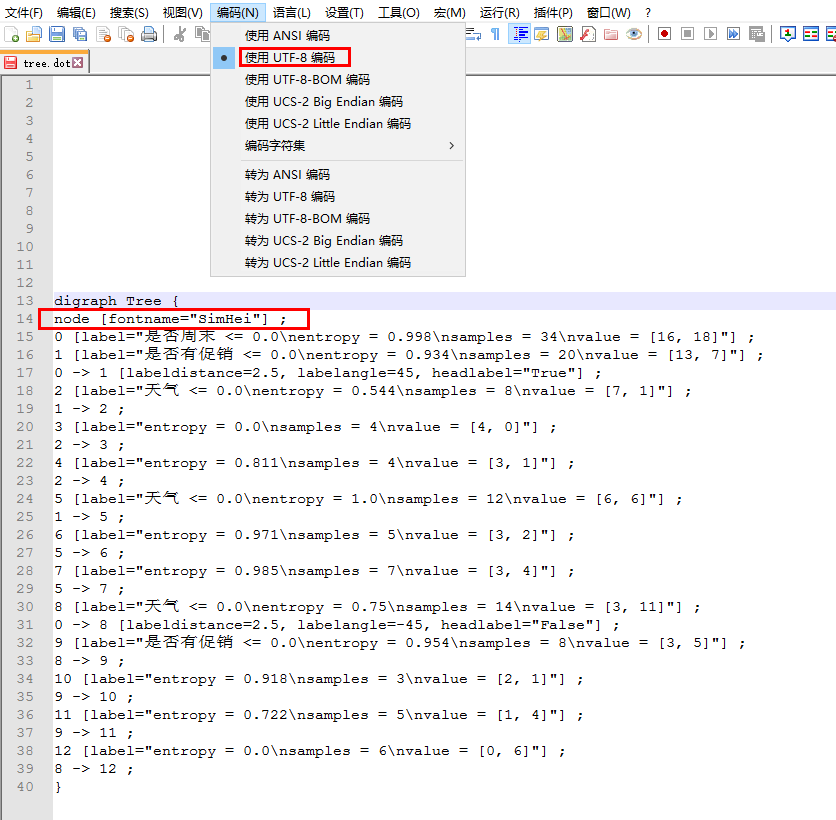
得到决策树的可视化
3、人工神经网络



#使用神经网络算法预测销量高低
import pandas as pd
from sklearn.metrics import confusion_matrix #导入混淆矩阵函数
import matplotlib.pyplot as plt #导入作图库
from keras.models import Sequential
from keras.layers.core import Dense, Activation #作图函数
def cm_plot(y, yp):
cm = confusion_matrix(y, yp) #混淆矩阵
plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。
plt.colorbar() #颜色标签 for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center') plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
return plt #参数初始化
data = pd.read_excel('data/sales_data.xls', index_col = '序号') #导入数据 #数据是类别标签,要将它转换为数据
#用1来表示“好”、“是”、“高”这三个属性,用0来表示“坏”、“否”、“低”
data.replace(['好','是','高','坏','否','低'],[1,1,1,0,0,0],inplace=True)
x = data.iloc[:,:3]
y = data.iloc[:,3] model = Sequential() #建立模型
model.add(Dense(input_dim = 3, output_dim = 10))
model.add(Activation('relu')) #用relu函数作为激活函数,能够大幅提供准确度
model.add(Dense(input_dim = 10, output_dim = 1))
model.add(Activation('sigmoid')) #由于是0-1输出,用sigmoid函数作为激活函数 model.compile(loss = 'binary_crossentropy', optimizer = 'adam')
#编译模型。由于我们做的是二元分类,所以我们指定损失函数为binary_crossentropy,以及模式为binary
#另外常见的损失函数还有mean_squared_error、categorical_crossentropy等,请阅读帮助文件。
#求解方法我们指定用adam,还有sgd、rmsprop等可选 model.fit(x, y, nb_epoch = 1000, batch_size = 10) #训练模型,学习一千次
yp = model.predict_classes(x).reshape(len(y)) #分类预测 cm_plot(y,yp).show() #显示混淆矩阵可视化结果

二、评价指标

Accuracy表示你有多少比例的样本预测对了
Precision表示你预测为正的样本中有多少预测对了,又称为查准率
Recall表示真实标签为正的样本有多少被你预测对了,又称为查全率
三、聚类分析


#-*- coding: utf-8 -*-
#使用K-Means算法聚类消费行为特征数据
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans #参数初始化
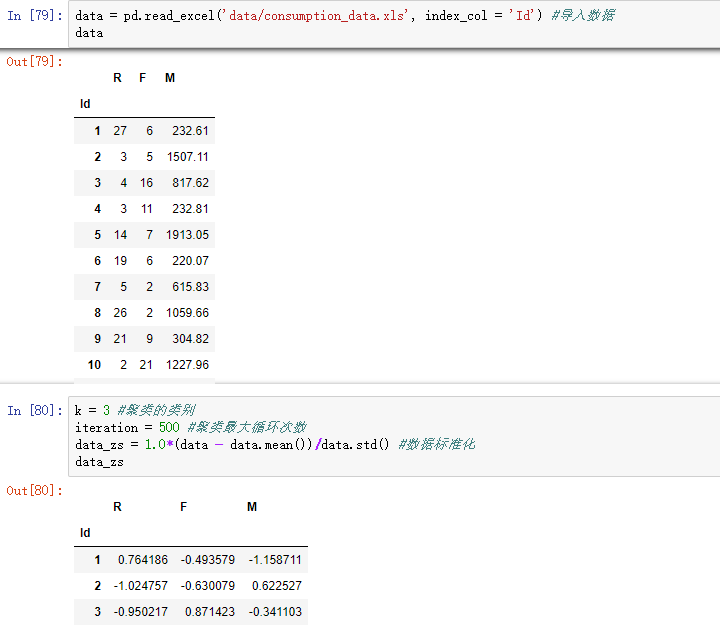
data = pd.read_excel('data/consumption_data.xls', index_col = 'Id') #读取数据
outputfile = 'tmp/data_type.xls' #保存结果的文件名 k = 3 #聚类的类别
iteration = 500 #聚类最大循环次数
data_zs = 1.0*(data - data.mean())/data.std() #数据标准化 model = KMeans(n_clusters = k, n_jobs = 4, max_iter = iteration) #分为k类,并发数4
model.fit(data_zs) #开始聚类 #简单打印结果
r1 = pd.Series(model.labels_).value_counts() #统计各个类别的数目
r2 = pd.DataFrame(model.cluster_centers_) #找出聚类中心
r = pd.concat([r2, r1], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(data.columns) + [u'类别数目'] #重命名表头
print(r) #详细输出原始数据及其类别
r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #详细输出每个样本对应的类别
r.columns = list(data.columns) + [u'聚类类别'] #重命名表头
r.to_excel(outputfile) #保存结果 def density_plot(data,title): #自定义作图函数
plt.figure()
for i in range(len(data.iloc[0])):#逐列作图
(data.iloc[:,i]).plot(kind='kde', label=data.columns[i],linewidth = 2)
plt.ylabel('密度')
plt.xlabel('人数')
plt.title('聚类类别%s各属性的密度曲线'%title)
plt.legend()
return plt def density_plot(data): #自定义作图函数
p = data.plot(kind='kde', linewidth = 2, subplots = True, sharex = False)
[p[i].set_ylabel(u'密度') for i in range(k)]
plt.legend()
return plt pic_output = 'tmp/pd_' #概率密度图文件名前缀
for i in range(k):
density_plot(data[r[u'聚类类别']==i]).savefig(u'%s%s.png' %(pic_output, i))
聚类效果评价

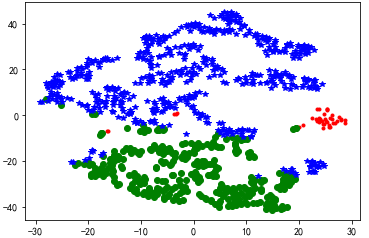
聚类可视化工具——TSNE(在2维或3维空间展示聚类效果)
#代码接上面
from sklearn.manifold import TSNE tsne = TSNE()
tsne.fit_transform(data_zs) #进行数据降维
tsne = pd.DataFrame(tsne.embedding_, index = data_zs.index) #转换数据格式 #不同类别用不同颜色和样式绘图
d = tsne[r[u'聚类类别'] == 0]
plt.plot(d[0], d[1], 'r.')
d = tsne[r[u'聚类类别'] == 1]
plt.plot(d[0], d[1], 'go')
d = tsne[r[u'聚类类别'] == 2]
plt.plot(d[0], d[1], 'b*')
plt.show()
[Python数据挖掘]第5章、挖掘建模(上)的更多相关文章
- [Python数据挖掘]第5章、挖掘建模(下)
四.关联规则 Apriori算法代码(被调函数部分没怎么看懂) from __future__ import print_function import pandas as pd #自定义连接函数,用 ...
- [Python数据挖掘]第8章、中医证型关联规则挖掘
一.背景和挖掘目标 二.分析方法与过程 1.数据获取 2.数据预处理 1.筛选有效问卷(根据表8-6的标准) 共发放1253份问卷,其中有效问卷数为930 2.属性规约 3.数据变换 ''' 聚类 ...
- [Python数据挖掘]第6章、电力窃漏电用户自动识别
一.背景与挖掘目标 相关背景自查 二.分析方法与过程 1.EDA(探索性数据分析) 1.分布分析 2.周期性分析 2.数据预处理 1.数据清洗 过滤非居民用电数据,过滤节假日用电数据(节假日用电量明显 ...
- [Python数据挖掘]第7章、航空公司客户价值分析
一.背景和挖掘目标 二.分析方法与过程 客户价值识别最常用的是RFM模型(最近消费时间间隔Recency,消费频率Frequency,消费金额Monetary) 1.EDA(探索性数据分析) #对数据 ...
- [Python数据挖掘]第4章、数据预处理
数据预处理主要包括数据清洗.数据集成.数据变换和数据规约,处理过程如图所示. 一.数据清洗 1.缺失值处理:删除.插补.不处理 ## 拉格朗日插值代码(使用缺失值前后各5个未缺失的数据建模) impo ...
- [Python数据挖掘]第2章、Python数据分析简介
<Python数据分析与挖掘实战>的数据和代码,可从“泰迪杯”竞赛网站(http://www.tipdm.org/tj/661.jhtml)下载获得 1.Python数据结构 2.Nump ...
- [Python数据挖掘]第3章、数据探索
1.缺失值处理:删除.插补.不处理 2.离群点分析:简单统计量分析.3σ原则(数据服从正态分布).箱型图(最好用) 离群点(异常值)定义为小于QL-1.5IQR或大于Qu+1.5IQR import ...
- ROS机器人程序设计(原书第2版)补充资料 (柒) 第七章 3D建模与仿真 urdf Gazebo V-Rep Webots Morse
ROS机器人程序设计(原书第2版)补充资料 (柒) 第七章 3D建模与仿真 urdf Gazebo V-Rep Webots Morse 书中,大部分出现hydro的地方,直接替换为indigo或ja ...
- 2019年Python数据挖掘就业前景前瞻
Python语言的崛起让大家对web.爬虫.数据分析.数据挖掘等十分感兴趣.数据挖掘就业前景怎么样?关于这个问题的回答,大家首先要知道什么是数据挖掘.所谓数据挖掘就是指从数据库的大量数据中揭示出隐含的 ...
随机推荐
- BZOJ 1053 - 反素数ant - [数论+DFS][HAOI2007]
题目链接:https://www.lydsy.com/JudgeOnline/problem.php?id=1053 题解: 可以证明,$1 \sim N$ 中最大的反质数,就是 $1 \sim N$ ...
- 如何用anysend发wirshark的报文
可以复制 抓包的的报文的 hex txt文档 粘贴到 anysend 继续发送
- 推送测试,生产环境无法打印log获取deviceToken,可以通过弹窗获取deviceToken
z- (void)application:(UIApplication *)application didRegisterForRemoteNotificationsWithDeviceToken:( ...
- ant 执行jmeter脚本
环境准备 1.jdk版本:java version "1.8.0_201" 2.jmeter版本:5.0 3.ant版本:Apache Ant(TM) version 1.10.5 ...
- 775. Global and Local Inversions
We have some permutation A of [0, 1, ..., N - 1], where N is the length of A. The number of (global) ...
- 【Python】This inspection detects names that should resolve but don't. Due to dynamic dispatch and duck
情况一:导包import时发生错误,请参考这两位 https://blog.csdn.net/zhangyu4863/article/details/80212068https://www.cnblo ...
- Xamarin.Forms 未能找到路径“x:\platforms”的一部分
https://stackoverflow.com/questions/45500269/xamarin-android-common-targets-error-could-not-find-a-p ...
- C#设计模式(13)——代理模式(Proxy Pattern)(转)
一.引言 在软件开发过程中,有些对象有时候会由于网络或其他的障碍,以至于不能够或者不能直接访问到这些对象,如果直接访问对象给系统带来不必要的复杂性,这时候可以在客户端和目标对象之间增加一层中间层,让代 ...
- Qt QDateEdit QDateTimeEdit
展示一个效果,然后附上一个“笑话~~”...回想起来都是搞笑的. 笑话来了,,,,几个月前,为了做出时间选择界面,我亲自“创造”了一个...今天发现了QDateEdit的属性CalendarPopup ...
- laravel----------Client error: `POST http://47.98.116.219/oauth/token` resulted in a `401 Unauthorized` response: {"error":"invalid_client","message":"Client authentication failed"}
1.设备没有授权,原因是 这个client_id的值就是数据库wk_oauth_clients 的主键ID,查看下表是否有这条数据