Python项目--Scrapy框架(一)
环境
win8, python3.7, pycharm
正文
1.Scrapy框架的安装
在cmd命令行窗口执行:
pip install Scrapy
即可完成Scrapy框架的安装
2. 创建Scrapy项目
在cmd命令行窗口下切换到想要的目录下, 我这里是C:\Users\Administrator\PycharmProjects\untitled\Tests\Scrapy

执行下面代码, 即可在当前的"Scrapy"目录下生成JianShu项目文件夹.
scrapy startproject JianShu
文件夹结构如下:
items.py: 定义要爬取的项目
middlewares.py: 定义爬取时的中间介质
pipelines.py: 定义数据管道
settings.py: 配置文件
scrapy.cfg: Scrapy部署时的配置文件
3. 创建JianShuSpider
在cmd命令行依次执行以下代码, 即可在"JianShu/spiders"目录下创建JianShuSpider.py文件
cd JianShu
scrapy genspider JianShuSpider JianShuSpider.toscrape.com
4. 定义要爬取的项目
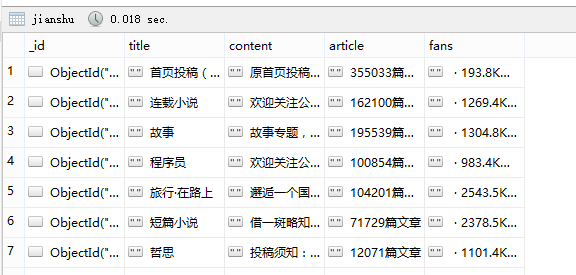
在items.py中确定要爬取的信息: 简书热门专题中的主题, 内容, 文章数, 粉丝数这四个信息
import scrapy
from scrapy.item import Item, Field class JianshuItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = Field() #主题
content = Field() #内容
article = Field() #文章
fans = Field() #粉丝
5. 编写爬虫主程序
简书热门专题采用异步加载, 在NetWork中选择XHR来确定异步加载的url: https://www.jianshu.com/recommendations/collections?page=(1,2,3,4.....)&order_by=hot
在JianShuSpider.py中编写主程序:
import scrapy
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
from JianShu.items import JianshuItem
from scrapy.http import Request
class JianShu(CrawlSpider):
name = 'JianShu'
allowed_domains = ['JianShuSpider.toscrape.com']
start_urls = ['https://www.jianshu.com/recommendations/collections?page=1&order_by=hot']
def parse(self, response):
item = JianshuItem()
#对源码进行初始化
selector = Selector(response)
#采用xpath进行解析
infos = selector.xpath('//div[@class="collection-wrap"]')
for info in infos:
title = info.xpath('a[1]/h4/text()').extract()[0]
content = info.xpath('a[1]/p/text()').extract()
article = info.xpath('div/a/text()').extract()[0]
fans = info.xpath('div/text()').extract()[0]
#加入判断, 如果content存在则返回content[0], 否则返回''
if content:
content = content[0]
else:
content = ''
item['title'] = title
item['content'] = content
item['article'] = article
item['fans'] = fans
yield item
#列表生成式, 生成多个url
urls = ['https://www.jianshu.com/recommendations/collections?page={0}&order_by=hot'.format(str(page)) for page in range(2,37)]
for url in urls:
yield Request(url,callback=self.parse)
6. 保存到MongoDB
利用pipelines数据管道将其存储至MongoDB, 在pipelines.py编写:
import pymongo class JianshuPipeline(object):
def __init__(self):
'''连接Mongodb'''
client = pymongo.MongoClient(host='localhost')
db = client['test']
jianshu = db["jianshu"]
self.post = jianshu
def process_item(self, item, spider):
'''写入Mongodb'''
info = dict(item)
self.post.insert(info)
return item
7. setting配置
BOT_NAME = 'JianShu'
SPIDER_MODULES = ['JianShu.spiders']
NEWSPIDER_MODULE = 'JianShu.spiders'
#从网站请求头复制粘贴User-Agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
ROBOTSTXT_OBEY = True
#设置等待时间5秒
DOWNLOAD_DELAY = 5
#配置项目管道
ITEM_PIPELINES = {
'JianShu.pipelines.JianshuPipeline': 300,
}
8. 新建main.py文件
在JianShu文件目录下新建main.py文件, 编辑如下代码:
from scrapy import cmdline
cmdline.execute('scrapy crawl JianShu'.split())
9. 运行main.py文件
在运行之前, 需确保mongodb服务已经启动, 执行结果如下:
Python项目--Scrapy框架(一)的更多相关文章
- Python项目--Scrapy框架(二)
本文主要是利用scrapy框架爬取果壳问答中热门问答, 精彩问答的相关信息 环境 win8, python3.7, pycharm 正文 1. 创建scrapy项目文件 在cmd命令行中任意目录下执行 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
随机推荐
- 自定义pip 包开发简单说明
文档主要来自官方文档,主要是为了测试学习 创建pip 包项目 项目结构 ├── LICENSE ├── README.md ├── dalongrong_example_pkg │ └── __ini ...
- grep init 与 grep [i]nit
看grep的知识点的时候,在XXX博客里看到一个这样的例子,一直在纠结,纠结,init与[i]nit 匹配到的东西不应该时一样的嘛,为什么一个匹配得出来,一个不行.后来在群里问了某位大哥,耐心的讲解, ...
- php 字符串固定长度,不够补充其他字符串
<?php $input = '456'; $var= str_pad($input,5,10,STR_PAD_LEFT); w3school手冊:http://www.w3school.com ...
- ThreadLocal的学习
一 用法ThreadLocal用于保存某个线程共享变量:对于同一个static ThreadLocal,不同线程只能从中get,set,remove自己的变量,而不会影响其他线程的变量.1.Threa ...
- DokuWiki 命名空间管理
为了更好的组织结构,Dokuwiki提供了命名空间这个功能,那怎么管理命名空间的,其实可以安装插件去管理 Add New Page Plugin:新建界面 https://www.dokuwiki.o ...
- PAT 乙级 1091 N-自守数 (15 分)
1091 N-自守数 (15 分) 如果某个数 K 的平方乘以 N 以后,结果的末尾几位数等于 K,那么就称这个数为“N-自守数”.例如 3×922=25392,而 25392 的末尾两位正好是 ...
- 使用Tensorflow操作MNIST数据
MNIST是一个非常有名的手写体数字识别数据集,在很多资料中,这个数据集都会被用作深度学习的入门样例.而TensorFlow的封装让使用MNIST数据集变得更加方便.MNIST数据集是NIST数据集的 ...
- SQLSERVER创建该存储过程时不会出错,但是执行存储过程时报错
创建该存储过程时,不会出错,但是执行存储过程时,会报出下面这样的错误 这是因为在存储过程创建时,它先做语法检查,如果通过了语法检查,它会尝试解析它包含的对象名,如果存在也会解析该对象引用的对象是否存在 ...
- Kafka介绍与消息队列
消息队列的好处: 消息队列(Message Queue) 消息: 网络中的两台计算机或者两个通讯设备之间传递的数据.例如说:文本.音乐.视频等内容. 队列:一种特殊的线性表(数据元素首尾相接),特殊之 ...
- winCVS 使用的一个小要点
对于版本管理软件CVS,可以在Linux中使用命令来管理. 但是 在windows 界面下,也可以使用 winCVS 工具来管理. 现在 讲一下 如何 在 winCVS 登陆 CVS 帐号 和 密码: ...