(NLP)关键词提取之——TF-IDF解析
关键词提取——TF-IDF
1 TF-IDF定义
概要
tf-idf(英语:term frequency–inverse document frequency)是一种用于信息检索与文本挖掘的常用加权技术。tf-idf是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。tf-idf加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了tf-idf以外,互联网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜索结果中出现的顺序。
什么是TF:
TF意为Term Frequency ,即为词频,用于衡量一个词在一篇文档中出现的频率。
什么是IDF
IDF意为Inverse Document Frequency,为逆文档频率,衡量一个词在整个语料库中的稀有程度。
什么是TF-IDF
TF-IDF为TF与IDF的乘积
2 TF-IDF公式
2-1 TF公式:
公式:TF(t,d)= \frac {f_{t,d}} {\sum_{k} f_{k,d}}

公式解释:
分子:
F t,d表示词 t 在文档 d 中出现的次数分母:文档 d 中所有词的总数
PS:其实就是词频,这个词在当前文档d出现次数 / 文档d中词数数量
2-2 IDF公式
注意,此IDF公式经过平滑,在分母加了1,原版IDF公式分母只有nt
公式:IDF(t)=log(\frac{N}{1+n_t})

公式解释:
N:总文档数。
1+nt:包含词 t 的文档数(注意 +1 防止除以 0)。
2-3 TF-IDF公式
公式:TF-IDF(t,d)=TF(t,d)*IDF(t)

公式解释:
本质上就是TF与IDF相乘
3 TF-IDF编码实现
3-0 简要步骤:
主要分为以下几个步骤:
- 批量文档分词并保存
- 读取分词结果,计算TF值以及IDF值
- 获取关键词
3-1批量文档分词并保存:
目前中文分词常用的有:
- jieba【结巴分词】
- pkuseg【一个多领域中文分词工具包】
- thulac【THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包】
这里以pku和jieba,给一个框架作为参考,具体还需要补全:
import jieba, pkuseg,thulac
def tokenize_pku(text:str):
"""
使用pku分词
:param text: 输入的文本
:return: 分词后的 token 列表
"""
seg = pkuseg.pkuseg()
tokens = seg.cut(text) #分词
#你对于分词做处理,保存
print(tokens)
return tokens
def tokenize_by_jieba(sentence: str):
"""
使用 jieba 对中文句子进行分词
:param sentence: 待分词的中文句子
:return: 分词后的 token 列表
"""
tokens = list(jieba.cut(sentence, cut_all=False)) # 精确模式
print(tokens)
return tokens
if __name__ == '__main__':
tokenize_pku("这里以`pku`和`jieba`,给一个框架作为参考,具体还需要补全")
tokenize_by_jieba("这里以`pku`和`jieba`,给一个框架作为参考,具体还需要补全")
保存我这里就不写了,我当时使用的数据库保存,对于没有学过数据库的用户可能不友好,而且数据库配置各不相同,后续只需要用你会用的保存方式保存即可,思路一致就好。
3-2 计算TF-IDF
3-2-1 计算TF
其实只需要两个参数,一个是关键词,一个是本书总词数,即所计算的关键词所在的书中一共有多数词数。只要理解什么是关键词和本书的总词数就好编码了。我们来举个例子。
举个栗子:
假设我们以法律来分词,法律有刑法、宪法、民法。
我们以刑法举例来计算刑法里面的关键字,假设为“缓刑”,这个关键词的词频TF。
假设刑法里面只有如下的文本{缓刑、拘役、管制、缓刑},那TF所指的总词数就是4,不受其他法律文书的影响,因为词频只针对当前文档
编码:
def TF_calculate(keyword_count, book_all_word_count:int):
"""
计算词频
:param keyword_count: 关键字出现词数
:param book_all_word_count: 单本法律文书的词汇总数
:return: 计算后的TF
"""
return float(keyword_count) / float(book_all_word_count)
至于如何提取关键词词数、文书中包含多少词,这个因人而异,了解了核心比较关键,细枝末节我相信读者是可以实现的。
3-2-2 计算IDF
举个栗子:
计算IDF相比计算TF会相对难一点,但其实也没那么难,主要需求两个变量:
- 文档总数量N:按照上面那个例子,这里的N应该是3,总有3本书
- 出现次数
nt:假设只有刑法出现过了关键词【缓刑】,那这里的nt为1
注意事项:
IDF的计算公式我建议使用平滑的,因为如果不加1,假设关键词在所有书中全部出现了,那
N/nt =1再经过log就变成0了这里你可以根据需求使用不同的log底数,我这里使用的是自然对数
如果文本量不大的话不用担心精度丢失,以我自己进行处理的文本为例,单书2w多词进行TF-IDF效果还是比较可以的,计算的精度也没有丢失。如果实在有需要可以观察一下并进行处理【一般用户应该用不上】
编码:
- 这个是我叫ai帮我写的,大致的计算就是这样子,你们可以参考一下:
def IDF_calculate(N: int, nt: int) -> float:
"""
计算 IDF(逆文档频率),使用平滑公式:IDF(t) = log(N / (1 + nt))
:param N: 文档总数
:param nt: 包含词 t 的文档数量
:return: 平滑后的 IDF 值
"""
if N <= 0:
raise ValueError("文档总数 N 必须大于 0")
return math.log(N / (1 + nt))
我自己在实际运用的情况:
主要还是怎么找到出现次数nt就好了,因为要跨文书,所以是有一点难点
def IDF_calculate(key_word:db.Key_word):
"""
计算IDF 逆文档频率
:param key_word:关键字表类
:return: 返回计算好的IDF
"""
word = key_word.word
idf_session = db.Session()
N_data = db.get_info(db.Key_word, "law_name")#获取文档总数
N = float(len(N_data))
nt_all_doc = idf_session.query(db.Key_word).filter(db.Key_word.word==word).all()#获取包含这个关键字的文档数量【没有针对不同分词方式去重】
nt_count = float(len(nt_all_doc))
IDF = math.log( N/ nt_count+1)
idf_session.close()
return IDF
3-2-3 TF-IDF
两个函数的结果相乘就好。
3-3 后续
后续可以根据你自己需要进行关键字提取的测试,以我实现的效果举例:
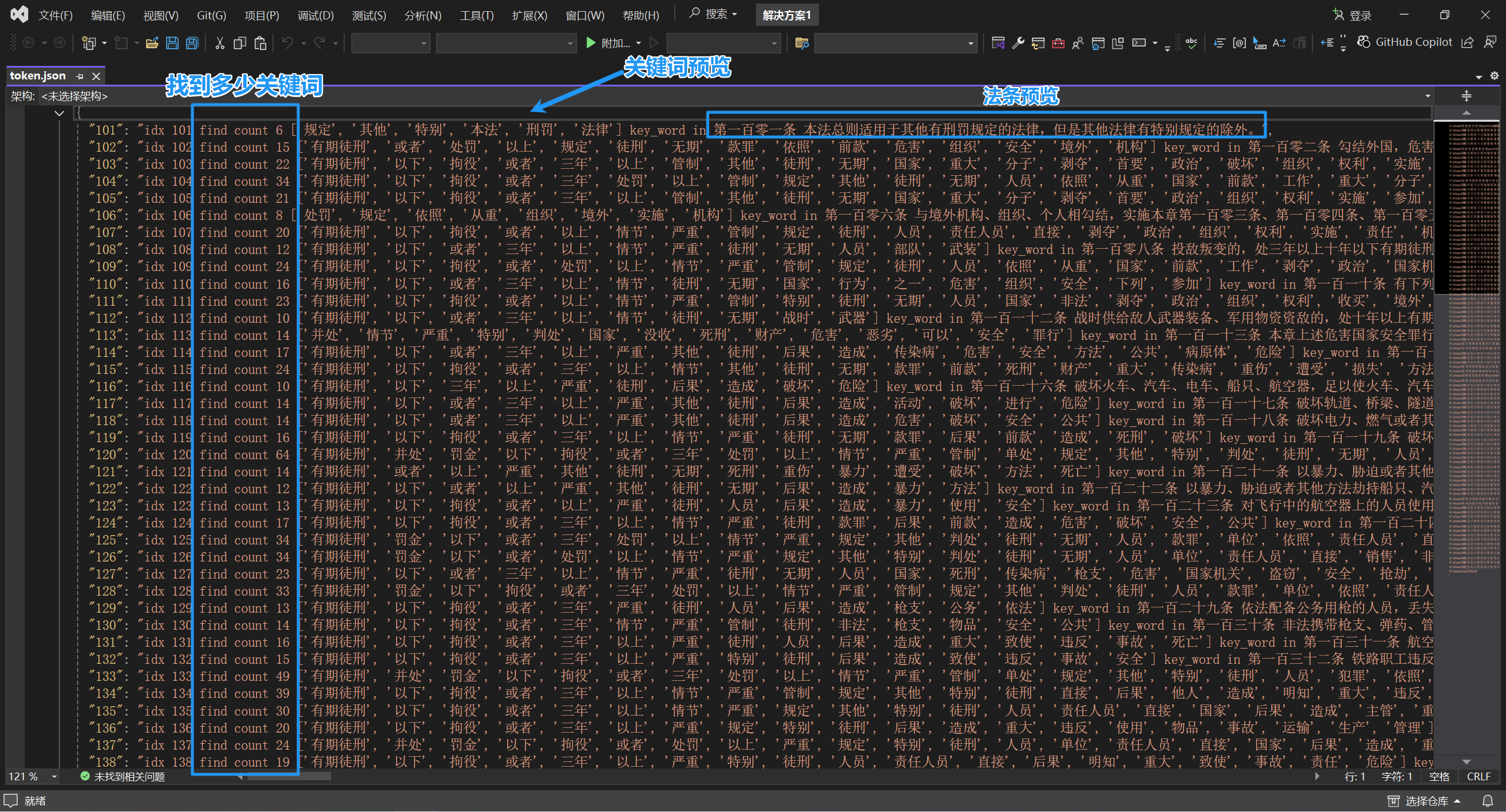
希望能够帮助你了解TF-IDF,网上的说明不是特别清楚,因此发此篇博客,也不能说有多专业,仅为个人的理解。
(NLP)关键词提取之——TF-IDF解析的更多相关文章
- python——NLP关键词提取
关键词提取顾名思义就是将一个文档中的内容用几个关键词描述出来,这样这几个关键词就可以提供这个文档的大部分信息,从而提高信息获取效率. 关键词提取方法同样分为有监督和无监督两类,有监督的方法比如构造一个 ...
- NLP自然语言处理 jieba中文分词,关键词提取,词性标注,并行分词,起止位置,文本挖掘,NLP WordEmbedding的概念和实现
1. NLP 走近自然语言处理 概念 Natural Language Processing/Understanding,自然语言处理/理解 日常对话.办公写作.上网浏览 希望机器能像人一样去理解,以 ...
- NLP之关键词提取(TF-IDF、Text-Rank)
1.文本关键词抽取的种类: 关键词提取方法分为有监督.半监督和无监督三种,有监督和半监督的关键词抽取方法需要浪费人力资源,所以现在使用的大多是无监督的关键词提取方法. 无监督的关键词提取方法又可以分为 ...
- Gradle +HanLP +SpringBoot 构建关键词提取,摘要提取 。入门篇
前段时间,领导要求出一个关键字提取的微服务,要求轻量级. 对于没写过微服务的一个小白来讲.有点赶鸭子上架,但是没办法,硬着头皮上也不能说不会啊. 首先了解下公司目前的架构体系,发现并不是分布式开发,只 ...
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- python实现关键词提取
今天我来弄一个简单的关键词提取的代码 文章内容关键词的提取分为三大步: (1) 分词 (2) 去停用词 (3) 关键词提取 分词方法有很多,我这里就选择常用的结巴jieba分词:去停用词,我用了一个停 ...
- 关键词提取TF-IDF算法/关键字提取之TF-IDF算法
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与信息探勘的常用加权技术.TF的意思是词频(Term - frequency), ...
- Python调用百度接口(情感倾向分析)和讯飞接口(语音识别、关键词提取)处理音频文件
本示例的过程是: 1. 音频转文本 2. 利用文本获取情感倾向分析结果 3. 利用文本获取关键词提取 首先是讯飞的语音识别模块.在这里可以找到非实时语音转写的相关文档以及 Python 示例.我略作了 ...
- 关键词提取算法TF-IDF与TextRank
一.前言 随着互联网的发展,数据的海量增长使得文本信息的分析与处理需求日益突显,而文本处理工作中关键词提取是基础工作之一. TF-IDF与TextRank是经典的关键词提取算法,需要掌握. 二.TF- ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
随机推荐
- JS实现隐藏手机号码中间4位数
代码COPY 3. 使用正则 function geTel(tel){ var reg = /^(\d{3})\d{4}(\d{4})$/; return tel.replace(reg, " ...
- css 各种居中
1. 内部容器居中 flex <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
从 Chrome 125 开始,支持了一个全新的 CSS 特性 - Anchor Positioning,翻译过来即是锚点定位. 在之前的文章中,我们较为系统的讲述了这个新特性的使用,感兴趣的可以翻开 ...
- pycharm clone GitHub 提示 OpenSSL SSL_read: Connection was reset, errno 10054
配置界面 错误提示 原因分析 clone的时候需要安全认证,当你在配置页面勾选上ssh ,就会报错 解决方案 在cmd里输入命令,然后再clone git config --global http.s ...
- Web前端入门第 12 问:HTML 常用属性一览
HELLO,这里是大熊学习前端开发的入门笔记. 本系列笔记基于 windows 系统. HTML 常用属性大约 70 个,是否又头大了?脸上笑嘻嘻,心里嘛...嘿嘿... 温馨提示:属性不用死记硬背, ...
- DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
大家好,我是狂师. 前阵子在知乎闲逛时,有个问题激起了大家的热议:"DeepSeek 如何颠覆传统软件测试?测试工程师会被淘汰吗".这看似简单的一问,激起层层思考,针对这个问题,今 ...
- python3 报错ModuleNotFoundError: No module named 'apt_pkg'
前言 apt update无法执行,python3 报错 ModuleNotFoundError: No module named 'apt_pkg' 这是因为将 python 版本升级后的问题 正确 ...
- Django实战项目-学习任务系统-用户登录
第一步:先创建一个Django应用程序框架代码 1,先创建一个Django项目 django-admin startproject mysite 将创建一个目录,其布局如下: mysite/ mana ...
- VulnHub2018_DeRPnStiNK靶机渗透练习
据说该靶机有四个flag 扫描 扫描附近主机arp-scan -l 扫主目录 扫端口 nmap -sS -sV -n -T4 -p- 192.168.xx.xx 结果如下 Starting Nmap ...
- 使用Docker部署服务
一.Docker概念 1.操作系统层面的虚拟化技术 2.隔离的进程独立于宿主和其它的隔离的进程 - 容器 3.GO语言开发 4.特点:高效的利用系统资源:快速的启动时间:一致的运行环境:持续交付和部署 ...