kylin cubing algorithm(算法)
看到这一块的视频,结合光方博客的一些文档及自己的一点理解,记个笔记,以备不时之需。
- by layer cubing
1.on MR
这个算法的对cube的计算就像它的名字一样是按player进行的。
以一个n维cube(即事实表有n个维度)为例:
player-1:以source data(源数据)为基础计算出一个n维的cuboid;
player-2:以上一层的n维cuboid维基础,计算出n个n-1维的cuboid;
... ...
player-k+1:以上一层的n-k+1维cuboid为基础,计算出n!/[(n-k)!k!]=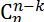 个n-k维的cuboid;
个n-k维的cuboid;
... ...
player-n+1:以上一层的1维cuboid为基础,计算出1个0维的cuboid。
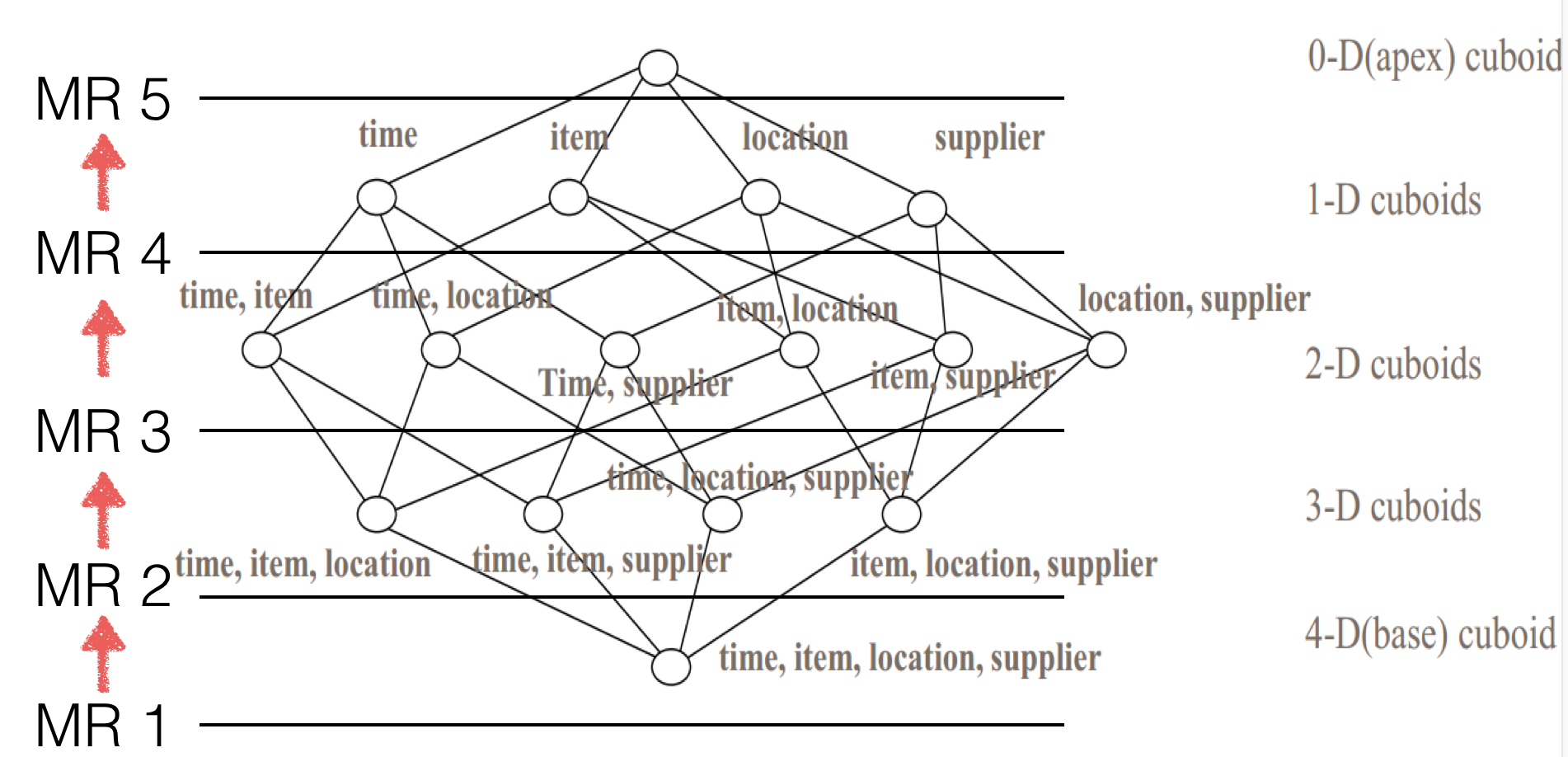
用官网上一个4维cube的例子来说明一下具体过程。
在player-1,根据源数据得到1个4-D的cuboid;然后cong中任意取出三个维度得到4个3-D cuboids;接着从3-D cuboids出发,任意取出其中两个维度得到6个2-D cuboids;再以2-D cuboids为基础,任意取出其中一个维度得到4个1-D cuboids;最后根据1-D cuboids 计算出一个0-D cuboid。
cuboids的构建的思想和组合数的概念一致:从含有i个维度的i-D cuboids 中取出i-1个维度构成一个新的cuboid。有次每一层cuboids 的数量变很容易得到。以(n-2)-D cuboids 为例:(n-1)-D cuboids 有n个,故总共可以计算出n*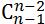 个(n-2)-D cuboids;而分析(n-1)-D cuboids发现,每两个(n-1)-D cuboids 有且只有一个维度是不同的,即每两个(n-1)-D cuboids 构建出的2*个(n-2)-D cuboids中会出现两个维度相同的(n-2)-D cuboids,因此重复的n*个(n-2)-D cuboids中有
个(n-2)-D cuboids;而分析(n-1)-D cuboids发现,每两个(n-1)-D cuboids 有且只有一个维度是不同的,即每两个(n-1)-D cuboids 构建出的2*个(n-2)-D cuboids中会出现两个维度相同的(n-2)-D cuboids,因此重复的n*个(n-2)-D cuboids中有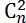 个重复的(n-2)-D cuboids,n*-=
个重复的(n-2)-D cuboids,n*-=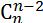 即为(n-2)-D cuboids的个数。
即为(n-2)-D cuboids的个数。
优点:
- 这个算法的原理很清晰,主要就是利用了MR,sorting、grouping、shuffing全部由MR完成,开发人员只需要关注cubing的逻辑
- 由于hadoop的成熟,该算法的运行很稳定
缺点:
- cube的维度越高,需要的MR任务越多(n-D cube 需要n+1 个MR)
- 太多的shuffing操作(mapper端不做聚合,所有在下一层中具有相同维度的值有combiner 和reducer聚合)
- 对hdfs读写比较多(每一层MR的结果会写到hdfs然后下一层MR从hdfs 读取数据)
2.on Spark
“by-layer” Cubing把一个大任务划分为许多步骤,每一步骤的计算依赖于上一个步骤的输出结果,所以当某一个步骤的计算出现问题时,可以再次读取上一步骤的结果重新计算,而不用从头开始。使得“by-layer” Cubing算法稳定可靠,当换到spark上时,便保留了这个算法。因此在spark上这个算法也被称为“By layer Spark Cubing”.
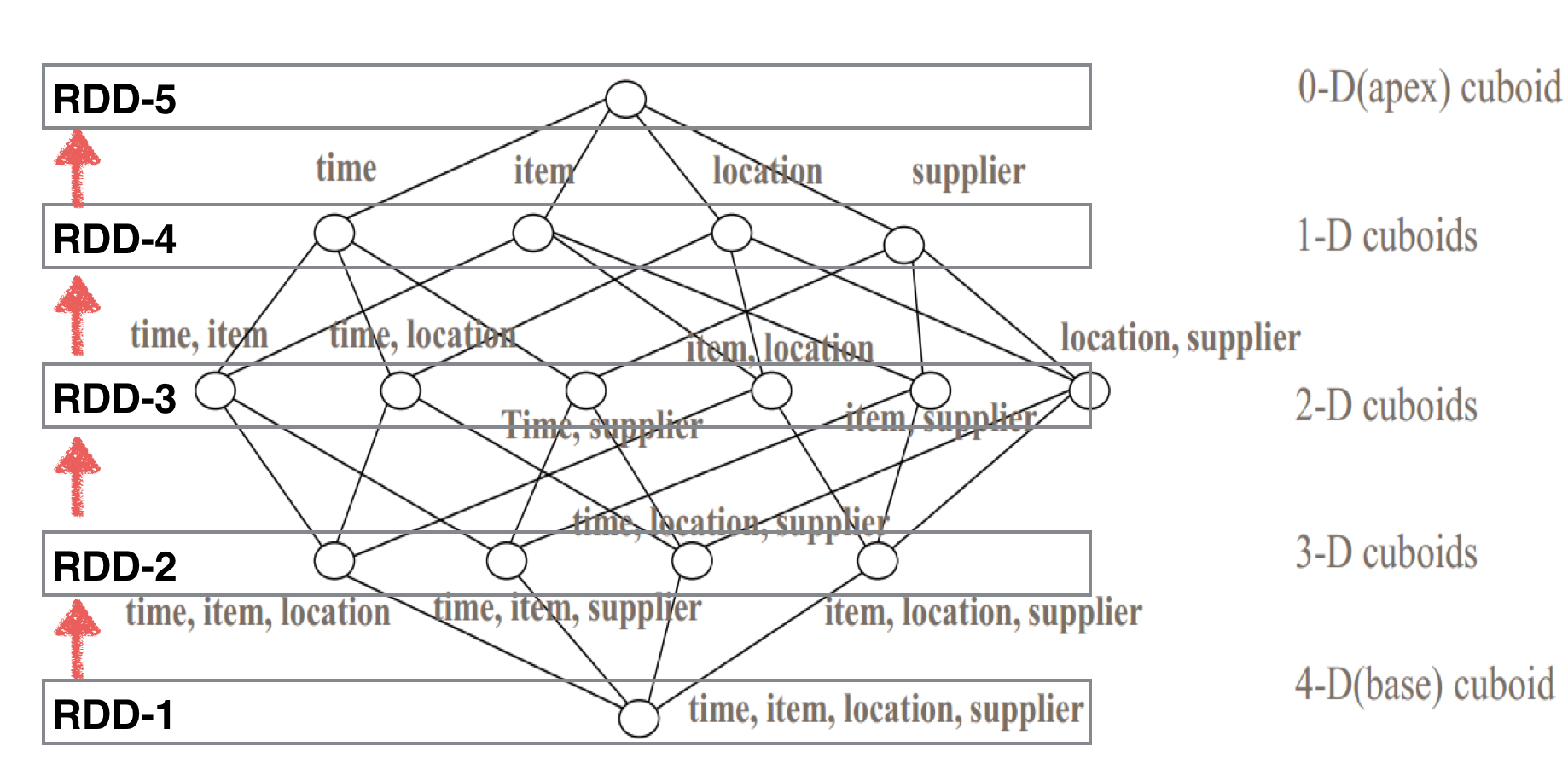
如上图所示,与在MR上相比,每一层的计算结果不再输出到hdfs,而是放在RDD中。由于RDD存储在内存中,从而有效避免了MR上过多的读写操作。
- fast cubing
与by layer cubing 的操作对象是数据的整体不同的是 fast cubing 算法则是将整体数据切分一个个segment,然后对每个片段进行计算得到一个个cube segment(拥有所有cuboids),最后把这些小的cube片段聚合成一个大的cube segment,cubing结束。
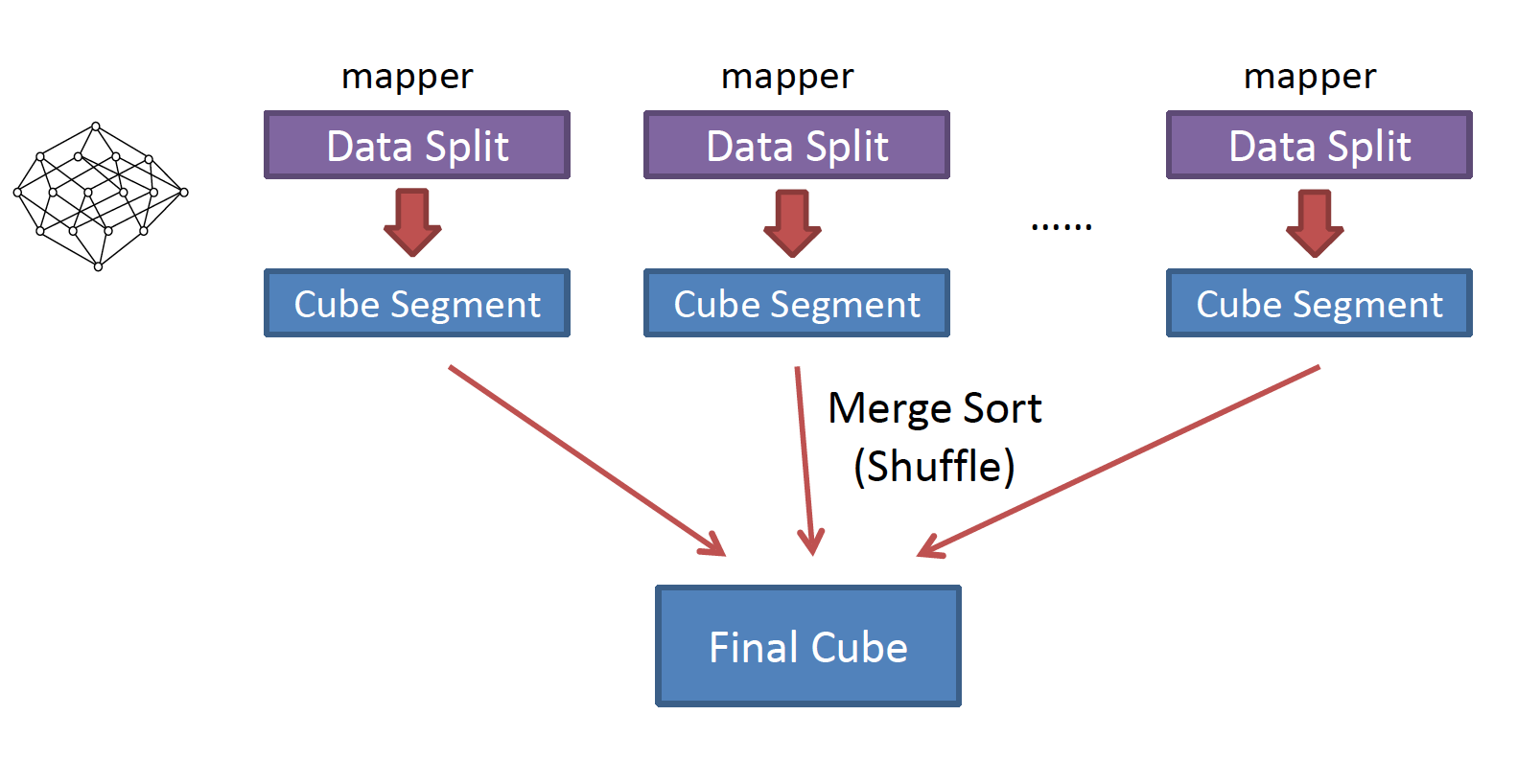
所以 fast cubing 也被称为by segment cubing。如上图所示,该算法的核心思想可以认为是把by layer 中所有的计算全部放在mapper端计算整体数据的一个segment得到一个cube segment (所有计算的结果即cuboids ,存储在内存中),这个cube segment 是最终我们要得到的cube的一部分,所以最后对所有cube segment 进行聚合操作即可得到最中我们需要的cube。
优点:
- 作为对by player on MR的改进,他的速度更快
- 减轻了hadoop的工作压力,减少了输出到hdfs上的中间文件
- 代码可以很容易的被其他计算引擎如spark 重用
缺点:
- 算法较复杂,增加了维护工作量
- 尽管数据可一溢写到磁盘,但是在mapper端扔需要有足够的内存资源才能有比较好的结果。
kylin cubing algorithm(算法)的更多相关文章
- 《Algorithm算法》笔记:元素排序(2)——希尔排序
<Algorithm算法>笔记:元素排序(2)——希尔排序 Algorithm算法笔记元素排序2希尔排序 希尔排序思想 为什么是插入排序 h的确定方法 希尔排序的特点 代码 有关排序的介绍 ...
- C++ algorithm算法库
C++ algorithm算法库 Xun 标准模板库(STL)中定义了很多的常用算法,这些算法主要定义在<algorithm>中.编程时,只需要在文件中加入#include<algo ...
- Algorithm 算法
http://www.cnblogs.com/baiboy/category/723479.html 记下来,有空去看 随笔分类 - Algorithm [项目总结]自然语言处理在现实生活中运用 ...
- C++ vector类型要点总结(以及各种algorithm算法函数)
概述 C++内置的数组支持容器的机制,但是它不支持容器抽象的语义.要解决此问题我们自己实现这样的类.在标准C++中,用容器向量(vector)实现. 容器向量也是一个类模板.vector是C++标准模 ...
- c++11之 algorithm 算法库新增 minmax_element同时计算最大值和最小值
0.时刻提醒自己 Note: vector的释放 1. minmax_element 功能 寻找范围 [first, last) 中最小和最大的元素. 2. 头文件 #include <algo ...
- STL algorithm算法merge(34)
merge原型: std::merge default (1) template <class InputIterator1, class InputIterator2, class Outpu ...
- 06 - 从Algorithm 算法派生类中删除ExecuteInformation() 和ExecuteData() VTK 6.0 迁移
在先前的vtk中,如vtkPointSetAlgorithm 等算法派生类中定义了虚方法:ExecuteInformation() 和 ExecuteData().这些方法的定义是为了平稳的从VTK4 ...
- STL algorithm算法mismatch(37)
mismatch原型: std::mismatch equality (1) template <class InputIterator1, class InputIterator2> p ...
- STL algorithm算法is_permutation(27)
is_permutation原型: std::is_permutation equality (1) template <class ForwardIterator1, class Forwar ...
随机推荐
- 输入一个字母,是元音字母,则输出时元音字母*,否则,输出为辅音字母 (元音字母有:a,e,i,o,u)
import java.util.Scanner; public class test4 { public static void main(String[] args) { // TODO Auto ...
- vue做的第二个app
用vue做应用最好的还是组件的复用上次做饿了吗的app封装了一个评分star的组件只要引入组件传入size大小和score分数就行了,这次做豆瓣直接就就用上了不用重复写代码.不过vue做单页应用全部挂 ...
- react-native-router-flux
这是一个路由,可以用来做Android底部的导航栏,学Android的都知道,如果用原生的代码来 做导航栏,会很复杂,关系到很多复杂的知识. 接下来我就简单的说明一下如何插入和使用吧: 1.你要先依赖 ...
- django的ORM
在项目根目录下运行 python manage.py shell 即可进入django的交互shell界面 查询 from my_app.models import MyTestModel datas ...
- jquery实现本地图片上传预览和限流处理
<html> <head> <meta http-equiv="Content-Type" content="text/html; char ...
- hadoop streaming字段排序介绍
我们在使用hadoop streaming的时候默认streaming的map和reduce的separator不指定的话,map和reduce会根据它们默认的分隔符来进行排序 map.reduce: ...
- [Deep Learning] mini-batch
转自 http://hp.stuhome.net/index.php/2016/09/20/tensorflow_batch_minibatch/ 深度学习的优化算法,说白了就是梯度下降.每次的参数更 ...
- 快速比较 Kafka 与 Message Queue 的区别
https://hackernoon.com/a-super-quick-comparison-between-kafka-and-message-queues-e69742d855a8 A supe ...
- linux 清理几天前的日志或文件
执行清理1天前的 war 包 find . -ctime +1 -name "*.war" -exec rm {} \;
- socket.io 实现简易聊天
客户端: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF- ...