spark科普
普Spark,Spark是什么,如何使用Spark(1)转自:http://www.aboutyun.com/thread-6849-1-1.html
阅读本文章可以带着下面问题:
1.Spark基于什么算法的分布式计算(很简单)
2.Spark与MapReduce不同在什么地方
3.Spark为什么比Hadoop灵活
4.Spark局限是什么
5.什么情况下适合使用Spark
科普Spark,Spark核心是什么,如何使用Spark(2)转自:http://www.aboutyun.com/thread-6850-1-1.html
本篇文章很重要,也是spark为什么是Spark原因:
1.Spark的核心是什么?
2.RDD在内存不足时,是怎么处理的?
3.如何创建RDD,有几种方式
4.Spark编程支持几种语言
5.是否能够写出一个Driver程序
什么是Spark
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。其架构如下图所示:
<ignore_js_op>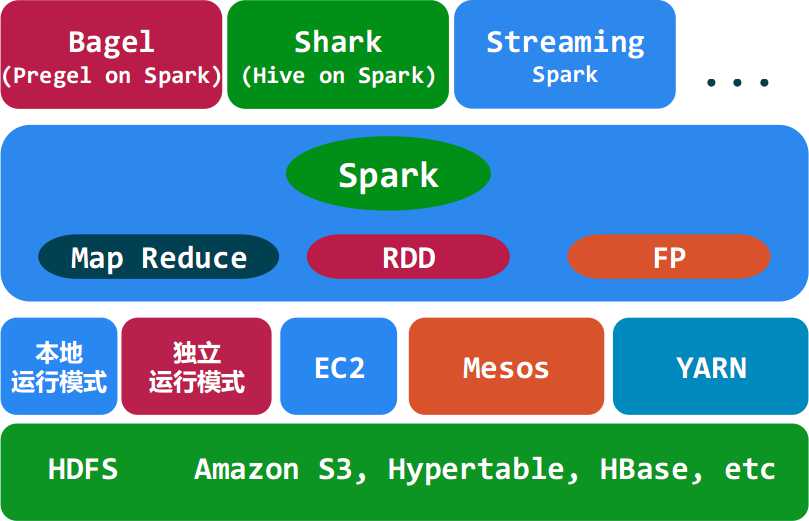
Spark与Hadoop的对比
- Spark的中间数据放到内存中,对于迭代运算效率更高。
Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的抽象概念。
- Spark比Hadoop更通用
Spark提供的数据集操作类型有很多种,不像Hadoop只提供了Map和Reduce两种操作。比如map, filter, flatMap, sample, groupByKey, reduceByKey, union, join, cogroup, mapValues, sort,partionBy等多种操作类型,Spark把这些操作称为Transformations。同时还提供Count, collect, reduce, lookup, save等多种actions操作。
这些多种多样的数据集操作类型,给给开发上层应用的用户提供了方便。各个处理节点之间的通信模型不再像Hadoop那样就是唯一的Data Shuffle一种模式。用户可以命名,物化,控制中间结果的存储、分区等。可以说编程模型比Hadoop更灵活。
不过由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合。
- 容错性。
在分布式数据集计算时通过checkpoint来实现容错,而checkpoint有两种方式,一个是checkpoint data,一个是logging the updates。用户可以控制采用哪种方式来实现容错。
- 可用性。
Spark通过提供丰富的Scala, Java,Python API及交互式Shell来提高可用性。
Spark与Hadoop的结合
Spark可以直接对HDFS进行数据的读写,同样支持Spark on YARN。Spark可以与MapReduce运行于同集群中,共享存储资源与计算,数据仓库Shark实现上借用Hive,几乎与Hive完全兼容。
Spark的适用场景
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小(大数据库架构中这是是否考虑使用Spark的重要因素)
由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合。
总的来说Spark的适用面比较广泛且比较通用。
运行模式
本地模式
Standalone模式
Mesoes模式
yarn模式
Spark生态系统
Shark ( Hive on Spark): Shark基本上就是在Spark的框架基础上提供和Hive一样的H iveQL命令接口,为了最大程度的保持和Hive的兼容性,Shark使用了Hive的API来实现query Parsing和 Logic Plan generation,最后的PhysicalPlan execution阶段用Spark代替Hadoop MapReduce。通过配置Shark参数,Shark可以自动在内存中缓存特定的RDD,实现数据重用,进而加快特定数据集的检索。同时,Shark通过UDF用户自定义函数实现特定的数据分析学习算法,使得SQL数据查询和运算分析能结合在一起,最大化RDD的重复使用。
Spark streaming: 构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片断(几秒),以类似batch批量处理的方式来处理这小部分数据。Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+)可以用于实时计算,另一方面相比基于Record的其它处理框架(如Storm),RDD数据集更容易做高效的容错处理。此外小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法。方便了一些需要历史数据和实时数据联合分析的特定应用场合。
Bagel: Pregel on Spark,可以用Spark进行图计算,这是个非常有用的小项目。Bagel自带了一个例子,实现了Google的PageRank算法。
下一篇:问题:
1.Spark的核心是什么?
2.RDD在内存不足时,是怎么处理的?
3.如何创建RDD,有几种方式
4.Spark编程支持几种语言
5.是否能够写出一个Driver程序
spark科普的更多相关文章
- 科普Spark,Spark核心是什么,如何使用Spark(1)
科普Spark,Spark是什么,如何使用Spark(1)转自:http://www.aboutyun.com/thread-6849-1-1.html 阅读本文章可以带着下面问题:1.Spark基于 ...
- 【转】科普Spark,Spark是什么,如何使用Spark
本博文是转自如下链接,为了方便自己查阅学习和他人交流.感谢原博主的提供! http://www.aboutyun.com/thread-6849-1-1.html http://www.aboutyu ...
- 科普Spark,Spark是什么,如何使用Spark
科普Spark,Spark是什么,如何使用Spark 1.Spark基于什么算法的分布式计算(很简单) 2.Spark与MapReduce不同在什么地方 3.Spark为什么比Hadoop灵活 4.S ...
- 【科普杂谈】一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它比作一个厨房所以需要的各种工具.锅碗瓢盆,各有各的用处,互相之间又有重合.你可 ...
- Apache Spark是什么?
简单地说, Spark是发源于美国加州大学伯克利分校AMPLab的大数据分析平台,它立足于内存计算,从多迭代批量处理出发,兼顾数据仓库. 流处理和图计算等多种计算范式,是大数据系统领域的全栈计算平台. ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- 大数据技术生态圈形象比喻(Hadoop、Hive、Spark 关系)
[摘要] 知乎上一篇很不错的科普文章,介绍大数据技术生态圈(Hadoop.Hive.Spark )的关系. 链接地址:https://www.zhihu.com/question/27974418 [ ...
- spark work目录处理 And HDFS空间都去哪了?
1.说在前面 过完今天就放假回家了(挺高兴),于是提前检查了下个服务集群的状况,一切良好.正在我想着回家的时候突然发现手机上一连串的告警,spark任务执行失败,spark空间不足.我的心突然颤抖了一 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
随机推荐
- Prim's Algorithm & Kruskal's algorithm
1. Problem These two algorithm are all used to find a minimum spanning tree for a weighted undirecte ...
- VS团队资源管理器(VS自带git)使用说明_使用VS自带git推送到远程存储库
使用git存储库是相当好的习惯,每次码完代码就推送到远程存储库,万一不小心把本地代码搞废了,或者硬盘坏了,或者中了勒索病毒,本地代码丢失了还能从服务器上下载.我曾经就中了一次勒索病毒,本地电脑上的所有 ...
- 分离链表法散列ADT
分离链表法解决冲突的散列表ADT实现 数据结构定义如下: struct ListNode; typedef struct ListNode *Position; struct HashTbl; typ ...
- 蜗牛慢慢爬 LeetCode 10. Regular Expression Matching [Difficulty: Hard]
题目 Implement regular expression matching with support for '.' and '*'. '.' Matches any single charac ...
- CMD命令去导出文件下的文件名称到EXCEL
dir C:\Users\caire\Pictures\壁纸/b>E:\temp.xls
- 深入探索.NET内部了解CLR如何创建运行时对象
前言 SystemDomain, SharedDomain, and DefaultDomain. 对象布局和内存细节. 方法表布局. 方法分派(Method dispatching). 因为公共语言 ...
- 怎样使用ADO中的UpdateBatch方法(200分)
诸位: 我在使用ADO组件(ADOQuery.ADODataSet)的BatchUpdate模式时,系统竟不认识UpdateBatch.CancelBatch方法.这是怎么回事?我的运行环境是Win2 ...
- Linux命令01
Linux简介及Ubuntu安装 Linux,免费开源,多用户多任务系统.基于Linux有多个版本的衍生.RedHat.Ubuntu.Debian 安装VMware或VirtualBox虚拟机.具体安 ...
- JAXB java类与xml互转
JAXB(Java Architecture for XML Binding) 是一个业界的标准,是一项可以根据XML Schema产生Java类的技术.该过程中,JAXB也提供了将XML实例文档反向 ...
- KMP之Z-function (扩展kmp)
http://codeforces.com/blog/entry/3107 // s[0, ..., n-1], z[0] = 0// z[i] is the length of the longes ...