HBASE的读写以及client API
一:读写思想
1.系统表
hbase:namespace
存储hbase中所有的namespace的信息
hbase:meta
rowkey:hbase中所有表的region的名称
column:regioninfo:region的名称,region的范围
server:该region在哪台regionserver上
2.读写流程
tbname,rowkey -> region -> regionserver -> store -> storefile
但是这些都是加载过meta表之后,然后meta表如何寻找?
3.读的流程
-》根据表名和rowkey找到对应的region
-》zookeeper中存储了meta表的region信息
-》从meta表中获取相应的region的信息
-》找到对应的regionserver
-》查找对应的region
-》读memstore
-》storefile
4.写的流程
-》根据表名和rowkey找到对应的region
-》zookeeper中存储了meta表的region信息
-》从meta表中获取相应的region的信息
-》找到对应的regionserver
-》正常情况
-》WAL(write ahead log预写日志),一个regionserver维护一个hlog
-》memstore (达到一定大小,flush到磁盘)
-》当多个storefile达到一定大小以后,会进行compact,合并成一个storefile
-》当单个storefile达到一定大小以后,会进行split操作,等分割region
5.注意点
关于版本的合并和删除是在compact阶段完成的。hbase只负责数据的增加存储
hmaster短暂的不参与实际的读写
二:HBase Client API 的书写
1.添加依赖

2.添加配置文件
core-site.xml
hdfs-site.xml
hbase-site.xml
log4j.properties
regionservers
3.get的书写

4.put的书写

5.delete的书写

注意全部删除:

6.scan的书写
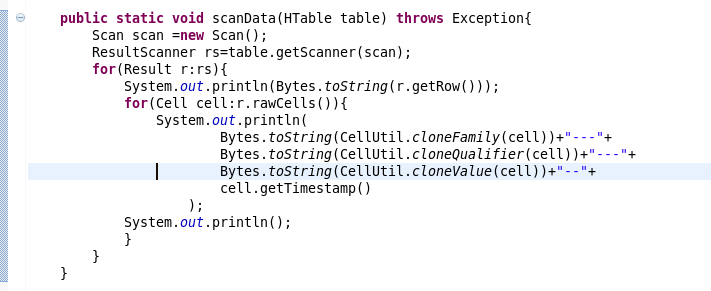
7.过滤条件的scan的书写
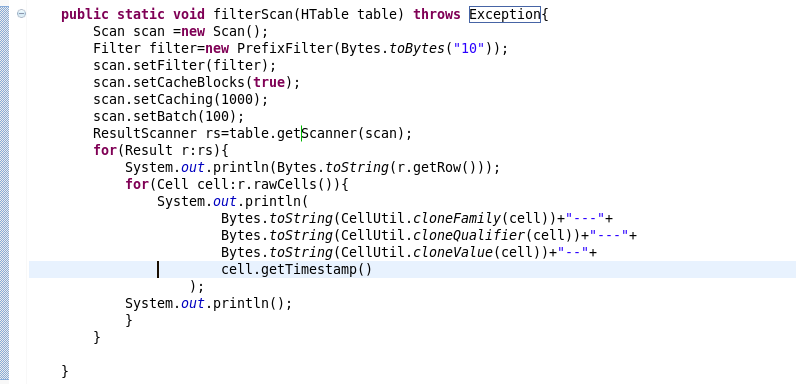
三:复制源代码
package com.beifeng.bigdat; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.util.Bytes; public class HbaseClientTest {
public static HTable getTable(String name) throws Exception{
Configuration conf=HBaseConfiguration.create();
HTable table=new HTable(conf,name);
return table; }
public static void getData(HTable table) throws Exception{
Get get=new Get(Bytes.toBytes("103"));
get.addFamily(Bytes.toBytes("info"));
Result rs=table.get(get);
for(Cell cell:rs.rawCells()){
System.out.println(
Bytes.toString(CellUtil.cloneFamily(cell))+"--"+
Bytes.toString(CellUtil.cloneQualifier(cell))+"---"+
Bytes.toString(CellUtil.cloneValue(cell))+"----"+
cell.getTimestamp()
);
System.out.println("----------------------------------------------");
}
} public static void putData(HTable table) throws Exception{
Put put=new Put(Bytes.toBytes("103"));
put.add(Bytes.toBytes("info"),
Bytes.toBytes("name"),
Bytes.toBytes("zhaoliu"));
table.put(put);
getData(table);
} public static void deleteData(HTable table) throws Exception{
Delete delete =new Delete(Bytes.toBytes("103"));
delete.deleteColumns(Bytes.toBytes("info"), Bytes.toBytes("name"));
table.delete(delete);
getData(table);
} public static void scanData(HTable table) throws Exception{
Scan scan =new Scan();
ResultScanner rs=table.getScanner(scan);
for(Result r:rs){
System.out.println(Bytes.toString(r.getRow()));
for(Cell cell:r.rawCells()){
System.out.println(
Bytes.toString(CellUtil.cloneFamily(cell))+"---"+
Bytes.toString(CellUtil.cloneQualifier(cell))+"---"+
Bytes.toString(CellUtil.cloneValue(cell))+"--"+
cell.getTimestamp()
);
System.out.println();
}
}
} public static void filterScan(HTable table) throws Exception{
Scan scan =new Scan();
Filter filter=new PrefixFilter(Bytes.toBytes("10"));
scan.setFilter(filter);
scan.setCacheBlocks(true);
scan.setCaching(1000);
scan.setBatch(100);
ResultScanner rs=table.getScanner(scan);
for(Result r:rs){
System.out.println(Bytes.toString(r.getRow()));
for(Cell cell:r.rawCells()){
System.out.println(
Bytes.toString(CellUtil.cloneFamily(cell))+"---"+
Bytes.toString(CellUtil.cloneQualifier(cell))+"---"+
Bytes.toString(CellUtil.cloneValue(cell))+"--"+
cell.getTimestamp()
);
System.out.println();
}
} } public static void main(String[] args) throws Exception {
HTable table=getTable("nstest1:tb1");
//getData(table);
//putData(table);
//deleteData(table);
//scanData(table);
filterScan(table);
} }
HBASE的读写以及client API的更多相关文章
- 073 HBASE的读写以及client API
一:读写思想 1.系统表 hbase:namespace 存储hbase中所有的namespace的信息 hbase:meta rowkey:hbase中所有表的region的名称 column:re ...
- HBase 二次开发 java api和demo
1. 试用thrift python/java以及hbase client api.结论例如以下: 1.1 thrift的安装和公布繁琐.可能会遇到未知的错误,且hbase.thrift的版本 ...
- hbase的读写过程
hbase的读写过程: hbase的架构: Hbase真实数据hbase真实数据存储在hdfs上,通过配置文件的hbase.rootdir属性可知,文件在/user/hbase/下hdfs dfs - ...
- Hbase的读写流程
HBase读写流程 1.HBase读数据流程 HRegionServer保存着meta表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在 ...
- HBase 数据读写流程
HBase 数据读写流程 2016-10-18 杜亦舒 读数据 HBase的表是按行拆分为一个个 region 块儿,这些块儿被放置在各个 regionserver 中 假设现在想在用户表中获取 ro ...
- ecshop /api/client/api.php、/api/client/includes/lib_api.php SQL Injection Vul
catalog . 漏洞描述 . 漏洞触发条件 . 漏洞影响范围 . 漏洞代码分析 . 防御方法 . 攻防思考 1. 漏洞描述 ECShop存在一个盲注漏洞,问题存在于/api/client/api. ...
- Memcached Java Client API详解
针对Memcached官方网站提供的java_memcached-release_2.0.1版本进行阅读分析,Memcached Java客户端lib库主要提供的调用类是SockIOPool和MemC ...
- Jersey(1.19.1) - Client API, Uniform Interface Constraint
The Jersey client API is a high-level Java based API for interoperating with RESTful Web services. I ...
- Jersey(1.19.1) - Client API, Ease of use and reusing JAX-RS artifacts
Since a resource is represented as a Java type it makes it easy to configure, pass around and inject ...
随机推荐
- CodeForces 433C Ryouko's Memory Note-暴力
Ryouko's Memory Note Time Limit:1000MS Memory Limit:262 ...
- 转:EasyHook远程代码注入
EasyHook远程代码注入 最近一段时间由于使用MinHook的API挂钩不稳定,经常因为挂钩地址错误而导致宿主进程崩溃.听同事介绍了一款智能强大的挂钩引擎EasyHook.它比微软的detours ...
- ognl el表达式 property
<s:iterator value="list" status="statu" var="alarminfo"> <tr& ...
- 手机开发必备技巧:javascript及CSS功能代码分享
1. viewport: 也就是可视区域.对于桌面浏览器,我们都很清楚viewport是什么,就是出去了所有工具栏.状态栏.滚动条等等之后用于看网页的区域,这是真正有效的区域.由于移动设备屏幕宽度不同 ...
- SQLyog 配置SQL Assitant
在上一篇博文“MySQL配置SQL Assistant提示”中,我介绍了配置SQL Assitant自带的SQL Editor连接MySQL数据库的配置,但是试用两天后发现,SQL Editor不支持 ...
- SQL SERVER事务处理
SQL SERVER事务处理 一.事务定义: 事务是单个的工作单元.如果某一事务成功,则在该事务中进行的所有数据更改均会提交,成为数据库中的永久组成部分. 如果事务遇到错误且必须取消或回滚,则所有 ...
- openstack-L版安装
参照官方install document: http://docs.openstack.org/liberty/install-guide-rdo/ 实验环境:centos7.2 桥接: 192.16 ...
- 诅咒JavaScript之----ArcGIS JavaScript 点聚合 ClusterLayer
对一个之前一直做winForm的 菜鸟来说,突然接触这么神奇的语言,基本上每天都会诅咒一下这门神奇的语言. 最近做了一个小网站,底图用的是天地图的服务,用ArcGIS JavaScript提供的一些G ...
- Bloomberg SEP 12.x 迁移小记
备份 个文件: D:\Program Files\Symantec\Symantec Endpoint Protection Manager\Server Private Key Backup ...
- Ubuntu 启动停止脚本
/etc/init.d 目录下的开机启动脚本 1. more redis_8010 #/bin/sh #Configurations injected by install_server below. ...