spark (四) RDD概念
1. RDD基本概念
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据处理模型。代码中是一个抽象类,它代表了一个弹性的、不可变的、可分区、里面的元素可并行计算的集合。
1.1 弹性
- 存储的弹性:内存和磁盘的自动切换
- 因为内存是有限制的,如果使用的内存超过了一定的阈值,会将部分数据切换到磁盘上
- 容错的弹性:数据丢失可以自动回复
- 计算的弹性:计算出错重试机制
- 分片的弹性:可以根据需求重新分片
1.2 分布式
- 数据存储在大数据集群的不同节点上
1.3 数据集
- RDD封装了计算逻辑,并不保存数据
1.4 数据抽象
- RDD是一个抽象类,具体需要子类来实现
1.5 不可变
- RDD封装了计算逻辑,是不可以改变的。想要改变只能产生新的RDD,在新的RDD里面封装计算逻辑(装饰器)
1.6 可分区、并行计算
RDD是一个逻辑上虚拟的集合,内部会拆分成多个partition 的 task,分配给executor
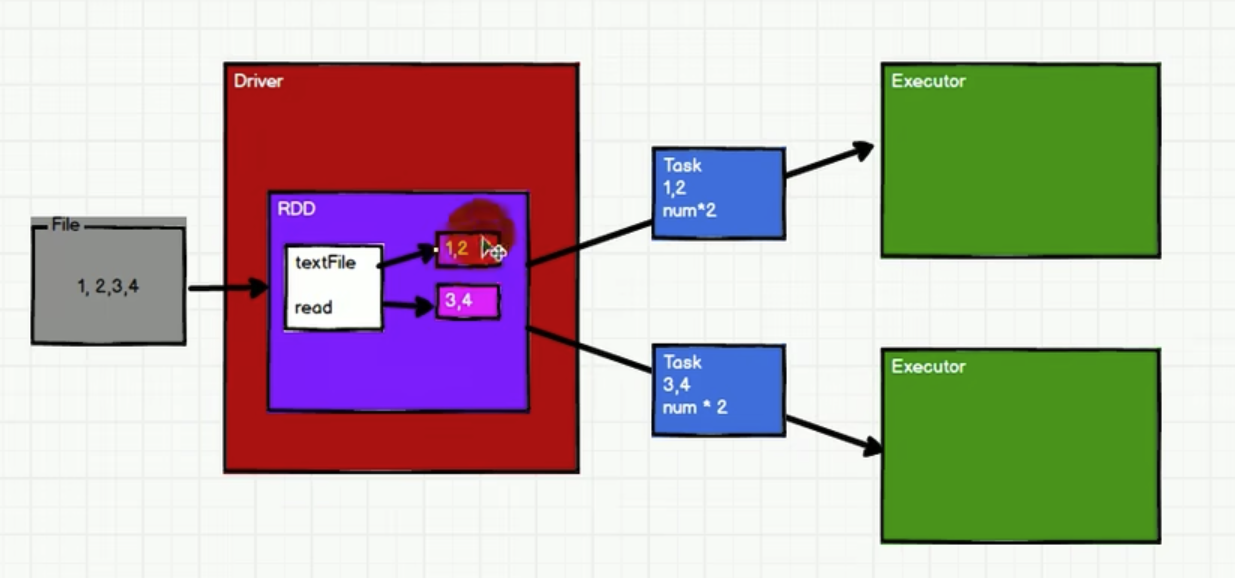
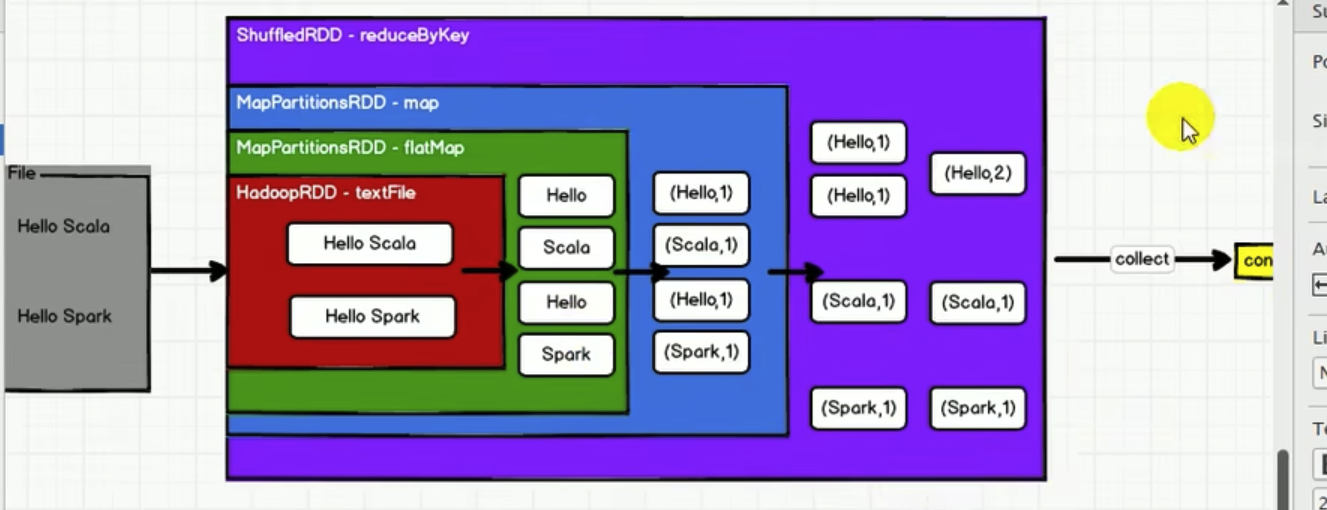
2. WordCount为例,看RDD特性
- RDD的数据处理方式类似于IO流,也有装饰者模式
- RDD的数据只有在调用
collect方法时,才会真正执行业务逻辑的计算操作,前面都是在叠buff - 与IO流能暂时缓存一部分数据(缓冲区)不同,RDD中间不缓存任何数据
3. RDD的五大属性
Internally, each RDD is characterized by five main properties:
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
3.1 分区列表
如上图,由于RDD内直接分区了,所以需要分区列表
3.2 计算逻辑 compute
针对该RDD下的所有分区,compute都是一样的
3.3 和其他RDD的依赖关系
3.4 (可选) 分区器
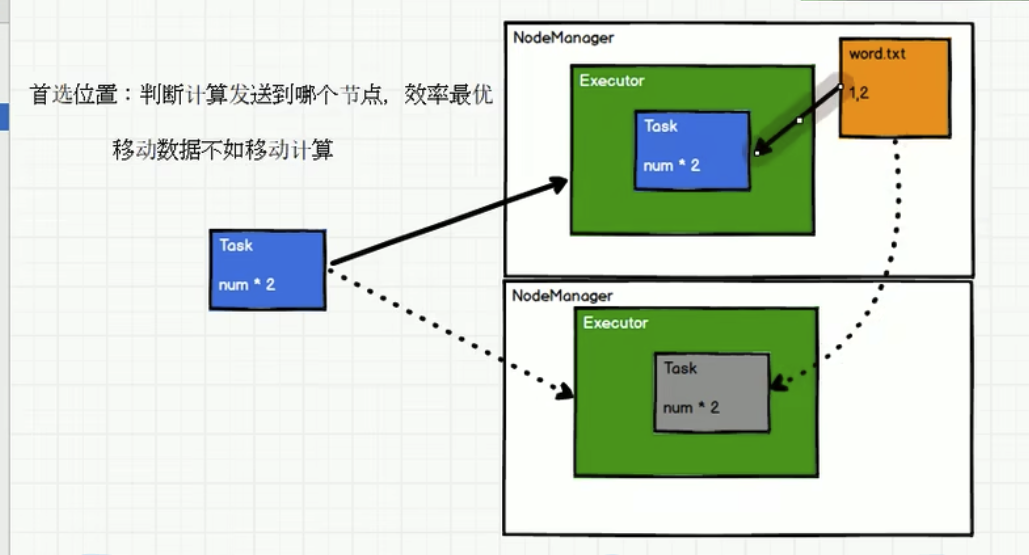
3.5 (可选) executor节点亲和
如下,其实任务发送给上面的
4. RDD执行原理(yarn环境)
4.1 启动Yarn集群环境
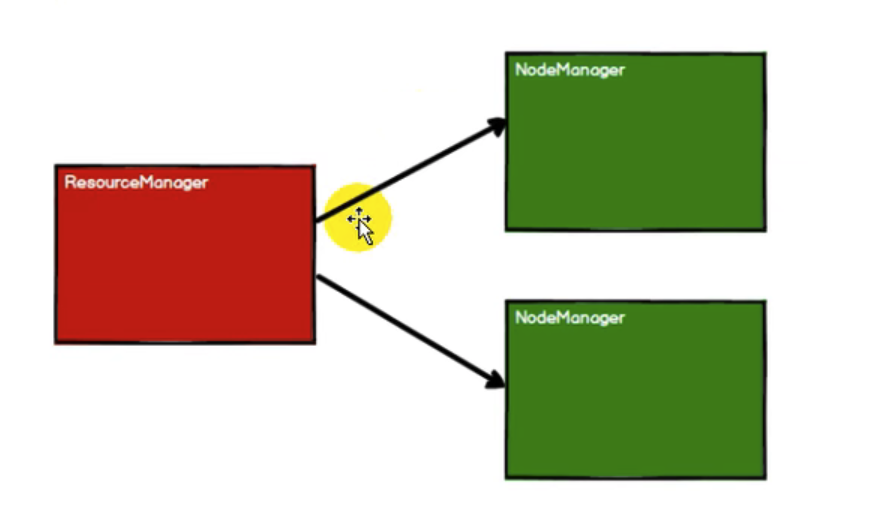
4.2 Spark通过申请资源创建调度节点和计算节点
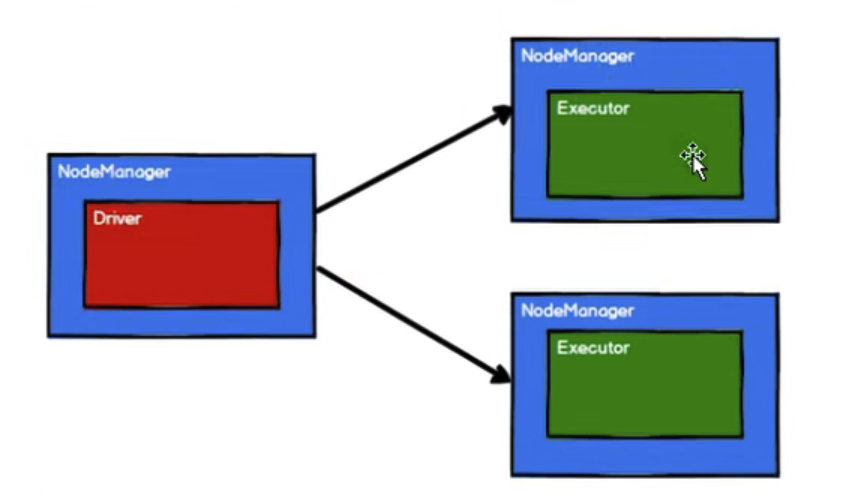
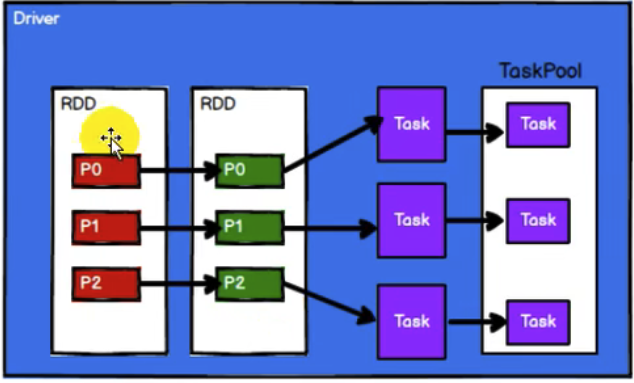
4.3 Spark框架根据需求将计算逻辑根据分区划分成不同的任务。此处会将task放置到 任务池中
4.4 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
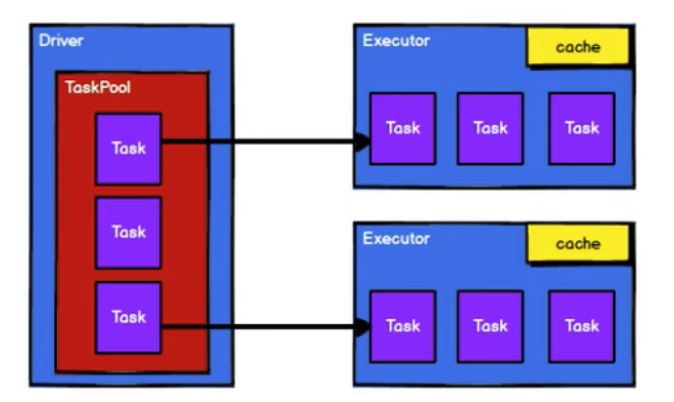
从以上流程可以看出RDD在整个流程中主要用于将逻辑进行封装,并生成Task发送给Executor节点执行计算。
spark (四) RDD概念的更多相关文章
- spark实验(四)--RDD编程(1)
一.实验目的 (1)熟悉 Spark 的 RDD 基本操作及键值对操作: (2)熟悉使用 RDD 编程解决实际具体问题的方法. 二.实验平台 操作系统:centos6.4 Spark 版本:1.5.0 ...
- Spark核心—RDD初探
本文目的 最近在使用Spark进行数据清理的相关工作,初次使用Spark时,遇到了一些挑(da)战(ken).感觉需要记录点什么,才对得起自己.下面的内容主要是关于Spark核心-RDD的相关 ...
- 关于Spark中RDD的设计的一些分析
RDD, Resilient Distributed Dataset,弹性分布式数据集, 是Spark的核心概念. 对于RDD的原理性的知识,可以参阅Resilient Distributed Dat ...
- RDD概念、特性、缓存策略与容错
一.RDD概念与特性 1. RDD的概念 RDD(Resilient Distributed Dataset),是指弹性分布式数据集.数据集:Spark中的编程是基于RDD的,将原始数据加载到内存变成 ...
- spark中RDD的转化操作和行动操作
本文主要是讲解spark里RDD的基础操作.RDD是spark特有的数据模型,谈到RDD就会提到什么弹性分布式数据集,什么有向无环图,本文暂时不去展开这些高深概念,在阅读本文时候,大家可以就把RDD当 ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark系列-核心概念
Spark系列-初体验(数据准备篇) Spark系列-核心概念 一. Spark核心概念 Master,也就是架构图中的Cluster Manager.Spark的Master和Workder节点分别 ...
- Spark Streaming核心概念与编程
Spark Streaming核心概念与编程 1. 核心概念 StreamingContext Create StreamingContext import org.apache.spark._ im ...
- Spark中RDD的常用操作(Python)
弹性分布式数据集(RDD) Spark是以RDD概念为中心运行的.RDD是一个容错的.可以被并行操作的元素集合.创建一个RDD有两个方法:在你的驱动程序中并行化一个已经存在的集合:从外部存储系统中引用 ...
随机推荐
- 云原生爱好者周刊:KubeKey v2.1.0 alpha 版发布!
KubeKey v2.1.0-alpha.0 发布啦!该版本的主要特性: 支持三种使用场景的 Etcd 集群(二进制部署,Kubeadm 部署,连接外置已存在的 Etcd 集群). 支持部署 Cont ...
- 两个时间段比较的六种情况,以及交集、并集、补集简要sql语句示例
〇.两时间段比较的全部情况 总共有如下图中的六种情况: 下文将根据这六种情况进一步操作. 注意,图中说的动态和固定两时间段,就是两个普通时间段,不区分主次,仅用作帮助理解. 一.判断两个时间段是否有交 ...
- 基于Java+SpringBoot+Mysql实现的古诗词平台功能设计与实现一
一.前言介绍: 1.1 项目摘要 随着信息技术的迅猛发展和数字化时代的到来,传统文化与现代科技的融合已成为一种趋势.古诗词作为中华民族的文化瑰宝,具有深厚的历史底蕴和独特的艺术魅力.然而,在现代社会中 ...
- 摒弃传统setInterval, 自己封装一个
传统的setInterval在某种情况下会导致内存泄漏,每次调用都会占用一部分内存空间,既然threejs的更新都是基于# requestAnimationFrame的循环调用,那么我们就可以利用这个 ...
- Qt5 CMake 使用指南
Qt5 CMake 使用指南 CMAKE_PREFIX_PATH的使用说明 CMAKE_PREFIX_PATH是CMake中一个重要的环境变量,它用于帮助CMake在配置项目时找到各种依赖项的位置.这 ...
- 方法区回收过程与GC的并发与并行
主要回收废弃常量和无用的类 废弃常量包括字面量.类或接口.方法.字段的符号引用等 废弃指的是没有任何地方引用这个常量. 无用的类 满足的三个条件: 1.没有该类的任何实例存在 2.加载该类的Class ...
- 利用Java heap dump查找、分析问题
http://autumnice.blog.163.com/blog/static/555200201143163723346/?fromdm&fromSearch&isFromSea ...
- Tornado框架之模板(三)
知识点 静态文件配置 static_path StaticFileHandler 模板使用 变量与表达式 控制语句 函数 块 目录: 静态文件 static_path 对于静态文件目录的命名,为了便于 ...
- Linux之密码生成工具pwgen
linux中生成随机字符串,可以使用pwgen 安装) ubuntu: apt-get install pwgen Centos: yum install pwgen 语法及参数) pwgen [ O ...
- feign 使用
feign 是netflix 提供的申明式的httpclient调用框架 整合方法 1.添加依赖 <dependency> <groupId>org.springframewo ...