使用 Spark SQL 高效地读写 HBase
Apache Spark 和 Apache HBase 是两个使用比较广泛的大数据组件。很多场景需要使用 Spark 分析/查询 HBase 中的数据,而目前 Spark 内置是支持很多数据源的,其中就包括了 HBase,但是内置的读取数据源还是使用了 TableInputFormat 来读取 HBase 中的数据。这个 TableInputFormat 有一些缺点:
- 一个 Task 里面只能启动一个 Scan 去 HBase 中读取数据;
- TableInputFormat 中不支持 BulkGet;
- 不能享受到 Spark SQL 内置的 catalyst 引擎的优化。
基于这些问题,来自 Hortonworks 的工程师们为我们带来了全新的 Apache Spark—Apache HBase Connector,下面简称 SHC。通过这个类库,我们可以直接使用 Spark SQL 将 DataFrame 中的数据写入到 HBase 中;而且我们也可以使用 Spark SQL 去查询 HBase 中的数据,在查询 HBase 的时候充分利用了 catalyst 引擎做了许多优化,比如分区修剪(partition pruning),列修剪(column pruning),谓词下推(predicate pushdown)和数据本地性(data locality)等等。因为有了这些优化,通过 Spark 查询 HBase 的速度有了很大的提升。
注意:SHC 同时还提供了将 DataFrame 中的数据直接写入到 HBase 中,但是整个代码并没有什么优化的地方,所以本文对这部分不进行介绍。感兴趣的读者可以直接到这里查看相关写数据到 HBase 的代码。
SHC 是如何实现查询优化的呢
SHC 主要使用下面的几种优化,使得 Spark 获取 HBase 的数据扫描范围得到减少,提高了数据读取的效率。
将使用 Rowkey 的查询转换成 get 查询
我们都知道,HBase 中使用 Get 查询的效率是非常高的,所以如果查询的过滤条件是针对 RowKey 进行的,那么我们可以将它转换成 Get 查询。为了说明这点,我们使用下面的例子进行说明。假设我们定义好的 HBase catalog 如下:
val catalog = s"""{ |"table":{"namespace":"default", "name":"iteblog", "tableCoder":"PrimitiveType"}, |"rowkey":"key", |"columns":{ |"col0":{"cf":"rowkey", "col":"id", "type":"int"}, |"col1":{"cf":"cf1", "col":"col1", "type":"boolean"}, |"col2":{"cf":"cf2", "col":"col2", "type":"double"}, |"col3":{"cf":"cf3", "col":"col3", "type":"float"}, |"col4":{"cf":"cf4", "col":"col4", "type":"int"}, |"col5":{"cf":"cf5", "col":"col5", "type":"bigint"}, |"col6":{"cf":"cf6", "col":"col6", "type":"smallint"}, |"col7":{"cf":"cf7", "col":"col7", "type":"string"}, |"col8":{"cf":"cf8", "col":"col8", "type":"tinyint"} |}|}""".stripMargin |
那么如果有类似下面的查询
val df = withCatalog(catalog)df.createOrReplaceTempView("iteblog_table")sqlContext.sql("select * from iteblog_table where id = 1")sqlContext.sql("select * from iteblog_table where id = 1 or id = 2")sqlContext.sql("select * from iteblog_table where id in (1, 2)") |
因为查询条件直接是针对 RowKey 进行的,所以这种情况直接可以转换成 Get 或者 BulkGet 请求的。第一个 SQL 查询过程类似于下面过程
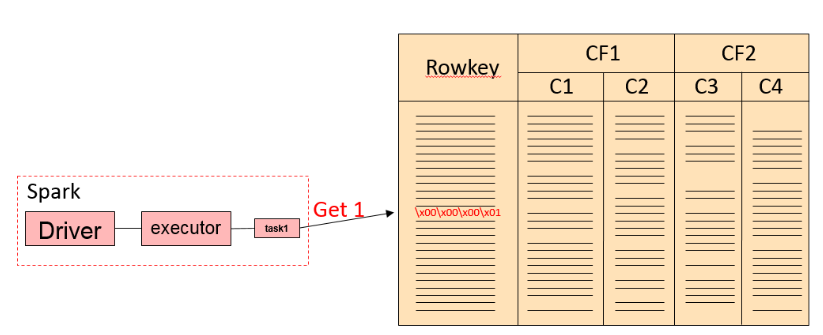
后面两条 SQL 查询其实是等效的,在实现上会把 key in (x1, x2, x3..) 转换成 (key == x1) or (key == x2) or ... 的。整个查询流程如下:
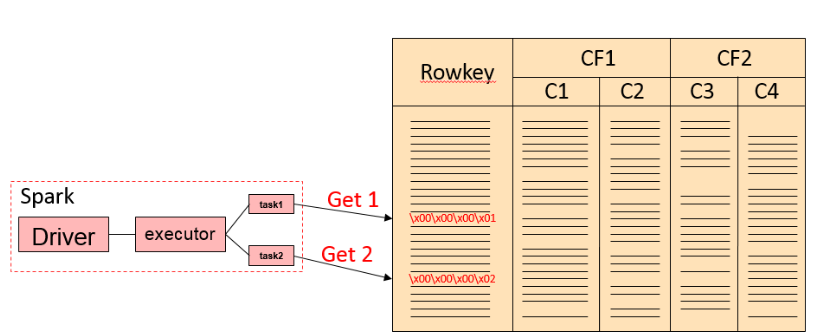
如果我们的查询里面有 Rowkey 还有其他列的过滤,比如下面的例子
sqlContext.sql("select id, col6, col8 from iteblog_table where id = 1 and col7 = 'xxx'") |
那么上面的 SQL 翻译成 HBase 的下面查询
val filter = new SingleColumnValueFilter( Bytes.toBytes("cf7"), Bytes.toBytes("col7 ") CompareOp.EQUAL, Bytes.toBytes("xxx"))val g = new Get(Bytes.toBytes(1))g.addColumn(Bytes.toBytes("cf6"), Bytes.toBytes("col6"))g.addColumn(Bytes.toBytes("cf8"), Bytes.toBytes("col8"))g.setFilter(filter) |
如果有多个 and 条件,都是使用 SingleColumnValueFilter 进行过滤的,这个都好理解。如果我们有下面的查询
sqlContext.sql("select id, col6, col8 from iteblog_table where id = 1 or col7 = 'xxx'") |
那么在 shc 里面是怎么进行的呢?事实上,如果碰到非 RowKey 的过滤,那么这种查询是需要扫描 HBase 的全表的。上面的查询在 shc 里面就是将 HBase 里面的所有数据拿到,然后传输到 Spark ,再通过 Spark 里面进行过滤,可见 shc 在这种情况下效率是很低下的。
def or[T](left: HRF[T], right: HRF[T])(implicit ordering: Ordering[T]): HRF[T] = { val ranges = ScanRange.or(left.ranges, right.ranges) val typeFilter = TypedFilter.or(left.tf, right.tf) HRF(ranges, typeFilter, left.handled && right.handled)} |
同理,类似于下面的查询在 shc 里面其实都是全表扫描,并且将所有的数据返回到 Spark 层面上再进行一次过滤。
sqlContext.sql("select id, col6, col8 from iteblog_table where id = 1 or col7 <= 'xxx'")sqlContext.sql("select id, col6, col8 from iteblog_table where id = 1 or col7 >= 'xxx'")sqlContext.sql("select id, col6, col8 from iteblog_table where col7 = 'xxx'") |
很显然,这种方式查询效率并不高,一种可行的方案是将算子下推到 HBase 层面,在 HBase 层面通过 SingleColumnValueFilter 过滤一部分数据,然后再返回到 Spark,这样可以节省很多数据的传输。
组合 RowKey 的查询优化
shc 还支持组合 RowKey 的方式来建表,具体如下:
def cat = s"""{ |"table":{"namespace":"default", "name":"iteblog", "tableCoder":"PrimitiveType"}, |"rowkey":"key1:key2", |"columns":{ |"col00":{"cf":"rowkey", "col":"key1", "type":"string", "length":"6"}, |"col01":{"cf":"rowkey", "col":"key2", "type":"int"}, |"col1":{"cf":"cf1", "col":"col1", "type":"boolean"}, |"col2":{"cf":"cf2", "col":"col2", "type":"double"}, |"col3":{"cf":"cf3", "col":"col3", "type":"float"}, |"col4":{"cf":"cf4", "col":"col4", "type":"int"}, |"col5":{"cf":"cf5", "col":"col5", "type":"bigint"}, |"col6":{"cf":"cf6", "col":"col6", "type":"smallint"}, |"col7":{"cf":"cf7", "col":"col7", "type":"string"}, |"col8":{"cf":"cf8", "col":"col8", "type":"tinyint"} |} |}""".stripMargin |
上面的 col00 和 col01 两列组合成一个 rowkey,并且 col00 排在前面,col01 排在后面。比如 col00 ='row002',col01 = 2,那么组合的 rowkey 为 row002\x00\x00\x00\x02。那么在组合 Rowkey 的查询 shc 都有哪些优化呢?现在我们有如下查询
df.sqlContext.sql("select col00, col01, col1 from iteblog where col00 = 'row000' and col01 = 0").show() |
根据上面的信息,RowKey 其实是由 col00 和 col01 组合而成的,那么上面的查询其实可以将 col00 和 col01 进行拼接,然后组合成一个 RowKey,然后上面的查询其实可以转换成一个 Get 查询。但是在 shc 里面,上面的查询是转换成一个 scan 和一个 get 查询的。scan 的 startRow 为 row000,endRow 为 row000\xff\xff\xff\xff;get 的 rowkey 为 row000\xff\xff\xff\xff,然后再将所有符合条件的数据返回,最后再在 Spark 层面上做一次过滤,得到最后查询的结果。因为 shc 里面组合键查询的代码还没完善,所以当前实现应该不是最终的。
在 shc 里面下面两条 SQL 查询下沉到 HBase 的逻辑一致
df.sqlContext.sql("select col00, col01, col1 from iteblog where col00 = 'row000'").show()df.sqlContext.sql("select col00, col01, col1 from iteblog where col00 = 'row000' and col01 = 0").show() |
唯一区别是在 Spark 层面上的过滤。
scan 查询优化
如果我们的查询有 < 或 > 等查询过滤条件,比如下面的查询条件:
df.sqlContext.sql("select col00, col01, col1 from iteblog where col00 > 'row000' and col00 < 'row005'").show() |
这个在 shc 里面转换成 HBase 的过滤为一条 get 和 一个 scan,具体为 get 的 Rowkey 为 row0005\xff\xff\xff\xff;scan 的 startRow 为 row000,endRow 为 row005\xff\xff\xff\xff,然后将查询的结果返回到 spark 层面上进行过滤。
总体来说,shc 能在一定程度上对查询进行优化,避免了全表扫描。但是经过评测,shc 其实还有很多地方不够完善,算子下沉并没有下沉到 HBase 层面上进行。目前这个项目正在和 hbase 自带的 connectors 进行整合(https://github.com/apache/hbase-connectors),相关 issue 参见 Enhance the current spark-hbase connector。
使用 Spark SQL 高效地读写 HBase的更多相关文章
- spark结构化数据处理:Spark SQL、DataFrame和Dataset
本文讲解Spark的结构化数据处理,主要包括:Spark SQL.DataFrame.Dataset以及Spark SQL服务等相关内容.本文主要讲解Spark 1.6.x的结构化数据处理相关东东,但 ...
- spark SQL (五)数据源 Data Source----json hive jdbc等数据的的读取与加载
1,JSON数据集 Spark SQL可以自动推断JSON数据集的模式,并将其作为一个Dataset[Row].这个转换可以SparkSession.read.json()在一个Dataset[Str ...
- Spark SQL讲解
Spark SQL讲解 Spark SQL是支持在Spark中使用Sql.HiveSql.Scala中的关系型查询表达式.它的核心组件是一个新增的RDD类型SchemaRDD,它把行对象用一个Sche ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- spark读写hbase性能对比
一.spark写入hbase hbase client以put方式封装数据,并支持逐条或批量插入.spark中内置saveAsHadoopDataset和saveAsNewAPIHadoopDatas ...
- Spark读写HBase
Spark读写HBase示例 1.HBase shell查看表结构 hbase(main)::> desc 'SDAS_Person' Table SDAS_Person is ENABLED ...
- Spark学习笔记——读写Hbase
1.首先在Hbase中建立一张表,名字为student 参考 Hbase学习笔记——基本CRUD操作 一个cell的值,取决于Row,Column family,Column Qualifier和Ti ...
- Adaptive Execution如何让Spark SQL更高效更好用
1 背 景 Spark SQL / Catalyst 和 CBO 的优化,从查询本身与目标数据的特点的角度尽可能保证了最终生成的执行计划的高效性.但是 执行计划一旦生成,便不可更改,即使执行过程中发 ...
- spark sql读hbase
项目背景 spark sql读hbase据说官网如今在写,但还没稳定,所以我基于hbase-rdd这个项目进行了一个封装,当中会区分是否为2进制,假设是就在配置文件里指定为#b,如long#b,还实用 ...
随机推荐
- Angular SPA基于Ocelot API网关与IdentityServer4的身份认证与授权(四)
在上一讲中,我们已经完成了一个完整的案例,在这个案例中,我们可以通过Angular单页面应用(SPA)进行登录,然后通过后端的Ocelot API网关整合IdentityServer4完成身份认证.在 ...
- sql-分组查询
分组查询: 关键字:group by 可以将查询结果分组,并返回行的汇总信息 注意: 1.出现在select后面的字段 要么是是聚合函数中的,要么就是group by 中的 2.要筛选结果 可以先使用 ...
- JavaScript的流程控制语句以及函数
一.流程控制 1. 作用:控制代码的执行顺序 2. 分类 2.1顺序结构:从上到下依次执行代码语句 2.2选择结构: 1. if语句 简单if结构 if(条件表达式){ 表达式成立时执行的代码段 } ...
- spring设计模式之applicationContext.getBean("beanName")思想
1.背景 在实际开发中我们会经常遇到不同的业务类型对应不同的业务处理,而这个业务类型又是经常变动的; 比如说,我们在做支付业务的时候,可能刚开始需要实现支付宝支付和微信支付,那么代码逻辑可能如下 /* ...
- ReentrantLock解析及源码分析
本文结构 Tips:说明一部分概念及阅读源码需要的基础内容 ReentrantLock简介 公平机制:对于公平机制和非公平机制进行介绍,包含对比 实现:Sync源码解析额,公平和非公平模式的加锁.解锁 ...
- 事件处理& 事件委托& 区别mouseover与mouseenter
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- Error C2079 'CMFCPropertySheet::m_wndOutlookBar' uses undefined class 'CMFCOutlookBar'
Severity Code Description Project File Line Suppression StateError C2079 'CMFCPropertySheet::m_wndOu ...
- 01 . 消息队列之(Kafka+ZooKeeper)
消息队列简介 什么是消息队列? 首先,我们来看看什么是消息队列,维基百科里的解释翻译过来如下: 队列提供了一种异步通信协议,这意味着消息的发送者和接受者不需要同时与消息保持联系,发送者发送的消息会存储 ...
- 05 . Python入门值循环语句
一.Python循环语句 程序一般情况下是按照顺序执行的 编程语言提供了各种控制结构,允许更复杂的执行路径 Python中的循环语句有for和while但没有do while 循环语句允许我们执行一个 ...
- 添加对docker的监控
一.环境:已安装docker机器ip:192.168.0.202 二.原理 使用docker的metrics-add参数,提供对docker运行参数的访问条件. 三.修改/etc/docker/dae ...