python反爬之网页局部刷新1
# ajax动态加载网页
# 怎样判断一个网页是不是动态加载的呢?
# 查看网页源代码,如果源码中没有你要的数据,尝试访问下一页,当你点击下一页的时候,整个页面没有刷新, 只是局部刷新了,很大的可能是ajax加载
# 遇到ajax加载,一般的解决步骤就,通过浏览器或者软件抓包分析响应的请求,查看response里面哪个有你需要的数据,
# 然后再分析headers请求的网址,直接向哪个网址请求即可,当然还会有一些接口需要构建post请求
import json
import jsonpath
import requests
headers = {
'User-Agent':"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10",
}
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&_v=0.11045029&x-zp-page-request-id=7d6ccc963ff14b1d995b6f21942f2295-1542632726829-135321'
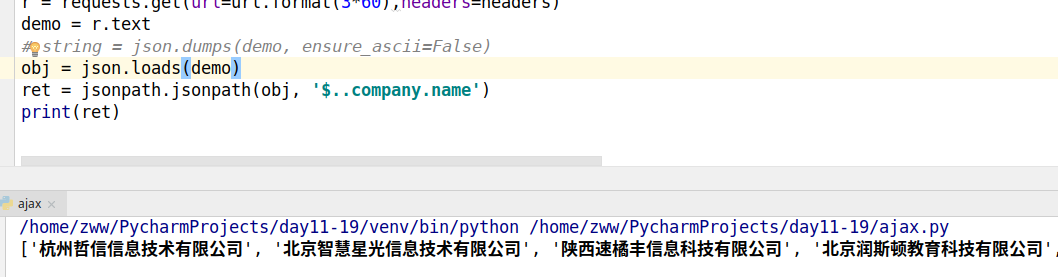
r = requests.get(url=url.format(3*60),headers=headers)
demo = r.text
# string = json.dumps(demo, ensure_ascii=False)
obj = json.loads(demo)
ret = jsonpath.jsonpath(obj, '$..company.name')
print(ret)# ajax动态加载网页
# 怎样判断一个网页是不是动态加载的呢?
# 查看网页源代码,如果源码中没有你要的数据,尝试访问下一页,当你点击下一页的时候,整个页面没有刷新,
# 只是局部刷新了,很大的可能是ajax加载
# 遇到ajax加载,一般的解决步骤就,通过浏览器或者软件抓包分析响应的请求,查看response里面哪个是需要的数据,
# 然后再分析headers请求的网址,直接向哪个网址请求即可,当然还会有一些接口需要构建post请求
#导入的包如果下面出现红色波浪线,pip install 名字 即可
import json
import jsonpath
import requests
headers = {
'User-Agent':"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10",
}
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&_v=0.11045029&x-zp-page-request-id=7d6ccc963ff14b1d995b6f21942f2295-1542632726829-135321'
r = requests.get(url=url.format(3*60),headers=headers)
demo = r.text
# string = json.dumps(demo, ensure_ascii=False)
obj = json.loads(demo)
ret = jsonpath.jsonpath(obj, '$..company.name')
print(ret)
-----网页抓包----
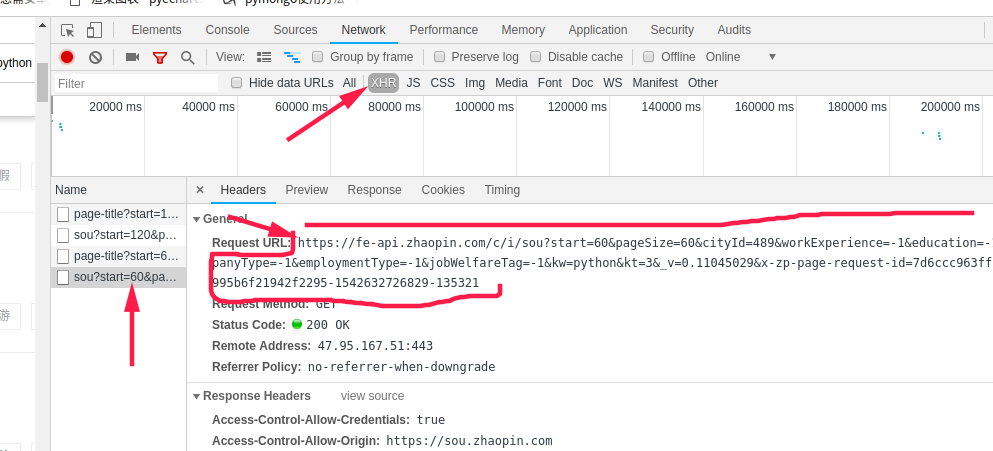
通过观察,改变start后面数字,会出现不同的数据,第一页是0,第二页是60,依次递增,pagesize则是每一页出现多少条,最好不要改变
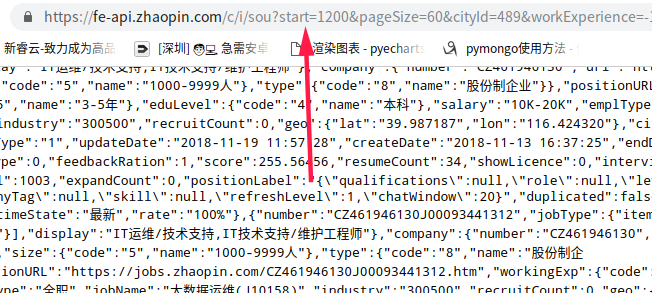
将网页中的内容粘贴到在线json解析中,可以看到,这是一个标准的json数据,通过在线解析可以看到清晰的结构

获取到的数据是一个json格式的字符串,需要使用jsonpath进行解析,获取里面的内容,图中选取了当前请求的公司名
python反爬之网页局部刷新1的更多相关文章
- python之爬取网页数据总结(一)
今天尝试使用python,爬取网页数据.因为python是新安装好的,所以要正常运行爬取数据的代码需要提前安装插件.分别为requests Beautifulsoup4 lxml 三个插件 ...
- python反爬之懒加载
# 在平时的爬虫中,如果遇到没有局部刷新,没有字体加密,右键检查也能看到清晰的数据,但是按照已经制定好的解析规则进行解析时,会返回空数据,这是为什么呢,这时可以在网页右键查看一下网页源代码,可以发现, ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
- python动态爬取网页
简介 有时候,我们天真无邪的使用urllib库或Scrapy下载HTML网页时会发现,我们要提取的网页元素并不在我们下载到的HTML之中,尽管它们在浏览器里看起来唾手可得. 这说明我们想要的元素是在我 ...
- python 嵌套爬取网页信息
当需要的信息要经过两个链接才能打开的时候,就需要用到嵌套爬取. 比如要爬取起点中文网排行榜的小说简介,找到榜单网址:https://www.qidian.com/all?orderId=&st ...
- Python爬虫爬取网页图片
没想到python是如此强大,令人着迷,以前看见图片总是一张一张复制粘贴,现在好了,学会python就可以用程序将一张张图片,保存下来. 今天逛贴吧看见好多美图,可是图片有点多,不想一张一张地复制粘贴 ...
- python反爬之动态字体相关文档
web_font的一些基本原理 https://blog.csdn.net/fdipzone/article/details/68166388 实例1 猫眼电影 http://www.cnblogs. ...
- python反爬之封IP
# requests是第三方库,需要安装 pip install requests import requests # 在日常的爬虫中,封ip也是一个很常用的反爬虫手段,遇到这种情况,我们只需要在每次 ...
- 1.记我的第一次python爬虫爬取网页视频
It is my first time to public some notes on this platform, and I just want to improve myself by reco ...
随机推荐
- cenos 上的php 支持GD库问题
---恢复内容开始--- thinkphp 开发的项目verify类无法引用,原因是没有开启gd库 环境:CentOS 6.4,php-5.3.3需求:php支持GD库解决方案:GD是Linux下的一 ...
- k8s标签
一.标签是什么 标签是k8s特色的管理方式,便于分类管理资源对象. 一个标签可以对应多个资源,一个资源也可以有多个标签,它们是多对多的关系. 一个资源拥有多个标签,可以实现不同维度的管理. 可以使用标 ...
- C++基础学习8:类的定义(class)
先来说说C和C++中结构体的不同 a) C语言中的结构体不能为空,否则会报错(??) b) C语言中内存为空结构体分配大小为0,C++中为结构体和类分配大小为1byte c) C语言中的结构体只涉及到 ...
- Fxx and game hdu 5945 单调队列dp
dfs你怕是要爆炸 考虑dp; 很容易想到 dp[ i ] 表示到 i 时的最少转移步数: 那么: dp[ i ]= min( dp[ i ],dp[ i-j ]+1 ); 其中 i-t<=j& ...
- 用勤哲excel服务器开发设计燃烧器生产行业ERP
J公司是一家专业从事设计.制造.生产及销售各类燃油燃气燃烧设备和各类冶金燃烧装置的专业公司.2011年随着企业的发展,原来手工操作模式已经很难应付日益增长的工作量. J公司希望通过软件管理实现以下几个 ...
- 实验吧之Canon
解压zip文件得到一个mp3文件和一个zip压缩包,解压需要密码,那密码就在mp3里面,使用MO3Stego好像不能解析出文本,说明解析需要密码,此时通过网上的讨论说标题Canon就是密码,就试着用了 ...
- pytorch构建优化器
这是莫凡python学习笔记. 1.构造数据,可以可视化看看数据样子 import torch import torch.utils.data as Data import torch.nn.func ...
- C语言常用字符串函数总结
ANSI C中有20多个用于处理字符串的函数: 注意:const 形参使用了const限定符,表示该函数不会改变传入的字符串.因为源字符串是不能更改的. strlen函数: 函数原型:unsigned ...
- hdu3038判断区间谎言(带权并查集)
题目传送门 题目描述:给你n,m,n代表从1到n这么大的数组,m组v,u,val,代表v到u这个区间的总和是val,然后让你判断m组关系中有几组是错误的. 思路:带权并查集,这道题其实算是让我知道什么 ...
- day19 MRO C3算法 super()
1. MRO(Method Resolution Order):方法解析顺序,主要用于在多继承时判断调的属性的路径(来自于哪个类). 1.Python语言包含了很多优秀的特性,其中多重继承就是其中之一 ...