Pytorch多卡训练
前一篇博客利用Pytorch手动实现了LeNet-5,因为在训练的时候,机器上的两张卡只用到了一张,所以就想怎么同时利用起两张显卡来训练我们的网络,当然LeNet这种层数比较低而且用到的数据集比较少的神经网络是没有必要两张卡来训练的,这里只是研究怎么调用两张卡。
现有方法
在网络上查找了多卡训练的方法,总结起来就是三种:
- nn.DataParallel
- pytorch-encoding
- distributedDataparallel
第一种方法是pytorch自带的多卡训练的方法,但是从方法的名字也可以看出,它并不是完全的并行计算,只是数据在两张卡上并行计算,模型的保存和Loss的计算都是集中在几张卡中的一张上面,这也导致了用这种方法两张卡的显存占用会不一致。
第二种方法是别人开发的第三方包,它解决了Loss的计算不并行的问题,除此之外还包含了很多其他好用的方法,这里放出它的GitHub链接有兴趣的同学可以去看看。
第三种方法是这几种方法最复杂的一种,对于该方法来说,每个GPU都会对自己分配到的数据进行求导计算,然后将结果传递给下一个GPU,这与DataParallel将所有数据汇聚到一个GPU求导,计算Loss和更新参数不同。
这里我先选择了第一个方法进行并行的计算
并行计算相关代码
首先需要检测机器上是否有多张显卡
USE_MULTI_GPU = True
# 检测机器是否有多张显卡
if USE_MULTI_GPU and torch.cuda.device_count() > 1:
MULTI_GPU = True
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"
device_ids = [0, 1]
else:
MULTI_GPU = False
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
其中os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"是将机器中的GPU进行编号
接下来就是读取模型了
net = LeNet()
if MULTI_GPU:
net = nn.DataParallel(net,device_ids=device_ids)
net.to(device)
这里与单卡的区别就是多了nn.DataParallel这一步操作
接下来是optimizer和scheduler的定义
optimizer=optim.Adam(net.parameters(), lr=1e-3)
scheduler = StepLR(optimizer, step_size=100, gamma=0.1)
if MULTI_GPU:
optimizer = nn.DataParallel(optimizer, device_ids=device_ids)
scheduler = nn.DataParallel(scheduler, device_ids=device_ids)
因为optimizer和scheduler的定义发送了变化,所以在后期调用的时候也有所不同
比如读取learning rate的一段代码:
optimizer.state_dict()['param_groups'][0]['lr']
现在就变成了
optimizer.module.state_dict()['param_groups'][0]['lr']
详细的代码可以在我的GitHub仓库看到
开始训练
训练过程与单卡一样,这里就展示两张卡的占用情况
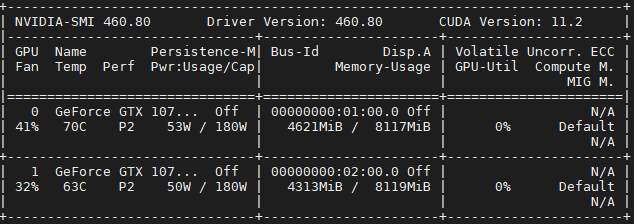
可以看到两张卡都有占用,这说明我们的代码起了作用,但是也可以看到,两张卡的占用有明显的区别,这就是前面说到的DataParallel只是在数据上并行了,在loss计算等操作上并没有并行
最后
如果文章那里有错误和建议,都可以向往指出
Pytorch多卡训练的更多相关文章
- Pytorch使用分布式训练,单机多卡
pytorch的并行分为模型并行.数据并行 左侧模型并行:是网络太大,一张卡存不了,那么拆分,然后进行模型并行训练. 右侧数据并行:多个显卡同时采用数据训练网络的副本. 一.模型并行 二.数据并行 数 ...
- 使用Pytorch进行多卡训练
当一块GPU不够用时,我们就需要使用多卡进行并行训练.其中多卡并行可分为数据并行和模型并行.具体区别如下图所示: 由于模型并行比较少用,这里只对数据并行进行记录.对于pytorch,有两种方式可以进行 ...
- Pytorch多GPU训练
Pytorch多GPU训练 临近放假, 服务器上的GPU好多空闲, 博主顺便研究了一下如何用多卡同时训练 原理 多卡训练的基本过程 首先把模型加载到一个主设备 把模型只读复制到多个设备 把大的batc ...
- 计图(Jittor) 1.1版本:新增骨干网络、JIT功能升级、支持多卡训练
计图(Jittor) 1.1版本:新增骨干网络.JIT功能升级.支持多卡训练 深度学习框架-计图(Jittor),Jittor的新版本V1.1上线了.主要变化包括: 增加了大量骨干网络的支持,增强了辅 ...
- pytorch 多GPU训练总结(DataParallel的使用)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/weixin_40087578/artic ...
- pytorch: 准备、训练和测试自己的图片数据
大部分的pytorch入门教程,都是使用torchvision里面的数据进行训练和测试.如果我们是自己的图片数据,又该怎么做呢? 一.我的数据 我在学习的时候,使用的是fashion-mnist.这个 ...
- AMD cpu 下 Pytorch 多卡并行卡死问题解决
dataparallel not working on nvidia gpus and amd cpus https://github.com/pytorch/pytorch/issues/130 ...
- pytorch版yolov3训练自己数据集
目录 1. 环境搭建 2. 数据集构建 3. 训练模型 4. 测试模型 5. 评估模型 6. 可视化 7. 高级进阶-网络结构更改 1. 环境搭建 将github库download下来. git cl ...
- PyTorch Tutorials 4 训练一个分类器
%matplotlib inline 训练一个分类器 上一讲中已经看到如何去定义一个神经网络,计算损失值和更新网络的权重. 你现在可能在想下一步. 关于数据? 一般情况下处理图像.文本.音频和视频数据 ...
随机推荐
- 使用 Kubernetes 扩展专用游戏服务器
系列 探索使用 Kubernetes 扩展专用游戏服务器:第 1 部分-容器化和部署 探索使用 Kubernetes 扩展专用游戏服务器:第 2 部分-管理 CPU 和内存 探索使用 Kubernet ...
- windows平台 cloin +rust 开发环境搭建
rust 安装请看上一篇 clion 下载地址 破解 教程 1.先执行reset_jetbrains_eval_windows.vbs 2.打开软件选择免费使用 将ide-eval-resetter- ...
- Dynamics CRM分享记录后出现关联记录被共享的问题
Dynamics CRM的权限配置有许多的问题,其中分享功能也是未来解决标准功能分配的权限不满足需求而设计的.但是这个功能使用的时候也要注意,否则会出现其他记录被共享的问题导致数据泄露可能会对项目的安 ...
- 记一次metasploitable2内网渗透之8180端口tomcat
扫描网段存活主机,确定内网metasploitable主机位置 nmap -T4 -sP 192.168.1.0/24 对目标主机进行扫描端口开放和系统信息 nmap -T4 -sV -Pn 192. ...
- Spring Boot 整合Junit和redis
14. Spring Boot整合-Junit 目标:在Spring Boot项目中使用Junit进行单元测试UserService的方法 分析: 添加启动器依赖spring-boot-starter ...
- 【CTF】图片隐写术 · 修复被修改尺寸的PNG图片
前言 今天我们想来介绍一下关于图片隐写相关处理,以及修复被修改尺寸的PNG图片. 关于PNG图片的相关处理,是CTF Misc图片隐写术中极为基础的一项操作,笔者这里是想要提一些做题过程中发现的小技巧 ...
- pandas(3):索引Index/MultiIndex
目录 一.索引概念 二.创建索引 ①导入数据时指定索引 ②导入数据后指定索引df.set_index() 三.常用的索引属性 四.常用索引方法 五.索引重置reset_index() 六.修改索引值( ...
- 实现Web请求后端Api的Demo,实现是通过JQuery的AJAX实现后端请求,以及对请求到的数据的解析处理,实现登录功能
本篇实现Web请求后端Api的Demo,实现是通过JQuery的AJAX实现后端请求,以及对请求到的数据的解析处理,实现登录功能需求描述:1. 请求后端Api接口地址2. 根据返回信息进行判断处理前端 ...
- Day13_70_join()
join() 方法 * 合并线程 join()线程合并方法出现在哪,就会和哪个线程合并 (此处是thread和主线程合并), * 合并之后变成了单线程,主线程需要等thread线程执行完毕后再执行,两 ...
- Prometheus【node_exporter】+grafana监控云主机
下面说一下这个开源软件的安装实践过程,目标如下: 在监控服务器上安装prometheus 在被监控环境上安装exporter 安装grafana 在监控服务器上安装prometheus 开始安装pro ...