【转载】 强化学习(六)时序差分在线控制算法SARSA
原文地址:
https://www.cnblogs.com/pinard/p/9614290.html
------------------------------------------------------------------------------------------------
在强化学习(五)用时序差分法(TD)求解中,我们讨论了用时序差分来求解强化学习预测问题的方法,但是对控制算法的求解过程没有深入,本文我们就对时序差分的在线控制算法SARSA做详细的讨论。
SARSA这一篇对应Sutton书的第六章部分和UCL强化学习课程的第五讲部分。
1. SARSA算法的引入

这一类强化学习的问题求解不需要环境的状态转化模型,是不基于模型的强化学习问题求解方法。对于它的控制问题求解,和蒙特卡罗法类似,都是价值迭代,即通过价值函数的更新,来更新当前的策略,再通过新的策略,来产生新的状态和即时奖励,进而更新价值函数。一直进行下去,直到价值函数和策略都收敛。
再回顾下时序差分法的控制问题,可以分为两类,一类是在线控制,即一直使用一个策略来更新价值函数和选择新的动作。而另一类是离线控制,会使用两个控制策略,一个策略用于选择新的动作,另一个策略用于更新价值函数。
我们的SARSA算法,属于在线控制这一类,即一直使用一个策略来更新价值函数和选择新的动作,而这个策略是ε-贪婪法,在强化学习(四)用蒙特卡罗法(MC)求解中,我们对于ε-贪婪法有详细讲解,即通过设置一个较小的ε值,使用1-ε的概率贪婪地选择目前认为是最大行为价值的行为,而用ε的概率随机的从所有m个可选行为中选择行为。用公式可以表示为:

2. SARSA算法概述
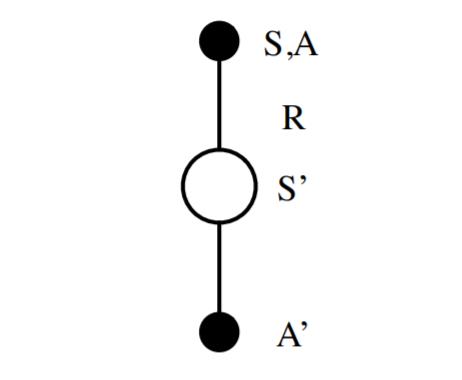
作为SARSA算法的名字本身来说,它实际上是由S,A,R,S,A几个字母组成的。而S,A,R分别代表状态(State),动作(Action),奖励(Reward),这也是我们前面一直在使用的符号。这个流程体现在下图:

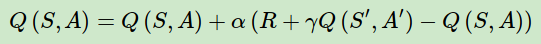

3. SARSA算法流程
下面我们总结下SARSA算法的流程。


4. SARSA算法实例:Windy GridWorld
下面我们用一个著名的实例Windy GridWorld来研究SARSA算法。
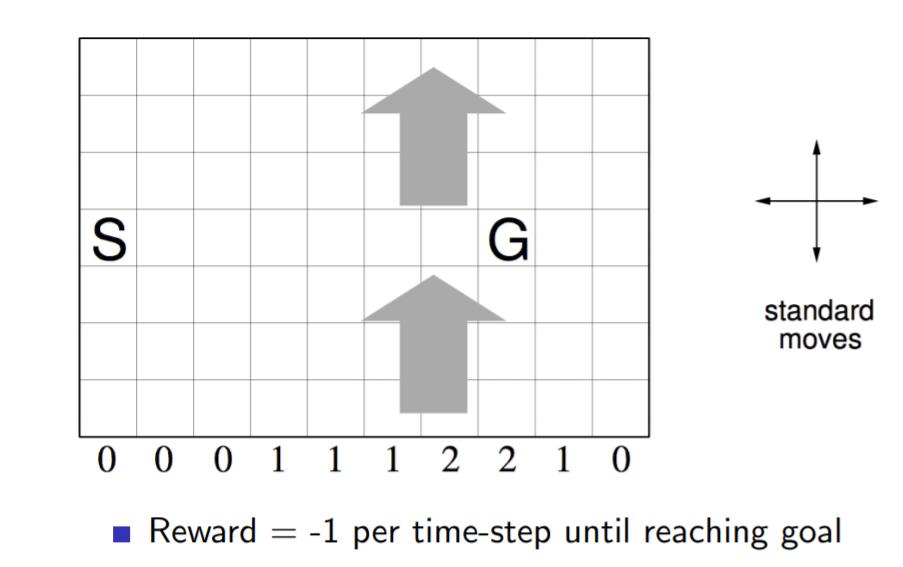
如下图一个10×7的长方形格子世界,标记有一个起始位置 S 和一个终止目标位置 G,格子下方的数字表示对应的列中一定强度的风。当个体进入该列的某个格子时,会按图中箭头所示的方向自动移动数字表示的格数,借此来模拟世界中风的作用。同样格子世界是有边界的,个体任意时刻只能处在世界内部的一个格子中。个体并不清楚这个世界的构造以及有风,也就是说它不知道格子是长方形的,也不知道边界在哪里,也不知道自己在里面移动移步后下一个格子与之前格子的相对位置关系,当然它也不清楚起始位置、终止目标的具体位置。但是个体会记住曾经经过的格子,下次在进入这个格子时,它能准确的辨认出这个格子曾经什么时候来过。格子可以执行的行为是朝上、下、左、右移动一步,每移动一步只要不是进入目标位置都给予一个 -1 的惩罚,直至进入目标位置后获得奖励 0 同时永久停留在该位置。现在要求解的问题是个体应该遵循怎样的策略才能尽快的从起始位置到达目标位置。
逻辑并不复杂,完整的代码在我的github。这里我主要看一下关键部分的代码。

# initialize state
state = START # choose an action based on epsilon-greedy algorithm
if np.random.binomial(1, EPSILON) == 1:
action = np.random.choice(ACTIONS)
else:
values_ = q_value[state[0], state[1], :]
action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)])

def step(state, action):
i, j = state
if action == ACTION_UP:
return [max(i - 1 - WIND[j], 0), j]
elif action == ACTION_DOWN:
return [max(min(i + 1 - WIND[j], WORLD_HEIGHT - 1), 0), j]
elif action == ACTION_LEFT:
return [max(i - WIND[j], 0), max(j - 1, 0)]
elif action == ACTION_RIGHT:
return [max(i - WIND[j], 0), min(j + 1, WORLD_WIDTH - 1)]
else:
assert False

next_state = step(state, action)
if np.random.binomial(1, EPSILON) == 1:
next_action = np.random.choice(ACTIONS)
else:
values_ = q_value[next_state[0], next_state[1], :]
next_action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)])
# Sarsa update
q_value[state[0], state[1], action] += \
ALPHA * (REWARD + q_value[next_state[0], next_state[1], next_action] -
q_value[state[0], state[1], action])
state = next_state
action = next_action
代码很简单,相信大家对照算法,跑跑代码,可以很容易得到这个问题的最优解,进而搞清楚SARSA算法的整个流程。
5. SARSA(λλ)
在强化学习(五)用时序差分法(TD)求解中我们讲到了多步时序差分 TD(λ) 的价值函数迭代方法,那么同样的,对应的多步时序差分在线控制算法,就是我们的 SARSA(λ) 。
TD(λ)有前向和后向两种价值函数迭代方式,当然它们是等价的。在控制问题的求解时,基于反向认识的 SARSA(λ)
算法将可以有效地在线学习,数据学习完即可丢弃。因此 SARSA(λ)算法默认都是基于反向来进行价值函数迭代。
在上一篇我们讲到了 TD(λ) 状态价值函数的反向迭代,即:
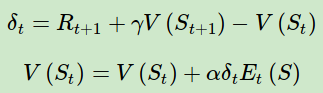
对应的动作价值函数的迭代公式可以找样写出,即:
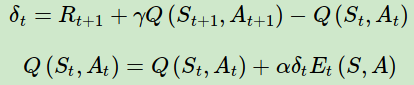


6. SARSA小结
SARSA算法和动态规划法比起来,不需要环境的状态转换模型,和蒙特卡罗法比起来,不需要完整的状态序列,因此比较灵活。在传统的强化学习方法中使用比较广泛。

下一篇我们讨论SARSA的姊妹算法,时序差分离线控制算法Q-Learning。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
--------------------------------------------------------------------------------------------------
#######################################################################
# Copyright (C) #
# 2016-2018 Shangtong Zhang(zhangshangtong.cpp@gmail.com) #
# 2016 Kenta Shimada(hyperkentakun@gmail.com) #
# Permission given to modify the code as long as you keep this #
# declaration at the top #
#######################################################################
##https://www.cnblogs.com/pinard/p/9614290.html ##
## 强化学习(六)时序差分在线控制算法SARSA ## import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt # world height
WORLD_HEIGHT = 7 # world width
WORLD_WIDTH = 10 # wind strength for each column
WIND = [0, 0, 0, 1, 1, 1, 2, 2, 1, 0] # possible actions
ACTION_UP = 0
ACTION_DOWN = 1
ACTION_LEFT = 2
ACTION_RIGHT = 3 # probability for exploration
EPSILON = 0.1 # Sarsa step size
ALPHA = 0.5 # reward for each step
REWARD = -1.0 START = [3, 0]
GOAL = [3, 7]
ACTIONS = [ACTION_UP, ACTION_DOWN, ACTION_LEFT, ACTION_RIGHT] def step(state, action):
i, j = state
if action == ACTION_UP:
return [max(i - 1 - WIND[j], 0), j]
elif action == ACTION_DOWN:
return [max(min(i + 1 - WIND[j], WORLD_HEIGHT - 1), 0), j]
elif action == ACTION_LEFT:
return [max(i - WIND[j], 0), max(j - 1, 0)]
elif action == ACTION_RIGHT:
return [max(i - WIND[j], 0), min(j + 1, WORLD_WIDTH - 1)]
else:
assert False # play for an episode
def episode(q_value):
# track the total time steps in this episode
time = 0 # initialize state
state = START # choose an action based on epsilon-greedy algorithm
if np.random.binomial(1, EPSILON) == 1:
action = np.random.choice(ACTIONS)
else:
values_ = q_value[state[0], state[1], :]
action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)]) # keep going until get to the goal state
while state != GOAL:
next_state = step(state, action)
if np.random.binomial(1, EPSILON) == 1:
next_action = np.random.choice(ACTIONS)
else:
values_ = q_value[next_state[0], next_state[1], :]
next_action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)]) # Sarsa update
q_value[state[0], state[1], action] += \
ALPHA * (REWARD + q_value[next_state[0], next_state[1], next_action] -
q_value[state[0], state[1], action])
state = next_state
action = next_action
time += 1
return time def sarsa():
q_value = np.zeros((WORLD_HEIGHT, WORLD_WIDTH, 4))
episode_limit = 500 steps = []
ep = 0
while ep < episode_limit:
steps.append(episode(q_value))
# time = episode(q_value)
# episodes.extend([ep] * time)
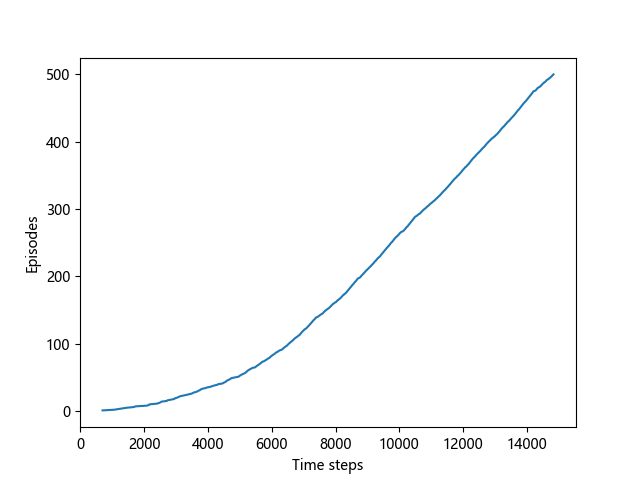
ep += 1 steps = np.add.accumulate(steps) plt.plot(steps, np.arange(1, len(steps) + 1))
plt.xlabel('Time steps')
plt.ylabel('Episodes') plt.savefig('./sarsa.png')
plt.close() # display the optimal policy
optimal_policy = []
for i in range(0, WORLD_HEIGHT):
optimal_policy.append([])
for j in range(0, WORLD_WIDTH):
if [i, j] == GOAL:
optimal_policy[-1].append('G')
continue
bestAction = np.argmax(q_value[i, j, :])
if bestAction == ACTION_UP:
optimal_policy[-1].append('U')
elif bestAction == ACTION_DOWN:
optimal_policy[-1].append('D')
elif bestAction == ACTION_LEFT:
optimal_policy[-1].append('L')
elif bestAction == ACTION_RIGHT:
optimal_policy[-1].append('R')
print('Optimal policy is:')
for row in optimal_policy:
print(row)
print('Wind strength for each column:\n{}'.format([str(w) for w in WIND])) if __name__ == '__main__':
sarsa()

【转载】 强化学习(六)时序差分在线控制算法SARSA的更多相关文章
- 强化学习(六)时序差分在线控制算法SARSA
在强化学习(五)用时序差分法(TD)求解中,我们讨论了用时序差分来求解强化学习预测问题的方法,但是对控制算法的求解过程没有深入,本文我们就对时序差分的在线控制算法SARSA做详细的讨论. SARSA这 ...
- 【转载】 强化学习(七)时序差分离线控制算法Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9669263.html ------------------------------------------------ ...
- 强化学习(七)时序差分离线控制算法Q-Learning
在强化学习(六)时序差分在线控制算法SARSA中我们讨论了时序差分的在线控制算法SARSA,而另一类时序差分的离线控制算法还没有讨论,因此本文我们关注于时序差分离线控制算法,主要是经典的Q-Learn ...
- 强化学习8-时序差分控制离线算法Q-Learning
Q-Learning和Sarsa一样是基于时序差分的控制算法,那两者有什么区别呢? 这里已经必须引入新的概念 时序差分控制算法的分类:在线和离线 在线控制算法:一直使用一个策略选择动作和更新价值函数, ...
- 强化学习4-时序差分TD
之前讲到强化学习在不基于模型时可以用蒙特卡罗方法求解,但是蒙特卡罗方法需要在每次采样时生产完整序列,而在现实中,我们很可能无法生成完整序列,那么又该如何解决这类强化学习问题呢? 由贝尔曼方程 vπ(s ...
- [转载]MongoDB学习 (六):查询
本文地址:http://www.cnblogs.com/egger/archive/2013/06/14/3135847.html 欢迎转载 ,请保留此链接๑•́ ₃•̀๑! 本文将介绍操作符的使用 ...
- 【转载】 强化学习(五)用时序差分法(TD)求解
原文地址: https://www.cnblogs.com/pinard/p/9529828.html ------------------------------------------------ ...
- 强化学习(五)用时序差分法(TD)求解
在强化学习(四)用蒙特卡罗法(MC)求解中,我们讲到了使用蒙特卡罗法来求解强化学习问题的方法,虽然蒙特卡罗法很灵活,不需要环境的状态转化概率模型,但是它需要所有的采样序列都是经历完整的状态序列.如果我 ...
- 强化学习之 免模型学习(model-free based learning)
强化学习之 免模型学习(model-free based learning) ------ 蒙特卡罗强化学习 与 时序查分学习 ------ 部分节选自周志华老师的教材<机器学习> 由于现 ...
随机推荐
- InnoDB行记录格式(compact)、InnoDB数据页结构
1. compact 行记录格式: 变长字段长度列表,null标志位,记录头信息,列1数据,列2数据 …… 记录头信息中包含许多信息,只列举一部分: 名称 大小 描述 deleted_flag 1bi ...
- httpd.conf文件格式解析
apache http server,俗称apache,程序名httpd,默认配置文件/etc/httpd/conf/httpd.conf:该文件通过其中的Include conf.d/*.conf指 ...
- QPainter、QPainterPath、QBrush
参考资料: https://blog.csdn.net/qq_35488967/article/details/70802973https://blog.csdn.net/wanghualin033/ ...
- windows7时间同步设置
1. 设置同步源 服务器修改为本车的104的ip地址,例如23车,手动输入 96.3.123.104 2. 设置同步周期. 注册表法 在“运行”框输入“Regedit”进入注册表编辑器 这种方法是通过 ...
- js 敏感词过滤
<!doctype html> <html> <head> <meta charset="utf-8"> <meta name ...
- [HDU3726]Graph and Queries
Problem 给你一张图,点的权值,边和几个操作: D x: 删除第x条边 Q x y: 询问包含x的联通块中权值第y大的权值 C x y: 将x这个点的权值改为y Solution 一看就要离线处 ...
- python全栈开发笔记-----------概要
Python开发 开发: 开发语言: 高级语言:python.Java.php .C# .Go .ruby . C++ .... ===>字节码 低级语言:C.汇编 ...
- Win10访问不到XP共享的解决:
不知道别人的是怎么解决. 反正我这么解决了. 我的win10笔记本,是使用windows帐户登陆的.可以同步很多东西. 同事的电脑是台式老古董XP. 扫描不到网上邻居,手动\\ip也访问不到. 最后安 ...
- Java 中的代理模式及动态代理
原文:https://blog.csdn.net/briblue/article/details/73928350
- <Spark><Spark Streaming><作业分析><JobHistory>
Intro 这篇是对一个Spark (Streaming)作业的log进行分析.用来加深对Spark application运行过程,优化空间的各种理解. Here to Start 从我这个初学者写 ...