Spark MLBase分布式机器学习系统入门:以MLlib实现Kmeans聚类算法
1.什么是MLBase
MLBase是Spark生态圈的一部分,专注于机器学习,包含三个组件:MLlib、MLI、ML Optimizer。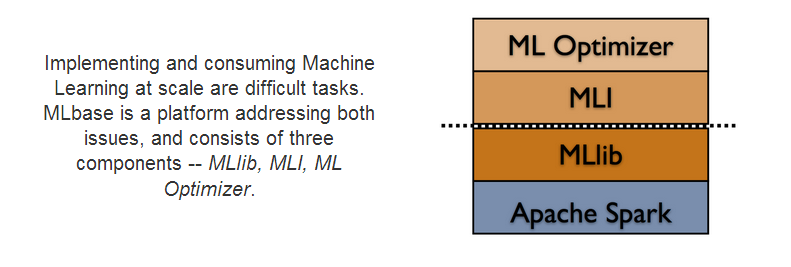
- ML Optimizer: This layer aims to automating the task of ML pipeline construction. The optimizer solves a search problem over feature extractors and ML algorithms included inMLI and MLlib. The ML Optimizer is currently under active development.
- MLI: An experimental API for feature extraction and algorithm development that introduces high-level ML programming abstractions. A prototype of MLI has been implemented against Spark, and serves as a testbed for MLlib.
- MLlib: Apache Spark's distributed ML library. MLlib was initially developed as part of the MLbase project, and the library is currently supported by the Spark community. Many features in MLlib have been borrowed from ML Optimizer and MLI, e.g., the model and algorithm APIs, multimodel training, sparse data support, design of local / distributed matrices, etc.
2.MLbase机器学习算法的流程
用户可以容易地使用MLbase这个工具来处理自己的数据。大部分的机器学习算法都包含训练以及预测两个部分,训练出模型,然后对未知样本进行预测。Spark中的机器学习包也是如此。
Spark将机器学习算法都分成了两个模块:
- 训练模块:通过训练样本输出模型参数
- 预测模块:利用模型参数初始化,预测测试样本,输出与测值。
MLbase提供了函数式编程语言Scala,利用MLlib可以很方便的实现机器学习的常用算法。
比如说,我们要做分类,只需要写如下scala代码:
var X = load("some_data", 2 to 10)
var y = load("some_data", 1)
var (fn-model, summary) = doClassify(X, y)
代码解释:X是需要分类的数据集,y是从这个数据集里取的一个分类标签,doClassify()分类。
这样的处理有两个主要好处:
- 每一步数据处理很清楚,可以很容易地可视化出来;
- 对用户来说,用ML算法处理是透明的,不用关心和考虑用什么分类方法,是SVM还是AdaBoost,SVM用的kernel是线性的还是RBF的,original和scaled的参数调成多少等等。
MLbase的三大组成部分之一:ML Optimizer,会选择它认为最适合的已经在内部实现好了的机器学习算法和相关参数,来处理用户输入的数据,并返回模型或别的帮助分析的结果。总体上的处理流程如下图:
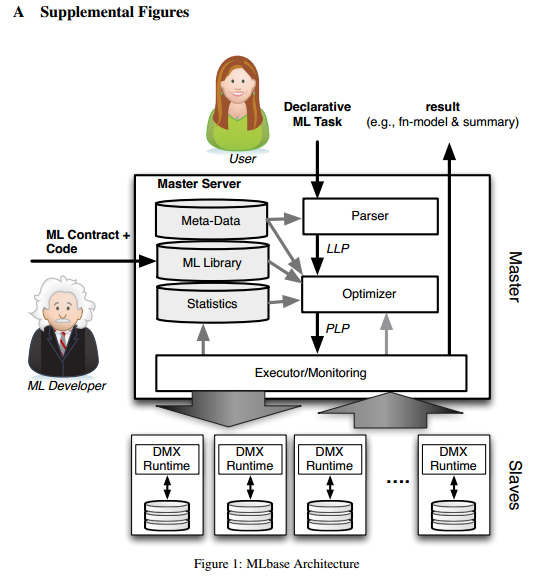
- 用户输入的Task比如doClassify(X, y)或者做协同过滤doCollabFilter(X, y)、图计算findTopKDegreeNodes(G, k = 1000)之类的事情,先会传给Parser处理,然后交给LLP。LLP是logical learning plan,即是逻辑上的一个学习选择过程,在这个过程里选择该用什么算法,特征提取应该用什么做,参数应该选什么,数据集怎么拆子数据集的策略等事情。
- LLP决定之后交给Optimizer。Optimizer是MLbase的核心,它会把数据拆分成若干份,对每一份使用不同的算法和参数来运算出结果,看哪一种搭配方式得到的结果最优(注意这次最优结果是初步的),优化器做完这些事之后就交给PLP。
- PLP是physical learning plan,即物理(实际)执行的计划,让MLbase的master把任务分配给具体slave去最后执行之前选好的算法方案,把结果计算出来返回,同时返回这次计算的学习模型。
- 这个流程是Task -> Parser -> LLP -> Optimizer -> PLP -> Execute -> Result/Model,先从逻辑上,在已有的算法里选几个适合这个场景的,让优化器都去做一遍,把认为当时最优的方案给实际执行的部分去执行,返回结果。
MLbase不仅仅把结果返回给用户。在LLP、Optimizer,MLbase会存储一些中间结果和特征,然后会继续搜寻和测试结果更好的算法和相关参数,并且会通知用户。LLP内部实现的算法是可以扩充的。
总之,MLbase会自动寻找合适的算法,自动选择和优化,还可以进行扩充。
3.Scala实现KMeans算法
3.1 什么是KMeans算法
K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
具体来说,通过输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准的k个聚类。
3.2 k-means 算法基本步骤
(1) 从 n个数据对象任意选择 k 个对象作为初始聚类中心;
(2) 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
(3) 重新计算每个(有变化)聚类的均值(中心对象);
(4) 计算标准测度函数,当满足一定条件,如函数收敛时,则算法终止;如果条件不满足则回到步骤(2)。
算法的时间复杂度上界为O(n*k*t), 其中t是迭代次数,n个数据对象划分为 k个聚类。
3.3 MLlib实现KMeans
以MLlib实现KMeans算法,利用MLlib KMeans训练出来的模型,可以对新的数据作出分类预测,具体见代码和输出结果。
Scala代码:
package com.hq import org.apache.spark.mllib.clustering.KMeans
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.{SparkContext, SparkConf} object KMeansTest {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage: <file>")
System.exit(1)
} val conf = new SparkConf()
val sc = new SparkContext(conf)
val data = sc.textFile(args(0))
val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble)))
val numClusters = 2
val numIterations = 20
val clusters = KMeans.train(parsedData,numClusters,numIterations) println("------Predict the existing line in the analyzed data file: "+args(0))
println("Vector 1.0 2.1 3.8 belongs to clustering "+ clusters.predict(Vectors.dense("1.0 2.1 3.8".split(' ').map(_.toDouble))))
println("Vector 5.6 7.6 8.9 belongs to clustering "+ clusters.predict(Vectors.dense("5.6 7.6 8.9".split(' ').map(_.toDouble))))
println("Vector 3.2 3.3 6.6 belongs to clustering "+ clusters.predict(Vectors.dense("3.2 3.3 6.6".split(' ').map(_.toDouble))))
println("Vector 8.1 9.2 9.3 belongs to clustering "+ clusters.predict(Vectors.dense("8.1 9.2 9.3".split(' ').map(_.toDouble))))
println("Vector 6.2 6.5 7.3 belongs to clustering "+ clusters.predict(Vectors.dense("6.2 6.5 7.3".split(' ').map(_.toDouble)))) println("-------Predict the non-existent line in the analyzed data file: ----------------")
println("Vector 1.1 2.2 3.9 belongs to clustering "+ clusters.predict(Vectors.dense("1.1 2.2 3.9".split(' ').map(_.toDouble))))
println("Vector 5.5 7.5 8.8 belongs to clustering "+ clusters.predict(Vectors.dense("5.5 7.5 8.8".split(' ').map(_.toDouble)))) println("-------Evaluate clustering by computing Within Set Sum of Squared Errors:-----")
val wssse = clusters.computeCost(parsedData)
println("Within Set Sum of Squared Errors = "+ wssse)
sc.stop()
}
}
3.4 以Spark集群standalone方式运行
①在IDEA打成jar包(如果忘记了,参见Spark:用Scala和Java实现WordCount),上传到用户目录下/home/ebupt/test/kmeans.jar
②准备训练样本数据:hdfs://eb170:8020/user/ebupt/kmeansData,内容如下
[ebupt@eb170 ~]$ hadoop fs -cat ./kmeansData
1.0 2.1 3.8
5.6 7.6 8.9
3.2 3.3 6.6
8.1 9.2 9.3
6.2 6.5 7.3
③spark-submit提交运行
[ebupt@eb174 test]$ spark-submit --master spark://eb174:7077 --name KmeansWithMLib --class com.hq.KMeansTest --executor-memory 2G --total-executor-cores 4 ~/test/kmeans.jar hdfs://eb170:8020/user/ebupt/kmeansData
输出结果摘要:
------Predict the existing line in the analyzed data file: hdfs://eb170:8020/user/ebupt/kmeansData
Vector 1.0 2.1 3.8 belongs to clustering 0
Vector 5.6 7.6 8.9 belongs to clustering 1
Vector 3.2 3.3 6.6 belongs to clustering 0
Vector 8.1 9.2 9.3 belongs to clustering 1
Vector 6.2 6.5 7.3 belongs to clustering 1
-------Predict the non-existent line in the analyzed data file: ----------------
Vector 1.1 2.2 3.9 belongs to clustering 0
Vector 5.5 7.5 8.8 belongs to clustering 1
-------Evaluate clustering by computing Within Set Sum of Squared Errors:-----
Within Set Sum of Squared Errors = 16.393333333333388
4.MLbase总结
本文主要介绍了MLbase如何实现机器学习算法,简单介绍了MLBase的设计思想。总的来说,Mlbase的核心是ML Optimizer,把声明式的任务转化成复杂的学习计划,输出最优的模型和计算结果。
与其它机器学习系统Weka、mahout不同:
- MLbase是分布式的,Weka是单机的。
- Mlbase是自动化的,Weka和mahout都需要使用者具备机器学习技能,来选择自己想要的算法和参数来做处理。
- MLbase提供了不同抽象程度的接口,可以扩充ML算法。
5.参考文献
- MLbase
- apache mlbase
- A. Talwalkar, T. Kraska, R. Griffith, J. Duchi, J. Gonzalez, D. Britz, X. Pan, V. Smith, E. Sparks, A. Wibisono, M. J. Franklin, M. I. Jordan. MLbase: A Distributed Machine Learning Wrapper. In Big Learning Workshop at NIPS, 2012.
- Spark MLlib系列——程序框架
- MLBase:Spark生态圈里的分布式机器学习系统
- Apache Spark MLlib KMeans
Spark MLBase分布式机器学习系统入门:以MLlib实现Kmeans聚类算法的更多相关文章
- Spark MLlib中KMeans聚类算法的解析和应用
聚类算法是机器学习中的一种无监督学习算法,它在数据科学领域应用场景很广泛,比如基于用户购买行为.兴趣等来构建推荐系统. 核心思想可以理解为,在给定的数据集中(数据集中的每个元素有可被观察的n个属性), ...
- 分布式机器学习系统笔记(一)——模型并行,数据并行,参数平均,ASGD
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术.应用感兴趣的同学加入. 文章索引::"机器学 ...
- Spark MLlib KMeans 聚类算法
一.简介 KMeans 算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把分类样本点分到各个簇.然后按平均法重新计算各个簇的质心,从而确定新的簇心.一直迭代,直到簇心的移动距离小于某个给定的值. ...
- Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解
Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解 在Hadoop分布式环境下实现K-Means聚类算法的伪代码如下: 输入:参数0--存储样本数据的文本文件inpu ...
- 机器学习六--K-means聚类算法
机器学习六--K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别 ...
- 机器学习:K-Means聚类算法
本文来自同步博客. 前面几篇文章介绍了回归或分类的几个算法,它们的共同点是训练数据包含了输出结果,要求算法能够通过训练数据掌握规律,用于预测新输入数据的输出值.因此,回归算法或分类算法被称之为监督学习 ...
- 机器学习中K-means聚类算法原理及C语言实现
本人以前主要focus在传统音频的软件开发,接触到的算法主要是音频信号处理相关的,如各种编解码算法和回声消除算法等.最近切到语音识别上,接触到的算法就变成了各种机器学习算法,如GMM等.K-means ...
- 机器学习公开课笔记(8):k-means聚类和PCA降维
K-Means算法 非监督式学习对一组无标签的数据试图发现其内在的结构,主要用途包括: 市场划分(Market Segmentation) 社交网络分析(Social Network Analysis ...
- 【机器学习】DBSCAN Algorithms基于密度的聚类算法
一.算法思想: DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法.与划分和层 ...
随机推荐
- Android 开发之动画详解
一.动画类型 Android的animation由四种类型组成:alpha.scale.translate.rotate XML配置文件中 alpha 渐变透明度动画效果 scale 渐变尺寸伸缩动画 ...
- MFC/VC++ UI界面美化技术
1. 工具: 1.1设备环境类: Windows下的绘图操作说到底就是DC操作.DC(Device Context设备环境)对象是一个抽象的作图环境,可能是对应屏幕,也可能是对应打印机或其它. ...
- ASP.NET基础之HttpContext学习
一:HttpContext理论知识: 1:HttpContext类它对Request.Respose.Server等等都进行了封装,并保证在整个请求周期内都可以随时随地的调用:为继承 IHttpMod ...
- RedHat7安装Nginx及第三方模块
编译安装Nginx 先安装编译过程中所需依赖包# yum -y install gcc pcre-devel openssl-devel zlib-devel jemalloc(更好的内存管理)# w ...
- (转)C#中的 break 与continue 的使用和注意
今天学习循环中断的 break 和continue 1.首先是 break ,大家请看代码: 1 2 3 4 5 6 7 8 9 10 11 12 int a = 0; wh ...
- 学习java随笔第九篇:java异常处理
在java中的异常处理和c#中的异常处理是一样的都是用try-catch语句. 基本语法如下 try { //此处是可能出现异常的代码 } catch(Exception e) { //此处是如果发生 ...
- [Mime] MimeHeaders--MimeHeader帮助类 (转载)
点击下载 MimeHeaders.rar 这个类是关于Mime的Headers类看下面代码吧 /// <summary> /// 类说明:Assistant /// 编 码 人:苏飞 // ...
- Java小例子(学习整理)-----学生管理系统-控制台版
1.功能介绍: 首先,这个小案例没有使用数据库,用集合的形式暂时保存数据,做测试! 功能: 增加学生信息 删除学生信息 修改学生信息 查询学生信息: 按照学号(精确查询) 按照姓名(模糊查询) 打 ...
- Codeforces 553C Love Triangles(图论)
Solution: 比较好的图论的题. 要做这一题,首先要分析love关系和hate关系中,love关系具有传递性.更关键的一点,hate关系是不能成奇环的. 看到没有奇环很自然想到二分图的特性. 那 ...
- PHP程序开发人员要掌握的知识
文件目录处理函数包80%以上的函数的功能的灵活运用. 日期时间函数中的80%以上的函数的功能的灵活运用 数学函数库中的100%的内容. 网络库中的60%以上的内容,对各个函数的功能比较熟悉. 字符串处 ...