freeswitch APR库哈希表

概述
freeswitch的核心源代码是基于apr库开发的,在不同的系统上有很好的移植性。
哈希表在开发中应用的非常广泛,主要场景是对查询效率要求较高的逻辑,是典型的空间换时间的数据结构实现。
大多数的底层库有各自的哈希表实现方法,那么apr库中对于哈希表究竟是如何实现的呢,其中有什么优点和缺点?
下面我们对apr库的哈希表实现做一个介绍。
环境
centos:CentOS release 7.0 (Final)或以上版本
freeswitch:v1.8.7
GCC:4.8.5
哈希表数据结构
apr库的哈希表源代码文件在libs/apr目录下。
libs\apr\include\apr_hash.h
libs\apr\tables\apr_hash.c
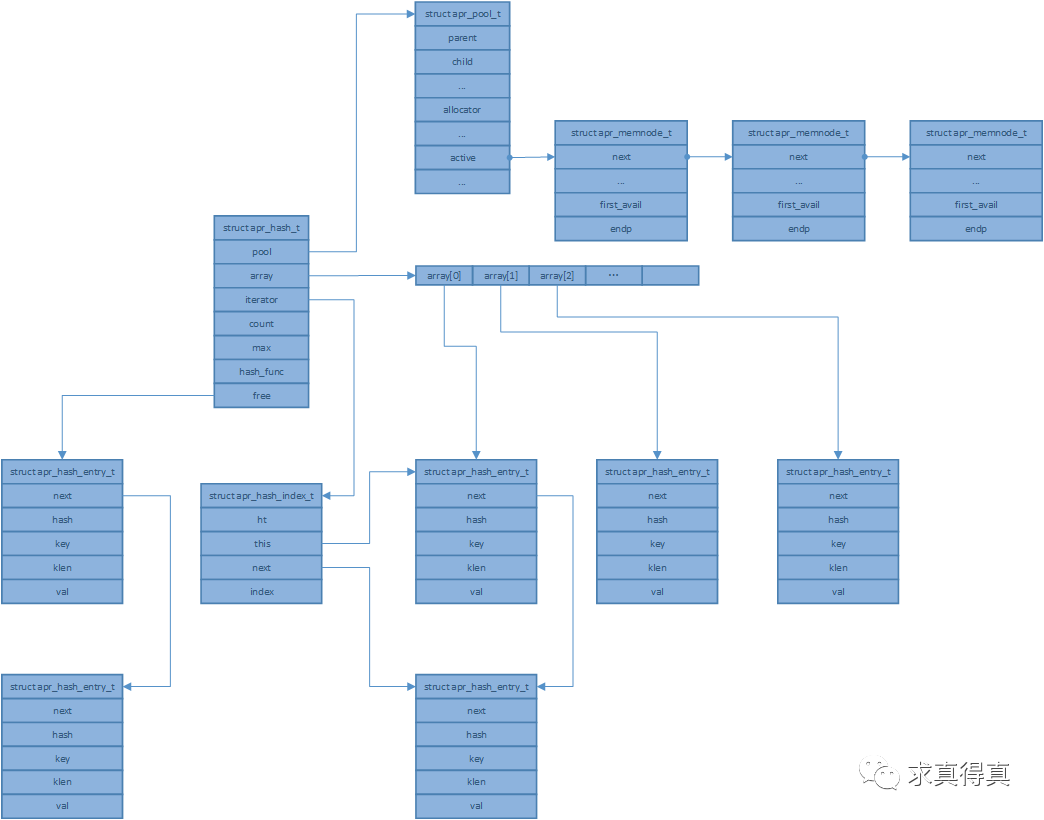
哈希表结构体定义在apr_hash.c中。
struct apr_hash_entry_t {
apr_hash_entry_t *next;
unsigned int hash;
const void *key;
apr_ssize_t klen;
const void *val;
};
struct apr_hash_index_t {
apr_hash_t *ht;
apr_hash_entry_t *this, *next;
unsigned int index;
};
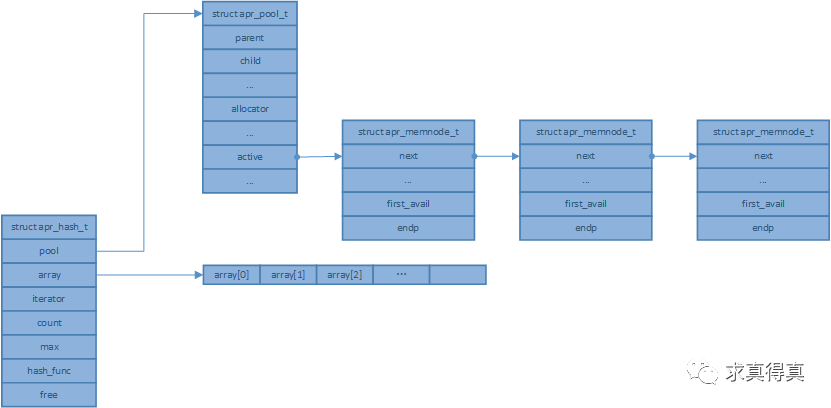
struct apr_hash_t {
apr_pool_t *pool;
apr_hash_entry_t **array;
apr_hash_index_t iterator; /* For apr_hash_first(NULL, ...) */
unsigned int count, max;
apr_hashfunc_t hash_func;
apr_hash_entry_t *free; /* List of recycled entries */
};
常用函数
查看源代码头文件libs\apr\include\apr_hash.h。
apr_hashfunc_default //默认hash函数
apr_hash_make //创建hash表
apr_hash_make_custom //创建hash表,自定义hash函数
apr_hash_copy //复制hash表
apr_hash_set //hash表插入一个新的键值对
apr_hash_get //hash表查找key对应的value
apr_hash_first //hash表遍历,第一个节点
apr_hash_next //hash表遍历,下一个节点
apr_hash_this //hash表遍历,获取当前节点内容
apr_hash_count //hash表键值对计数
apr_hash_clear //清空所有键值对
apr_hash_overlay //合并俩个hash表
apr_hash_merge //合并俩个hash表,自定义冲突处理函数
apr_hashfunc_default默认哈希函数
apr库哈希表默认的哈希函数使用times33哈希算法,times33算法很简单,就是不断的乘33。
对于字符串类型的key,times33算法很好用,计算很快,hash结果分布均匀。
核心代码如下:
if (*klen == APR_HASH_KEY_STRING) {
for (p = key; *p; p++) {
hash = hash * 33 + *p;
}
*klen = p - key;
}
else {
for (p = key, i = *klen; i; i--, p++) {
hash = hash * 33 + *p;
}
}
apr_hash_make创建
apr库哈希表的创建函数。
1, 从内存池分配apr_hash_t大小的内存。
2, 字段初始化,包括内存池指针赋值,free指针设置为NULL,count设置为0,max为INITIAL_MAX(15), array指针数组内存分配,hash函数使用apr_hashfunc_default。
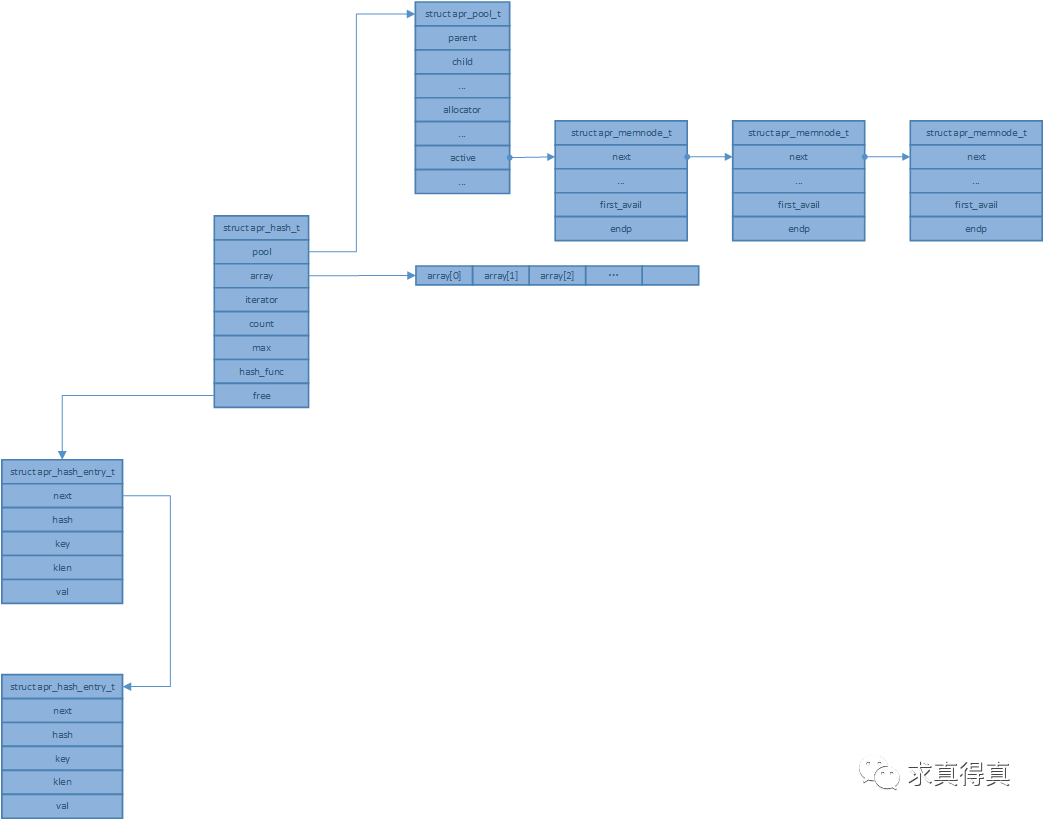
apr_hash_set插入
apr库哈希表,插入键值对。
1, 查找。根据key计算hash值,并在hash值对应的array[hash & ht->max]下查找key,key已存在则返回当前entry。key不存在,优先从free链表中获取entry,否则新建entry并返回。
2, 检查获取到的entry。如果传入的val值为空,则将该entry删除并加入free链表。传入的val值正常,则替换entry中的val字段。
3, 检查count计数超过max时,扩展哈希表。
4, 扩展哈希表时,创建new_array数组,new_max大小为(max * 2 + 1)。遍历array,赋值到new_array并切换array数组。

apr_hash_get查找
apr哈希表查找的逻辑:
根据key计算hash值,并在hash值对应的array[hash & ht->max]下查找key,key存在则返回当前entry中的val值。key不存在则返回NULL。
apr_hash_clear清空
apr哈希表清空的逻辑:
遍历hash表,把所有的entry节点中的val设置为NULL。
所以,apr_hash_clear之后,hash表并没有清空,只是把所有的entry节点的val置空,并将entry放入了free链表。
总结
apr库的哈希表对于大部分场景已经足够使用了。但是有一些特殊的场景要考虑到出问题的可能。
apr库哈希表不是线程安全的。
apr库哈希表没有对冲突做进一步处理,在array[i]下的entry链表长度超过某个阈值时,通过某些方法降低冲突,比如扩容、修改hash算法、entry使用红黑树代替链表等等。
空空如常
求真得真
freeswitch APR库哈希表的更多相关文章
- freeswitch APR库
概述 freeswitch依赖库源代码基本都可以在libs目录下找到. 在freeswitch的官方手册中,可以找到freeswitch的依赖库表格,其中freeswitch的core核心代码依赖库主 ...
- freeswitch APR库线程读写锁
概述 freeswitch的核心源代码是基于apr库开发的,在不同的系统上有很好的移植性. 线程读写锁在多线程服务中有重要的作用.对于读数据比写数据频繁的服务,用读写锁代替互斥锁可以提高效率. 由于A ...
- 简单的哈希表实现 C语言
简单的哈希表实现 简单的哈希表实现 原理 哈希表和节点数据结构的定义 初始化和释放哈希表 哈希散列算法 辅助函数strDup 哈希表的插入和修改 哈希表中查找 哈希表元素的移除 哈希表打印 测试一下 ...
- C++ STL中哈希表Map 与 hash_map 介绍
0 为什么需要hash_map 用过map吧?map提供一个很常用的功能,那就是提供key-value的存储和查找功能.例如,我要记录一个人名和相应的存储,而且随时增加,要快速查找和修改: 岳不群-华 ...
- python 全栈开发,Day61(库的操作,表的操作,数据类型,数据类型(2),完整性约束)
昨日内容回顾 一.回顾 定义:mysql就是一个基于socket编写的C / S架构的软件 包含: ---服务端软件 - socket服务端 - 本地文件操作 - 解析指令(mysql语句) ---客 ...
- 库的操作&表的操作
一 库的操作 掌握库的增删改查 一.系统数据库 执行如下命令,查看系统库 show databases; information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数 ...
- stl vector、红黑树、set、multiset、map、multimap、迭代器失效、哈希表(hash_table)、hashset、hashmap、unordered_map、list
stl:即标准模板库,该库包含了诸多在计算机科学领域里所常用的基本数据结构和基本算法 六大组件: 容器.迭代器.算法.仿函数.空间配置器.迭代适配器 迭代器:迭代器(iterator)是一种抽象的设计 ...
- mysql更新(三)语句 库的操作 表的操作
04-初始mysql语句 本节课先对mysql的基本语法初体验. 操作文件夹(库) 增 create database db1 charset utf8; 查 # 查看当前创建的数据库 show ...
- MySQL常见的库操作,表操作,数据操作集锦及一些注意事项
一 库操作(文件夹) 1 数据库命名规则 可以由字母.数字.下划线.@.#.$ 区分大小写 唯一性 不能使用关键字如 create select 不能单独使用数字 最长128位 2 数据库相关操作 创 ...
随机推荐
- Unity——计时器功能实现
Unity计时器 Demo展示 介绍 游戏中有非常多的计时功能,比如:各种cd,以及需要延时调用的方法: 一般实现有一下几种方式: 1.手动计时 float persistTime = 10f flo ...
- 【UE4 C++ 基础知识】<9> Interface 接口
概述 简单的说,接口提供一组公共的方法,不同的对象中继承这些方法后可以有不同的具体实现. 任何使用接口的类都必须实现这些接口. 实现解耦 解决多继承的问题 蓝图使用 使用方法 三种调用方法的区别 调用 ...
- mybatis学习笔记(2)基本原理
引言在mybatis的基础知识中我们已经可以对mybatis的工作方式窥斑见豹(参考:<MyBatis----基础知识>).但是,为什么还要要学习mybatis的工作原理?因为,随着myb ...
- Spring Security 多过滤链的使用
Spring Security 多过滤链的使用 一.背景 二.需求 1.给客户端使用的api 2.给网站使用的api 三.实现方案 方案一: 方案二 四.实现 1.app 端 Spring Secur ...
- C++的指针使用心得
使用C++有一段时间了,C++的手动内存管理缺失很麻烦,一不小心容易产生内存泄漏.自己总结了一点使用原则(不一定对),备注一下,避免忘记. 1.类外部传来的指针不处理 2.Qt对象管理的内存不处理 3 ...
- stm32学习心得体会
stm32作为现在嵌入式物联网单片机行业中经常要用多的技术,相信大家都有所接触,今天这篇就给大家详细的分析下有关于stm32的出口,还不是很清楚的朋友要注意看看了哦,在最后还会为大家分享有些关于stm ...
- 零基础学习Linux必会的60个常用命令
Linux必学的60个命令Linux提供了大量的命令,利用它可以有效地完成大量的工 作,如磁盘操作.文件存取.目录操作.进程管理.文件权限设定等.所以,在Linux系统上工作离不开使用系统提供的命令. ...
- 页表 Page tables
逻辑地址与物理地址的转化 页表是由页表项(PTE)组成的数组.512个PTE构成一个页表页(Page-table page). PTE中包含了物理页码(PPN physical page number ...
- Shadertoy 教程 Part 3 - 矩形和旋转
Note: This series blog was translated from Nathan Vaughn's Shaders Language Tutorial and has been au ...
- triangle leetcode C++
Given a triangle, find the minimum path sum from top to bottom. Each step you may move to adjacent n ...