Hadoop中mapreduce作业日志是如何生成的
摘要:本篇博客介绍了hadoop中mapreduce类型的作业日志是如何生成的。主要介绍日志生成的几个关键过程,不涉及过多细节性的内容。
本文分享自华为云社区《hadoop中mapreduce作业日志是如何生成的》,作者:mxg。
我们知道hadoop分为三大块:HDFS,Yarn,Mapreduce。其中mapreduce相关的核心代码都在hadoop-mapreduce-project子工程中。

其中比较重要的功能模块有:MRAppMaster, JobHistory,以及mapreduceClient,分别对应上面的app,hs和jobclient。当然还有一些公共的工具类这里不再细表。
MRAppMaster:作为一个yarn application运行的第一个Container,用于为所属的mapreduce job申请task资源,并且监控task的运行状态。
注意这里引入了名词:yarn application和mapreduce job,其实是同一个事物两种不同层面下的叫法。Yarn里面运行的所有的应用都称之为application,而job是一个mapreduce类型的application在mapreduce框架下的叫法,在其他计算框架下可能又有别的叫法,总之一点,无论在计算框架侧怎么叫,在yarn这里都是yarn application。
记住这些开源社区既定的名词有助于我们理解代码,例如当看到job相关的接口,潜意识就要反应过来,这是jobhistory或者MRAppMaster的接口,如果是Application相关的接口,那么这肯定是ResourceManager的接口。
HistoryServer:我们知道yarn application 在AM运行的时候,默认会将这个job的运行日志上传到hdfs路径:/tmp/hadoop-yarn/staging,当然也可以使用参数:yarn.app.mapreduce.am.staging-dir配置成任何想要的路径。甚至可以跨域文件系统,例如不在hdfs上面存储。AM日志最终会组织成一个特定的格式jhist,HistoryServer会去解析,并通过web页面友好的展示出来。
jobclient:提供一些接口用于用于job的管理,例如作业的提交。
下面介绍下一个mapreduce job的AM日志生成的几个阶段。其中设计三个重要的参数:
1-运行完的mr作业的临时日志目录;
mapreduce.jobhistory.intermediate-done-dir:/mr-history/tmp
2-运行完的mr作业的最终目录
mapreduce.jobhistory.done-dir: /mr-history/done
3-AM运行过程中的日志持久化目录
yarn.app.mapreduce.am.staging-dir: /tmp/hadoop-yarn/staging
下面介绍AM日志在job运行的不同阶段在上面的三个目录中是如何转移的。
Phase1
AM的运行日志会存放到hdfs路径:/tmp/hadoop-yarn/staging,并且在job运行的过程中一直动态更新.
Phase2
Job运行完成之后,AM会将/tmp/hadoop-yarn/staging路径下面的job日志拷贝到/mr-history/tmp路径下(包含:jhist文件,summary文件以及conf.xml文件),刚拷贝过去的时候这些文件均已.tmp为后缀;
完全拷贝成功之后才会将tmp后缀的文件全部重命名为正常的文件名;

Phase3
JobHistoryServer进程中有一个JobHistory类型的Service(参考JHS的初始化过程以及服务介绍章节)
而JobHistory这个Service功能很简单:
1-定时将phase2生成的/mr-history/tmp目录下的完成job的日志拷贝到/mr-history/done目录下,当然拷贝完之后即删除/mr-history/tmp下面的日志文件;
2-定时扫描/mr-history/done目录下的job日志文件,将超过生存周期的全部删掉,即删掉之后的job信息将不能在JobHistoryServer 的web页面中看到了。
因此对于一个已经运行结束的mapreduce job,我们从JobHistoryServer的web页面上可以正常访问其job日志以及每一个task的日志。其实就是访问了/mr-history/done和/tmp/logs/日志。
其中/mr-history/done/里面记录了job的一些配置以及task的基本概况信息(多少map,多少reduce,多少成功,多少失败等)。
其中/tmp/logs种记录了application中所有的container(即task)的详细日志,从job页面跳转到task页面的数据就是从这里获取的。
细心的小伙伴可能已经注意到了,phase2的AM日志截图中不难看出,在作业运行完成之后,日志拷贝到intermediate-dir之前,首先设置了这个job日志的链接。这个链接其实就是jobhistoryServer web服务的地址。
一个典型的正在运行的application在yarn的原生页面中的信息如下图所示。其链接为:https://{RESOURCEMANAGER_IP}:{PORT}/Yarn/ResourceManager/45/proxy/application_1636508815320_0003/。
显然,这时候访问的还是resourceManager,也就是说在运行的过程当时还和jobhistoryServer没有什么关系。

类似的,如果我们要查看一个运行过程中的job的某些已经运行结束的task的详细日志信息,那么将会访问相应的nodemanager获取,如下图所示。
从链接信息中也不难看出,这里访问的是nodemanager,该过程也和jobhistoryServer没有什么关系。

然而当一个yarn application运行结束的之后,application概览页面的History链接就不再是上面的ResourceManager链接了,转而变成了JobHistoryServer链接。
也即是说对于一个运行过程中的job,页面上的所有日志访问请求都是yarn承接的,而对于已经运行结束的job,除了yarn的application 页面概览之外,之后的所有请求都会跳转到JobHistoryServer来处理。
一个运行结束的job的连接可能是这样:https://{RESOURCEMANAGER_IP}:{PORT}/Yarn/ResourceManager/45/proxy/application_1636508815320_0003/
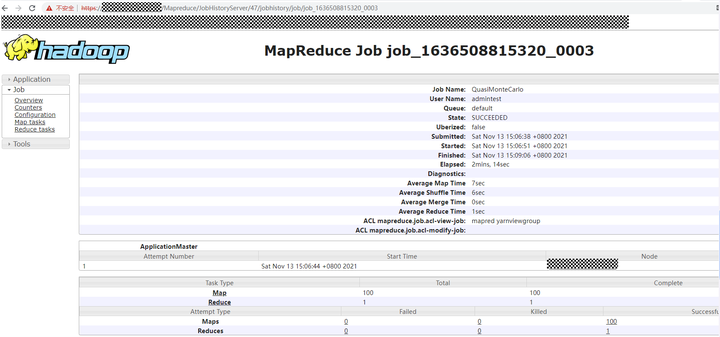
同样,对于一个已经运行完成的job,查看其某一个task/container日志的时候也是由JobHistoryServer进行处理的。

Hadoop中mapreduce作业日志是如何生成的的更多相关文章
- Hadoop中MapReduce作业流程图
MapReduce的流程分为11个步骤,4个实体 1.客户端:编写MapReduce的代码,配置作业,提交作业 2.JobTracker:初始化作业,分配作业,与TaskTracker通信,协调整个作 ...
- hadoop中MapReduce中压缩的使用及4种压缩格式的特征的比较
在比较四中压缩方法之前,先来点干的,说一下在MapReduce的job中怎么使用压缩. MapReduce的压缩分为map端输出内容的压缩和reduce端输出的压缩,配置很简单,只要在作业的conf中 ...
- [转]hadoop运行mapreduce作业无法连接0.0.0.0/0.0.0.0:10020
14/04/04 17:15:12 INFO mapreduce.Job: map 0% reduce 0% 14/04/04 17:19:42 INFO mapreduce.Job: map 4 ...
- 浅谈hadoop中mapreduce的文件分发
近期在做数据分析的时候.须要在mapreduce中调用c语言写的接口.此时就须要把动态链接库so文件分发到hadoop的各个节点上,原来想自己来做这个分发,大概过程就是把so文件放在hdfs上面,然后 ...
- 用shell获得hadoop中mapreduce任务运行结果的状态
在近期的工作中,我需要用脚本来运行mapreduce,并且要判断运行的结果,根据结果来做下一步的动作. 开始我想到shell中获得上一条命令运行结果的方法,即判断"$?"的值 if ...
- hadoop中MapReduce多种join实现实例分析
转载自:http://zengzhaozheng.blog.51cto.com/8219051/1392961 1.在Reudce端进行连接. 在Reudce端进行连接是MapReduce框架进行表之 ...
- logback中配置的日志文件的生成地址
配置文件如下 <?xml version="1.0" encoding="UTF-8"?> <configuration debug=&quo ...
- springboot 项目中控制台打印日志以及每天生成日志文件
1.控制台打印sql语句 只要在application.properties 中加入<configuration scan="true" scanPeriod=" ...
- 使用IDEA远程向伪分布式搭建的Hadoop提交MapReduce作业
环境 VirtualBox 6.1 IntelliJ IDEA 2020.1.1 Ubuntu-18.04.4-live-server-amd64 jdk-8u251-linux-x64 hadoop ...
- hadoop中mapreduce的mapper抽象类和reduce抽象类
mapreduce过程key 和value分别存什么值 https://blog.csdn.net/csdnliuxin123524/article/details/80191199 Mapper抽象 ...
随机推荐
- umich cv-5-2 神经网络训练2
这节课中介绍了训练神经网络的第二部分,包括学习率曲线,超参数优化,模型集成,迁移学习 训练神经网络2 学习率曲线 超参数优化 模型集成 迁移学习 学习率曲线 在训练神经网络时,一个常见的思路就是刚开始 ...
- k8s集群证书过期,重新生成证书
Kubernetes集群证书过期后,使用kubeadm重新颁发证书 默认情况下部署kubernetes集群的证书一年内便过期,如果不及时升级证书导致证书过期,Kubernetes控制节点便会不可用,所 ...
- 美团面试:Redis 除了缓存还能做什么?可以做消息队列吗?
这是一道面试中常见的 Redis 基础面试题,主要考察求职者对于 Redis 应用场景的了解. 即使不准备面试也建议看看,实际开发中也能够用到. 内容概览: Redis 除了做缓存,还能做什么? 分布 ...
- 前后端都用得上的 Nginx 日常使用经验
前言 nginx 是一个高性能的开源反向代理服务器和 web 服务器,一般用来搭建静态资源服务器.负载均衡器.反向代理,本文将分享其在 Windows/docker 中的使用,使用 nssm 部署成服 ...
- lora训练之偷师
自stable diffusion开源之后AIGC绘画方向定制化百花齐放百家争鸣.而c站 https://civitai.com/ 也聚集了全球爱好者的各种微调训练模型分享. 其中以lora为首,应用 ...
- clipboard vue 一键复制
一键复制失败 首先 下载clipboard插件 npm install clipboard --save 在需要的组件里引入 也可以全局引入 import Clipboard from 'clipb ...
- UIPath之Excel操作
你的选择是做或不做,但不做就永远不会有机会. 一. UIPath操作Excel的两组方法 1. App Integration > Excel 特点: 对Excel里的操作必须包含在Exec ...
- ASP.NET Core Web API设置响应输出的Json数据格式的两种方式
前言 在ASP.NET Core Web API中设置响应输出Json数据格式有两种方式,可以通过添加System.Text.Json或Newtonsoft.JsonJSON序列化和反序列化库在应用程 ...
- 数据库系列:MySQL不同操作分别用什么锁?
数据库系列:MySQL慢查询分析和性能优化 数据库系列:MySQL索引优化总结(综合版) 数据库系列:高并发下的数据字段变更 数据库系列:覆盖索引和规避回表 数据库系列:数据库高可用及无损扩容 数据库 ...
- C++中数字与字符串之间的转换(转载自http://www.cnblogs.com/luxiaoxun/)
C++中数字与字符串之间的转换 1.字符串数字之间的转换(1)string --> char * string str("OK"); char * p = str ...