利用phpspider爬取网站数据
本文实例原址:PHPspider爬虫10分钟快速教程
在我们的工作中可能会涉及到要到其它网站去进行数据爬取的情况,我们这里使用phpspider这个插件来进行功能实现。
1、首先,我们需要php环境,这点不用说。
2、安装composer,这个网上教程很多,这里不多做赘述,一面显得篇幅太长。
3、利用composer进行phpspider安装。
在安装的过程中,我们可能会遇到composer require长时间没反应的情况,这样的话。我们就需要换到中国镜像。方法如下:
镜像配置好后,我们就进行phpspider的安装了。
新建一个文件夹,这里暂时取名为composerInstallDemo。
打开文件夹,并在文件夹地址栏中输入“cmd”直接进入该文件夹的cmd模式。

再在dos窗口中输入一下命令:
composer require owner888/phpspider
出现一下界面,则证明,phpspider已经安装成功。

4、编写自己的第一个爬虫程序。
打开composerInstallDemo文件夹,在文件夹下新建一个php文件(名字随意,这里我创建的是index.php)
<?php
require '/vendor/autoload.php';
use phpspider\core\phpspider;
/* Do NOT delete this comment */
/* 不要删除这段注释 */
$configs = array(
'name' => '简书',
'log_show' =>false,
'tasknum' => 1,
//数据库配置
'db_config' => array(
'host' => '127.0.0.1',
'port' => 3306,
'user' => 'root',
'pass' => '',
'name' => 'demo',
),
'export' => array(
'type' => 'db',
'table' => 'jianshu', // 如果数据表没有数据新增请检查表结构和字段名是否匹配
),
//爬取的域名列表
'domains' => array(
'jianshu',
'www.jianshu.com'
),
//抓取的起点
'scan_urls' => array(
'https://www.jianshu.com/c/V2CqjW?utm_medium=index-collections&utm_source=desktop'
),
//列表页实例
'list_url_regexes' => array(
"https://www.jianshu.com/c/\d+"
),
//内容页实例
// \d+ 指的是变量
'content_url_regexes' => array(
"https://www.jianshu.com/p/\d+",
),
'max_try' => 5,
'fields' => array(
array(
'name' => "title",
'selector' => "//h1[@class='title']",
'required' => true,
),
array(
'name' => "content",
'selector' => "//div[@class='show-content-free']",
'required' => true,
),
),
);
$spider = new phpspider($configs);
$spider->start();
稍微解释一下一下句法的含义:
//h1[@class='title']
获取所有class值为title的h1节点
//div[@class='show-content-free']
获取所有class值为show-content-free的div节点
具体为什么这么写呢?自己看简书的html源码吧。
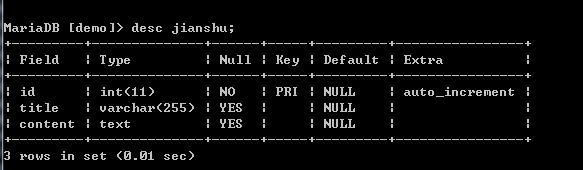
打完代码后,记得根据要抓取的内容建立对应的数据库、数据表,字段要能对对上。
数据库如下:
利用phpspider爬取网站数据的更多相关文章
- 利用linux curl爬取网站数据
看到一个看球网站的以下截图红色框数据,想爬取下来,通常爬取网站数据一般都会从java或者python爬取,但本人这两个都不会,只会shell脚本,于是硬着头皮试一下用shell爬取,方法很笨重,但旨在 ...
- Python 利用 BeautifulSoup 爬取网站获取新闻流
0. 引言 介绍下 Python 用 Beautiful Soup 周期性爬取 xxx 网站获取新闻流: 图 1 项目介绍 1. 开发环境 Python: 3.6.3 BeautifulSoup: ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- C# 关于爬取网站数据遇到csrf-token的分析与解决
需求 某航空公司物流单信息查询,是一个post请求.通过后台模拟POST HTTP请求发现无法获取页面数据,通过查看航空公司网站后,发现网站使用避免CSRF攻击机制,直接发挥40X错误. 关于CSRF ...
- 手把手教你用Node.js爬虫爬取网站数据
个人网站 https://iiter.cn 程序员导航站 开业啦,欢迎各位观众姥爷赏脸参观,如有意见或建议希望能够不吝赐教! 开始之前请先确保自己安装了Node.js环境,还没有安装的的童鞋请自行百度 ...
- Node爬取网站数据
npm安装cheerio和axios npm isntall cheerio npm install axios 利用cheerio抓取对应网站中的标签根据链接使用axios获取对应页面数据 cons ...
- 3.15学习总结(Python爬取网站数据并存入数据库)
在官网上下载了Python和PyCharm,并在网上简单的学习了爬虫的相关知识. 结对开发的第一阶段要求: 网上爬取最新疫情数据,并存入到MySql数据库中 在可视化显示数据详细信息 项目代码: im ...
- 使用node.js如何爬取网站数据
数据库又不会弄,只能扒扒别人的数据了. 搭建环境: (1).创建一个文件夹,进入并初始化一个package.json文件. npm init -y (2).安装相关依赖: npm install ...
随机推荐
- convert(varchar(10),字段名,转换格式
sql 时间转换格式 ) convert(varchar(10),字段名,转换格式) CONVERT(nvarchar(10),count_time,121)CONVERT为日期转换函数,一般就是在时 ...
- Linux命令 at cron
at: 可以处理仅执行一次就结束排程的指令.需要atd服务 crontab: 所设定的指令将会循环地一直进行下去.需要crontab服务 at: Ubuntu16.04 默认没有安装atd服务.安装命 ...
- SQL语句之on子句过滤和where子句过滤区别
1.测试数据: SQL> select * from dept; DEPTNO DNAME LOC ------ -------------- ------------- ...
- Python读取xlsx翻译文案
首先安装Python,然后安装模块 //查找模块(非必须) pip search xlrd //安装模块 pip install xlrd 由于输出要是utf-8所以需要设置默认环境为utf-8 # ...
- PHP Xdebug + PhpStorm调试远程服务器代码
1.服务器(linux centos)安装xdebug pecl install xdebug 注意看安装完成之后会显示 debug.so 的路径,记录下来 2.配置 php.ini如果不知道php. ...
- 使用vue-cli3搭建一个项目
前面说过用vue-cli3快速开发原型的搭建,下面来说一下搭建一个完整的项目 首先我们可以输入命令(创建一个项目名为test的项目) vue create test 输完这个命令后,会让你选择配置项, ...
- html转markdown网站
戳下面的链接,可以直接复制富文本粘贴编程markdown: https://euangoddard.github.io/clipboard2markdown/
- CF1093F Vasya and Array
题目链接:洛谷 以后还是要多打CF,不然就会错过这些很好的思维题了.我dp学得还是太烂,要多总结. 首先$len=1$就直接输出0. 我们考虑$dp[i][j]$表示前$i$个数的答案,而且第$i$个 ...
- MYSQL 比较集
1.什么是较对集合:字符集的字符比较规则(collation,collate),一个字符集有多个较对集合. mysql> create table ss (id int primary key ...
- ASA failover --AA
1.A/A Failover 介绍 安全设备可以成对搭配成A/A的FO来提供设备级的冗余和负载分担. 两个设备在互为备份的同时,也能同时转发流量. 使用虚拟子防火墙是必须的,子防火墙被归为两个FO组 ...