Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途!
今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取
初体验Jsoup
<!-- Maven坐标地址 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
我们先来找到博客园的个人首页做一个简单的小练习:https://www.cnblogs.com/hanzhe
调用Jsoup的connect静态函数创建连接,将爬取的目标网站作为参数传递过去:
public class Demo {
public static void main(String[] args) {
Connection connect = Jsoup.connect("https://www.cnblogs.com/hanzhe");
}
}
为了防止爬虫受到限制,这里设置请求头来模仿浏览器客户端,可以参照请求进行修改,例如:
public class Demo {
public static void main(String[] args) {
Connection connect = Jsoup.connect("https://www.cnblogs.com/hanzhe")
// 我这里只设置了一个,如果爬取遇到问题随时添加头信息即可
.header("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56");
}
}

然后调用execute方法开始进行爬取,通过body取出爬取到的数据:
public class Demo {
public static void main(String[] args) throws IOException {
Connection connect = Jsoup.connect("https://www.cnblogs.com/hanzhe")
.header("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56");
String body = connect.execute().body();
System.out.println(body);
}
}
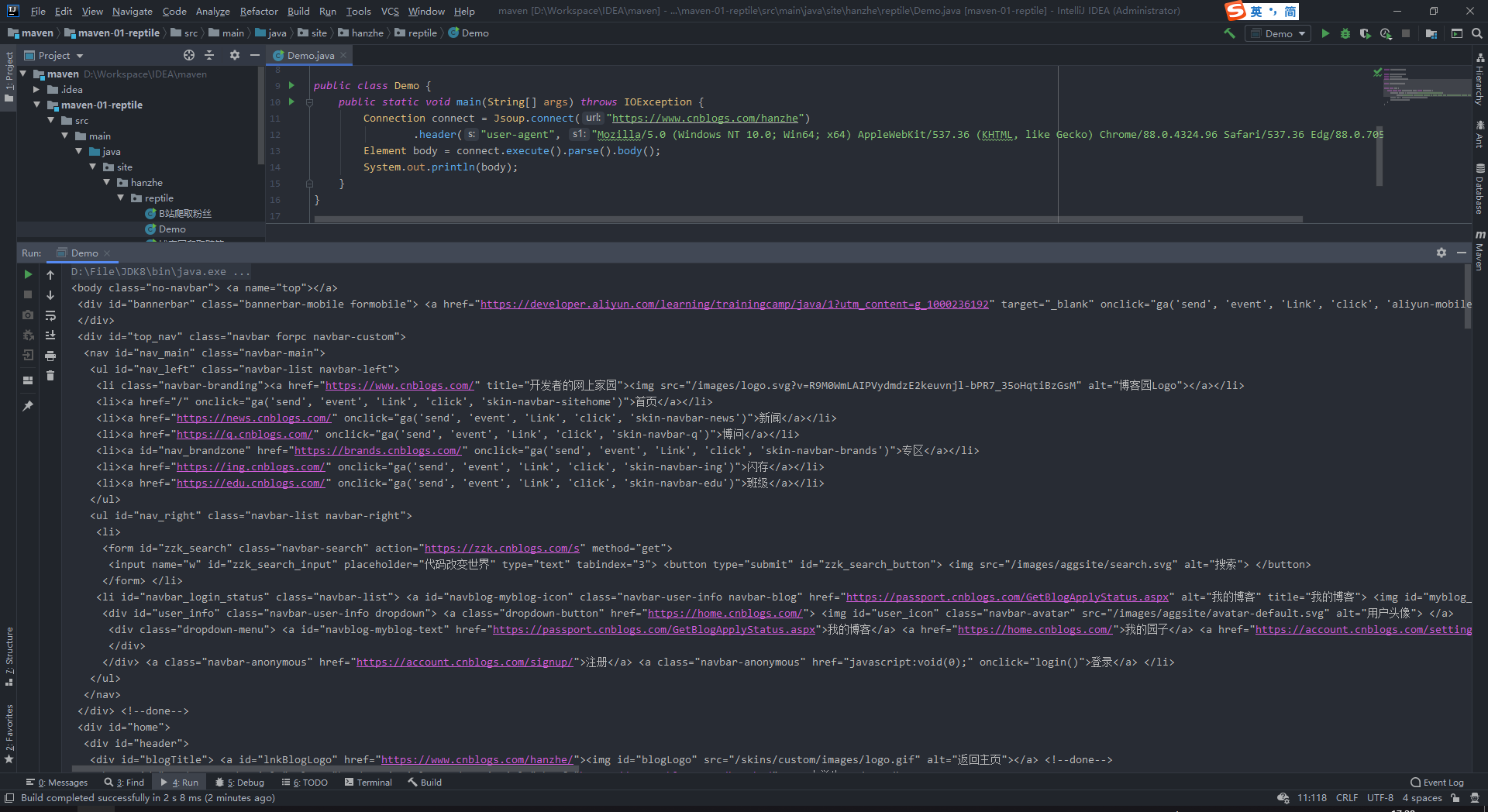
可以看到已经爬取到了首页的内容:

但是之前说Jsoup可以向操作JS一样对网页内容进行提取,所以我们在获取爬取内容之前要先对内容进行解析:
public class Demo {
public static void main(String[] args) throws IOException {
Connection connect = Jsoup.connect("https://www.cnblogs.com/hanzhe")
.header("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56");
// 使用parse函数对爬取到的内容进行解析
Element body = connect.execute().parse().body();
System.out.println(body);
}
}
明显看到解析后的HTML被格式化过,看着非常整齐,而且返回值也从字符串变成了ELement实例,可以通过操作实例实现内容筛选
测试爬取页面随笔
打开F12开发者工具,尝试获取到与随笔标题相关的信息:

观察发现每个随笔的标题都使用postTitle2 vertical-middle两个class进行修饰的,我们可以使用选择器来找到所有标题:

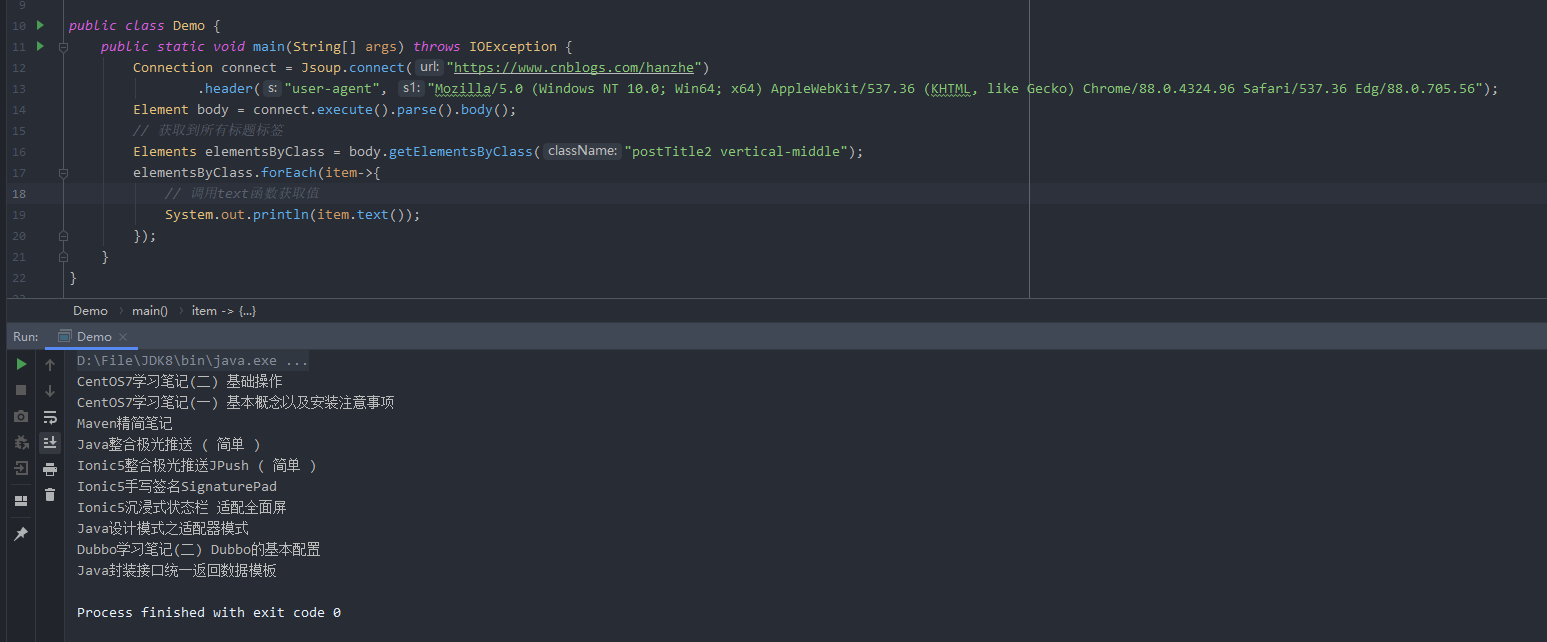
我们就用该选择器在Jsoup中爬取所有随笔标题:
public class Demo {
public static void main(String[] args) throws IOException {
Connection connect = Jsoup.connect("https://www.cnblogs.com/hanzhe")
.header("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56");
Element body = connect.execute().parse().body();
Elements elementsByClass = body.getElementsByClass("postTitle2 vertical-middle");
elementsByClass.forEach(item->{
System.out.println(item.text());
});
}
}
实战:爬取笔趣阁小说:
被选中的幸运儿:http://www.paoshuzw.com/26/26874/
具体Java代码:
public class 笔趣阁爬取小说 {
// 爬取目标网址:从第一章开始爬取,直至最后一章
private static String url = "http://www.paoshuzw.com/26/26874/13244872.html";
// 输出文件名称(一般为书名),如果仅仅是想拿来用改这两个参数就够了
private static String fileName = "仓元图";
// 空格,四格位置
private static String space = " ";
// 文件输出流
private static FileWriter writer;
// 计数器
private static int pageCount = 1;
// 启动类函数
public static void main(String[] args) throws Exception {
// 初始化程序
getWriter();
long l = System.currentTimeMillis();
// 循环爬取小说
do {
Element element = nextPage(url);
outputToFile(element);
url = hasNext(element);
} while (url != null);
writer.close();
long time = (System.currentTimeMillis() - l) / 1000;
System.out.println("\n\n 成功爬取所有章节!耗时" + time + "秒");
}
// 爬取页面
private static Element nextPage(String url) throws Exception{
// 获取连接实例,伪造浏览器身份
Connection conn = Jsoup.connect(url)
.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9")
.header("Accept-Encoding", "gzip, deflate")
.header("Accept-Language", "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6")
.header("Cache-Control", "max-age=0")
.header("Connection", "keep-alive")
.header("Host", url)
.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56");
return conn.execute().parse().body();
}
// 获取当前章节标题
private static String getTitle(Element element) {
return element.select(".bookname h1").text();
}
// 获取章节具体内容
private static String getContent(Element element) {
// 删除底部P标签的广告内容
element.getElementsByTag("p").remove();
// 获取到ID为content的所有HTML内容
String body = element.select("#content").html();
// 对body进行处理,返回正常格式的内容
body = body.replace(" ", space);
body = body.replace("<br>", "");
return body.replace(" \n \n", "\r\n");
}
// 是否有下一页?有返回下一页URL地址,没有就返回NULL
private static String hasNext(Element element) {
// 找到"下一章"的按钮,获取跳转的目标地址
Elements div = element.getElementsByClass("bottem2");
Element a = div.get(0).getElementsByTag("a").get(3);
String href = a.attr("href");
// 通过观察存在下一章的时候URL会以.html结尾,不存在时会跳转到首页,通过这个特点判断是否存在下一章
return href.endsWith(".html") ? "http://www.paoshuzw.com" + href : null;
}
// 获取输出流
private static void getWriter() throws IOException {
String path = "D:/" + fileName + ".txt";
File file = new File(path);
if (file.exists()) {
System.out.println("目标书籍已存在!请修改文件名称或删除原书籍:" + path);
System.exit(0);
}
writer = new FileWriter(file);
}
// 输出到文件
private static void outputToFile(Element element) throws IOException {
String title = getTitle(element);
String content = getContent(element);
String text = space + title + "\r\n\r\n" + content;
writer.write(text);
writer.flush();
System.out.println("==>>【" + title + "】爬取完成,正在爬取下一章(第" + pageCount++ + "次操作)");
}
}
Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说的更多相关文章
- bs4爬取笔趣阁小说
参考链接:https://www.cnblogs.com/wt714/p/11963497.html 模块:requests,bs4,queue,sys,time 步骤:给出URL--> 访问U ...
- scrapycrawl 爬取笔趣阁小说
前言 第一次发到博客上..不太会排版见谅 最近在看一些爬虫教学的视频,有感而发,大学的时候看盗版小说网站觉得很能赚钱,心想自己也要搞个,正好想爬点小说能不能试试做个网站(网站搭建啥的都不会...) 站 ...
- Python爬取笔趣阁小说,有趣又实用
上班想摸鱼?为了摸鱼方便,今天自己写了个爬取笔阁小说的程序.好吧,其实就是找个目的学习python,分享一下. 1. 首先导入相关的模块 import os import requests from ...
- python应用:爬虫框架Scrapy系统学习第四篇——scrapy爬取笔趣阁小说
使用cmd创建一个scrapy项目: scrapy startproject project_name (project_name 必须以字母开头,只能包含字母.数字以及下划线<undersco ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- HttpClients+Jsoup抓取笔趣阁小说,并保存到本地TXT文件
前言 首先先介绍一下Jsoup:(摘自官网) jsoup is a Java library for working with real-world HTML. It provides a very ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- 爬虫入门实例:利用requests库爬取笔趣小说网
w3cschool上的来练练手,爬取笔趣看小说http://www.biqukan.com/, 爬取<凡人修仙传仙界篇>的所有章节 1.利用requests访问目标网址,使用了get方法 ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
随机推荐
- Python和JavaScript在使用上有什么区别?
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 原文出处:https://www.freecodecamp.org/news/python-vs-javas ...
- SpringBoot 配置文件以及依赖 加上跨域配置文件
配置目录: application.properties的配置 #设置服务端口号 server.port = 8090 #配置数据源 spring.datasource.driver-class-na ...
- 简单&&大数取模
Big Number Problem Description As we know, Big Number is always troublesome. But it's really importa ...
- 箭头函数this的指向
箭头函数的this 什么是箭头函数,箭头函数是es6的新特性,其出现就是为了更好的表示(代替)回调函数 // 箭头函数 (arg1, arg2) => {} // 当箭头函数只有一个参数 arg ...
- pytorch中多个loss回传的参数影响示例
写了一段代码如下: import torch import torch.nn as nn import torch.nn.functional as F class Test(nn.Module): ...
- 剑指 Offer 21. 调整数组顺序使奇数位于偶数前面
剑指 Offer 21. 调整数组顺序使奇数位于偶数前面 Offer 21 这题的解法其实是考察快慢指针和头尾指针. package com.walegarrett.offer; /** * @Aut ...
- 人脸识别分析小Demo
人脸识别分析 调用 腾讯AI人脸识别接口 测试应用 纯py文件测试照片 # -*- coding: utf-8 -*- import json from tencentcloud.common imp ...
- java 入门环境搭建
Java帝国的诞生 1972年C诞生 1982年C++诞生 1995年JAVA诞生,为了实现真正的跨平台,在操作系统之上又加了抽象层,叫做JAVA的虚拟机,统称JVM 三高问题: 高可用 高性能 高并 ...
- Tomcat8弱口令+后台getshell
漏洞原因 用户权限在conf/tomcat-users.xml文件中配置: <?xml version="1.0" encoding="UTF-8"?&g ...
- 基于autofac的属性注入
基于autofac的属性注入 什么是属性注入 在了解属性注入之前,要先了解一下DI(Dependency Injection),即依赖注入.在ASP.NET Core里自带了一个IOC容器,而且程序支 ...