Spark广播变量和累加器
一.广播变量图解

二.代码
val conf = new SparkConf()
conf.setMaster("local").setAppName("brocast")
val sc = new SparkContext(conf)
val list = List("hello xasxt")
val broadCast = sc.broadcast(list)
val lineRDD = sc.textFile("./words.txt")
lineRDD.filter { x => broadCast.value.contains(x) }.foreach { println}
sc.stop()
三.注意事项
1.不能将一个RDD使用广播变量广播出去,因为RDD是不存储数据的【弹性分布式数据集】。可以将RDD的结果广播出去【collect,数据不能太多】。
2.广播变量只能在Driver端定义,不能在Executor端定义。
3.在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
四.累加器图解
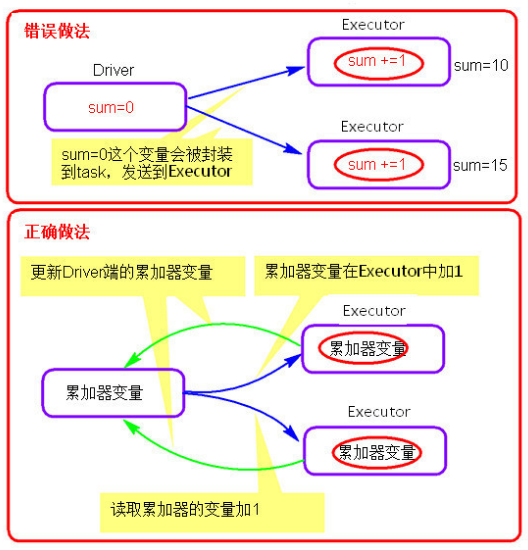
五.代码
val conf = new SparkConf()
conf.setMaster("local").setAppName("accumulator")
val sc = new SparkContext(conf)
val accumulator = sc.accumulator(0)
sc.textFile("./words.txt").foreach { x =>{accumulator.add(1)}}
println(accumulator.value)
sc.stop()
六.注意事项
1.累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Excutor端更新。
Spark广播变量和累加器的更多相关文章
- Spark 广播变量和累加器
Spark 的一个核心功能是创建两种特殊类型的变量:广播变量和累加器 广播变量(groadcast varible)为只读变量,它有运行SparkContext的驱动程序创建后发送给参与计算的节点.对 ...
- 【Spark-core学习之七】 Spark广播变量、累加器
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- Spark 广播变量 和 累加器
1. 广播变量 理解图 使用示例 # word.txt hello scala hello python hello java hello go hello julia hello C++ hello ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- Spark(三)RDD与广播变量、累加器
一.RDD的概述 1.1 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可 ...
- Spark——DataFrames,RDD,DataSets、广播变量与累加器
Spark--DataFrames,RDD,DataSets 一.弹性数据集(RDD) 创建RDD 1.1RDD的宽依赖和窄依赖 二.DataFrames 三.DataSets 四.什么时候使用Dat ...
- Spark(八)【广播变量和累加器】
目录 一. 广播变量 使用 二. 累加器 使用 使用场景 自定义累加器 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的 ...
- 广播变量、累加器、collect
广播变量.累加器.collect spark集群由两类集群构成:一个驱动程序,多个执行程序. 1.广播变量 broadcast 广播变量为只读变量,它由运行sparkContext的驱动程序创建后发送 ...
- spark 广播变量
Spark广播变量 使用广播变量来优化,广播变量的原理是: 在每一个Executor中保存一份全局变量,task在执行的时候需要使用和这一份变量就可以,极大的减少了Executor的内存开销. Exe ...
随机推荐
- 【MyEclipse】安装svn插件
svn插件包下载:http://subclipse.tigris.org/servlets/ProjectDocumentList?folderID=2240 重启myeclipse 看import就 ...
- 解决——》java.lang.IllegalArgumentException: Body parameter 0 was null
1.操作2.现象(错误信息)3.原因错误代码:4.解决1)方案一:@RequestBody(required=false)2)方案二:传参数时限制authSession不能为空ody paramete ...
- LeetCode 1146. Snapshot Array
原题链接在这里:https://leetcode.com/problems/snapshot-array/ 题目: Implement a SnapshotArray that supports th ...
- graalvm native image 试用
graalvm 提供的native 模式,可以加速应用的启动,不同可以让应用不再依赖jvm 运行时环境,但是 也有一些限制 参考 https://github.com/oracle/graal/blo ...
- university-conda
1.建立环境 conda create -n djx python=3.7 2.激活 conda activate djx 3.退出 conda deactivate 4.查看 conda env l ...
- 从零和使用mxnet实现线性回归
1.线性回归从零实现 from mxnet import ndarray as nd import matplotlib.pyplot as plt import numpy as np import ...
- 「CodeM」排列
传送门 Description 给 \(n\) 个二维点 \((a_i,b_i)\),询问有多少种排列 \(p\)(答案对 \(10^9+7\) 取模)使得执行以下伪代码后留下的点是 \(i\),即最 ...
- Java 并发系列之三:java 内存模型(JMM)
1. 并发编程的挑战 2. 并发编程需要解决的两大问题 3. 线程通信机制 4. 内存模型 5. volatile 6. synchronized 7. CAS 8. 锁的内存语义 9. DCL 双重 ...
- fibnacci数列递归
1,斐波那契数列(Fibonacci sequence),又称黄金分割数列.因数学家列昂纳多·斐波那契(Leonardoda Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”,指的是这 ...
- 「HAOI2015」树上操作(非树剖)
题目链接(luogu) 看到标签::树链剖分,蒟蒻Sy开始发抖,不知所措,但其实,本题只需要一个恶心普通的操作就可以了!! 前提知识:欧拉序 首先我们知道dfs序,就是在dfs过程中,按访问顺序进行编 ...