scrapy爬取海量数据并保存在MongoDB和MySQL数据库中
前言
一般我们都会将数据爬取下来保存在临时文件或者控制台直接输出,但对于超大规模数据的快速读写,高并发场景的访问,用数据库管理无疑是不二之选。首先简单描述一下MySQL和MongoDB的区别:MySQL与MongoDB都是开源的常用数据库,MySQL是传统的关系型数据库,MongoDB则是非关系型数据库,也叫文档型数据库,是一种NoSQL的数据库。它们各有各的优点。我们所熟知的那些SQL语句就不适用于MongoDB了,因为SQL语句是关系型数据库的标准语言。
一、关系型数据库
关系模型就是指二维表格模型,因而一个关系型数据库就是由二维表及其之间的联系组成的一个数据组织。常见的有:Oracle、DB2、PostgreSQL、Microsoft SQL Server、Microsoft Access、MySQL、浪潮K-DB 等
MySQL:
1、在不同的引擎上有不同的存储方式。
2、查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高。
3、开源数据库的份额在不断增加,mysql的份额页在持续增长。
4、缺点就是在海量数据处理的时候效率会显著变慢。
二、非关系型数据库
非关系型数据库(nosql ),属于文档型数据库。文档的数据库:即可以存放xml、json、bson类型的数据。这些数据具备自述性,呈现分层的树状数据结构。数据结构由键值(key=>value)对组成。常见的有:NoSql、Cloudant、MongoDB、redis、HBase。
NoSQL(Not only SQL),泛指非关系型的数据库。随着互联网 web2.0 网站的兴起,传统的关系数据库在应付 web2.0 网站,特别是超大规模和高并发的 SNS 类型的 web2.0 纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL 数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。非关系型数据库可以为大数据建立快速、可扩展的存储库。
MongoDB
1、存储方式:虚拟内存+持久化。
2、查询语句:是独特的MongoDB的查询方式。
3、适合场景:事件的记录,内容管理或者博客平台等等。
4、架构特点:可以通过副本集,以及分片来实现高可用。
5、数据处理:数据是存储在硬盘上的,只不过需要经常读取的数据会被加载到内存中,将数据存储在物理内存中,从而达到高速读写。
6、成熟度与广泛度:新兴数据库,成熟度较低,Nosql数据库中最为接近关系型数据库,比较完善的DB之一,适用人群不断在增长。
三、MongoDB优势与劣势
优势:
1、快速。 在适量级的内存的MongoDB的性能是非常迅速的,它将热数据存储在物理内存中,使得热数据的读写变得十分快。
2、高扩展性。 MongoDB的高可用和集群架构拥有十分高的扩展性。
3、自身的FaiLover机制。 在副本集中,当主库遇到问题,无法继续提供服务的时候,副本集将选举一个新的主库继续提供服务。
4、Json的存储格式。 MongoDB的Bson和JSon格式的数据十分适合文档格式的存储与查询。
劣势:
1、 不支持事务操作。MongoDB本身没有自带事务机制,若需要在MongoDB中实现事务机制,需通过一个额外的表,从逻辑上自行实现事务。
2、 应用经验少,由于NoSQL兴起时间短,应用经验相比关系型数据库较少。
3、MongoDB占用空间过大。
四、MySQL优势与劣势
优势:
1、在不同的引擎上有不同 的存储方式。
2‘、查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高。
3、开源数据库的份额在不断增加,mysql的份额页在持续增长。
劣势:
1、在海量数据处理的时候效率会显著变慢。
五、Mysql和Mongodb主要应用场景
1.如果需要将mongodb作为后端db来代替mysql使用,即这里mysql与mongodb 属于平行级别,那么,这样的使用可能有以下几种情况的考量:
(1) mongodb所负责部分以文档形式存储,能够有较好的代码亲和性,json格式的直接写入方便。(如日志之类)
(2) 从datamodels设计阶段就将原子性考虑于其中,无需事务之类的辅助。开发用如nodejs之类的语言来进行开发,对开发比较方便。
(3) mongodb本身的failover机制,无需使用如MHA之类的方式实现。
2.将mongodb作为类似redis ,memcache来做缓存db,为mysql提供服务,或是后端日志收集分析。 考虑到mongodb属于nosql型数据库,sql语句与数据结构不如mysql那么亲和 ,也会有很多时候将mongodb做为辅助mysql而使用的类redis memcache 之类的缓存db来使用。 亦或是仅作日志收集分析。
六、对比
| 数据库名 | MongoDB | MySQL |
| 数据库模型 | 非关系型 | 关系型 |
| 存储方式 | 以类JSON的文档的格式存储(虚拟内存+持久化) | 不同引擎有不同的存储方式 |
| 查询语句 | MongoDB查询方式(包含类似JavaScript的函数) | 传统SQL语句 |
| 数据处理方式 | 基于内存,将热数据存放在物理内存中,从而达到高速读写 | 不同引擎有自己的特点 |
| 架构特点 | 可以通过副本集,以及分片来实现高可用 | 常见有单点,M-S,MHA.MMMCluster等架构方式 |
| 成熟度 | 新兴数据库,成熟度较低 | 成熟度高 |
| 广泛度 | NoSQL数据库中,比较完善且开源,使用人数在不断增长 | 开源数据库,市场份额不断增长 |
| 事务性 | 仅支持单文档事务操作,弱一致性 | 支持事务操作 |
| 占用空间 | 占用空间大 | 占用空间小 |
| join操作 | MongoDB没有join | MySQL支持join |
七、scrapy爬取猫眼电影排行榜海量数据,并法将其保存在本地Mysql和MongoDB中。
scrapy startproject myfrist(your_project_name)(scrapy startproject mongodb)用pycharm打开项目所在目录,并在终端输入 scrapy gendpider maoyan maoyan.com(以猫眼电影网页为例) 创建爬虫。 创建爬虫命令 :scrapy genspider 爬虫名 爬虫的地址 ,完整项目结构如下: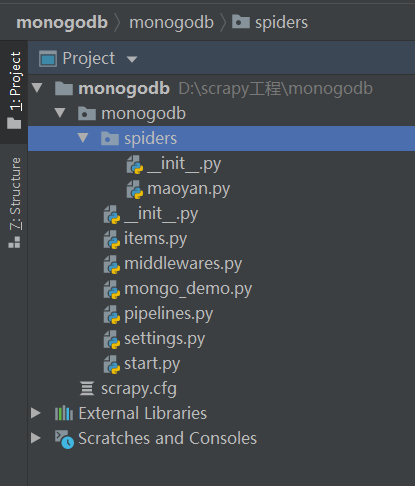
2.思路:先访问首页的排行榜,可以提取出首页排行的电影名和得分(每页三十个数据)。在首页中提取下一页标签的href,不断推送。就可以循环爬取啦。

maoyan.py代码如下:
import scrapy class MaoyanSpider(scrapy.Spider):
name = 'maoyan'
allowed_domains = ['maoyan.com']
start_urls = ['https://maoyan.com/films?showType=3&offset=0']
count = 0
NUM_PAGE = 3 # 默认爬前三页 def parse(self, response):
if self.count == self.NUM_PAGE: # 控制抓取的页数 例如只抓取前三页就循环三次
return
names = response.xpath('//dd/div[@class="channel-detail movie-item-title"]/@title').extract()
grades = [div.xpath('string(.)').extract_first() for div in response.xpath('//dd/div[@class="channel-detail channel-detail-orange"]')]
next_url = response.xpath('//ul[@class="list-pager"]/li[last()]/a/@href').extract_first() # 匹配父标签下相同子标签的最后一个
for name, grade in zip(names, grades):
# 把数据推送给pipeline管道
yield {
'name': name,
'grade': grade
}
yield scrapy.Request(response.urljoin(next_url), callback=self.parse)
self.count += 1
3.数据的保存是在pipelines.py模块中,代码如下。
from pymongo import MongoClient
from pymysql import connect class MonogodbPipeline:
"""
数据库名:maoyan
数据表名:t_maoyan_movie
可以事先不用创建,python会自动创建数据库和数据表
""" def open_spider(self, spider):
self.client = MongoClient('localhost', 27017)
self.db = self.client.maoyan
self.collection = self.db.t_maoyan_movie def process_item(self, item, spider):
self.collection.insert(item)
return item def close_spider(self, spider):
self.client.close() class MySQLPipeline:
"""
数据库名:maoyan
数据表名:t_maoyan_movie
mysql需要自己手动创建数据库和相对应的数据表
""" def open_spider(self, spider):
self.client = connect(host='localhost', port=3306, user='root', password='root', database='maoyan',
charset='utf8')
# 创建游标
self.cursor = self.client.cursor() def process_item(self, item, spider):
sql = 'insert into t_maoyan_movie values(0,%s,%s) '
self.cursor.execute(sql, [item['name'], item['grade']])
self.client.commit()
return item def close_spider(self, spider):
self.cursor.close()
self.client.close()
from fake_useragent import UserAgent # 偷懒的写法,一般自己定义USER-AGENT中间件
USER_AGENT = UserAgent().chrome ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 3 # 隔三秒爬一次
ITEM_PIPELINES = { 'monogodb.pipelines.MonogodbPipeline': 300, 'monogodb.pipelines.MySQLPipeline': 301, }
5. 创建mysql数据库和数据表 注意: python会自动创建mongodb数据库和对应collection,但mysql需要先手动创建。如果嫌命令创建麻烦,完全可以使用Navicat连接数据库界面操作。
1.连接mysql cmd中 命令: mysql -u root -p root
2. 创建数据库: create database maoyan charser ''utf8 (库名必须和代码中库名一致)
3.切换到已创建数据库创建表:user maoyan
4. 创建表
create table t_maoyan_movie (id int primary key auto_increment,name varchar(20), grade varchar(20));
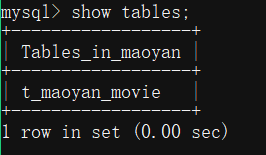
6. 执行程序插入数据
创建start.py文件,并执行
from scrapy.cmdline import execute
execute('scrapy crawl maoyan'.split())
也可以在终端中输入: scrapy crawl maoyan
7.结果:
1.mysql中结果
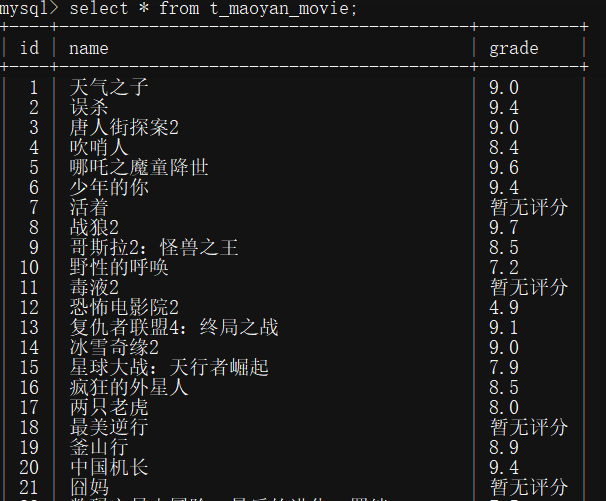
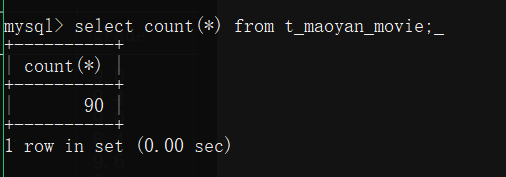
可以看到有90条数据。因为只爬了前三页,一页30条。可以在程序中选择页数。
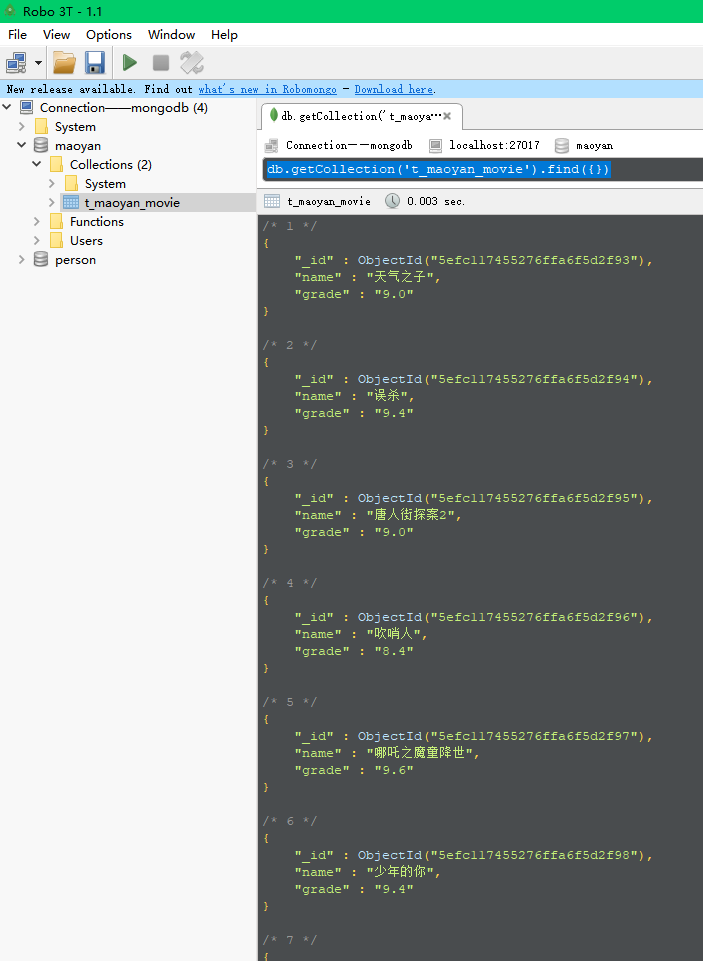
mongodb中结果:
打开Robo 3T, 执行 db.getCollection('t_maoyan_movie').find({})
可以看到电影信息啦
执行 db.getCollection('t_maoyan_movie').find({}).count()

可以看到依然有90条数据。
至此,大功告成!
scrapy爬取海量数据并保存在MongoDB和MySQL数据库中的更多相关文章
- Python爬取招聘信息,并且存储到MySQL数据库中
前面一篇文章主要讲述,如何通过Python爬取招聘信息,且爬取的日期为前一天的,同时将爬取的内容保存到数据库中:这篇文章主要讲述如何将python文件压缩成exe可执行文件,供后面的操作. 这系列文章 ...
- 实现多线程爬取数据并保存到mongodb
多线程爬取二手房网页并将数据保存到mongodb的代码: import pymongo import threading import time from lxml import etree impo ...
- 1.scrapy爬取的数据保存到es中
先建立es的mapping,也就是建立在es中建立一个空的Index,代码如下:执行后就会在es建lagou 这个index. from datetime import datetime fr ...
- python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现. 首先还是上代码: # -*- coding:utf-8 -*- import requests import re im ...
- 爬取豆瓣电影top250并存储到mysql数据库
import requests from lxml import etree import re import pymysql import time conn= pymysql.connect(ho ...
- Python爬虫根据关键词爬取知网论文摘要并保存到数据库中【入门必学】
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:崩坏的芝麻 由于实验室需要一些语料做研究,语料要求是知网上的论文摘要 ...
- <爬虫>利用BeautifulSoup爬取百度百科虚拟人物资料存入Mysql数据库
网页情况: 代码: import requests from requests.exceptions import RequestException from bs4 import Beautiful ...
- 使用scrapy爬取的数据保存到CSV文件中,不使用命令
pipelines.py文件中 import codecs import csv # 保存到CSV文件中 class CsvPipeline(object): def __init__(self): ...
- 顺企网 爬取16W数据保存到Mongodb
import requests from bs4 import BeautifulSoup import pymongo from multiprocessing.dummy import Pool ...
随机推荐
- postman接口超时设置,用于debug等断点调试
Settings->General->Request Timeout in ms(0 for infinity):设置请求超时的时间,默认为0
- WinUI 3试玩报告
1. 什么是 WinUI 3 在微软 Build 2020 开发者大会上,WinUI 团队宣布可公开预览的 WinUI 3 Preview 1,它让开发人员可以在 Win32 中使用 WinUI.Wi ...
- Php-webdriver 的安装与使用教程
Php-webdriver 是 Facebook 开发的基于 PHP 语言实现的 Selenium WebDriver 客户端组件,可以用它来操作浏览器.常见的操作包括:自动化测试.采集数据等. 安装 ...
- Myeclipse 2014 破解补丁以及Y2课件迅雷下载
一. 在破解myeclipse2014之前,要先把环境变量配置好: 1)打开我的电脑--属性--高级--环境变量2)新建系统变量JAVA_HOME 和CLASSPATH 变量名:JAVA_HOME 变 ...
- Flask 项目目录蓝图
Flask 项目目录蓝图 小型项目 大型项目 定义蓝图 注册蓝图 template_folder="XXX" 参数是指 模板文件夹 注意 优先是找templates 在找自己指定的 ...
- SpringMVC的url-pattern配置及原理剖析
SpringMVC的url-pattern配置及原理剖析 xml里面配置标签: <!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc./ ...
- 面向对象存储框架:Obase快速入门
在项目中完成对象建模后,可以使用Obase来进行对象的管理(例如对象持久化),本篇教程将创建一个.NET Core控制台应用,来展示Obase的配置和对象的增删改查操作.本篇教程旨在指引简单入门. 本 ...
- 记linux vsftpd配置遇到的错误
环境:centos 7 yum安装 yum install -y vsftpd 增加用户 # 家目录为/www 并设置nologin useradd -d /www -s /sbin/nologin ...
- Springboot项目整合Swagger2报错
SpringBoot2.2.6整合swagger2.2.2版本的问题,启动SpringBoot报如下错: Error starting ApplicationContext. To display t ...
- Git 居然可以用来跟女神聊天?
Git 是用来做啥的?想必码农朋友都知道,Git 是版本控制软件,是软件开发过程中团队协作不可或缺的软件. 但是,作为版本控制软件的 Git ,能跟聊天工具扯上关系吗?这二者似乎毫无关系,但脑洞大开的 ...