算法之暴力破解和kmp算法 判断A字符串是否包含B字符串
我们都知道java中有封装好的方法,用来比较A字符串是否包含B字符串
如下代码,contains,用法是 str1.contains(str2), 这个布尔型返回,存在返回true,不存在返回false
还有indexOf,用法和contains一致,返回值是int,存在则返回对应的位置,注意位置从0开始的,不存在返回-1
public class Test {
public static void main(String[] args) {
String source = "abacaabacabacabaabb";
String pattern = "abacab";
System.out.println(source.contains(pattern) ); //true
System.out.println(source.indexOf(pattern) ); //
}
}
这两个方法的具体实现,是在java.lang包中,最终类String下
public boolean contains(CharSequence s) {
return indexOf(s.toString()) > -1;
}
contains其实调用了indexOf
public int indexOf(String str) {
return indexOf(str, 0);
}
public int indexOf(String str, int fromIndex) {
return indexOf(value, 0, value.length,
str.value, 0, str.value.length, fromIndex);
}
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
if (fromIndex < 0) {
fromIndex = 0;
}
if (targetCount == 0) {
return fromIndex;
} char first = target[targetOffset];
int max = sourceOffset + (sourceCount - targetCount); for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
if (source[i] != first) {
while (++i <= max && source[i] != first);
} /* Found first character, now look at the rest of v2 */
if (i <= max) {
int j = i + 1;
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++); if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
return -1;
}
如果你没有去看java中自带的实现,要你自己写方法实现呢
这就涉及到了算法:算法就是你的思路=======
第一步: 先构思一下思路,我要怎么去比较;一般人的思路是:
我拿后者的第一个字符,去看前者中是否含有,如果米有,一定不匹配;
我拿后者的第一个字符,去看前者中是否含有,如果前者中含有,继续查看,第二个字符是否和长串中接下来的一个字符相等
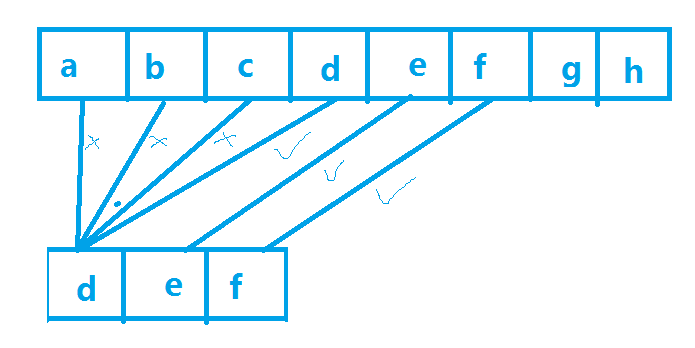
相等,继续向下匹配(如下图一)
不相等,重新用后者的第一个字符再和长字符串接下来一位进行比较
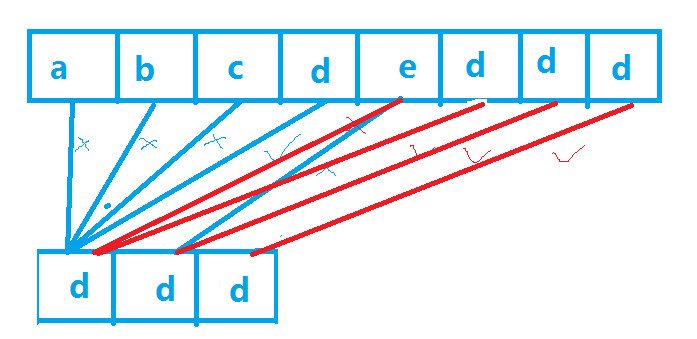
何谓接下来一位呢【假设abcdefgh和ddd,第一次比配到长字符串的第四位相等,第二次和长字符串的第5位开始比较,如下图二】
public class Force {
/**
* 暴力匹配
* 时间复杂度为O(n*m);n为主串长度,m为模式串长度
算法的基本思想:
从主串的起始位置(或指定位置)开始与模式串的第一个字符比较,若相等,则继续逐个比较后续字符;
否则从主串的下一个字符再重新和模式串的字符比较。
依次类推,直到模式串成功匹配,返回主串中第一次出现模式串字符的位置,或者模式串匹配不成功,返回不成功,实际中可将返回值设置为int,不成功返回-1,成功返回0;
* @param source
* @param pattern
* @return
*/
public static String bruteForceStringMatch(String source, String pattern) {
int slen = source.length();
int plen = pattern.length();
char[] s = source.toCharArray();
char[] p = pattern.toCharArray();
int i = 0;
int j = 0;
if (slen < plen)
return "你瞧瞧主串长度小于模式串,怎么可能啊,匹配失败"; // 如果主串长度小于模式串,直接返回-1,匹配失败
else {
while (i < slen && j < plen) {
if (s[i] == p[j]) // 如果i,j位置上的字符匹配成功就继续向后匹配
{
System.out.println(i+ "的值是"+ s[i] );
System.out.println(j + "的值是"+ p[j]);
++i;
++j;
} else {
System.out.println("我是else下的" + i + "的值是"+ s[i] );
System.out.println("我是else下的" + j + "的值是"+ p[j]);
i = i - (j - 1); // i回溯到主串上一次开始匹配下一个位置的地方
j = 0; // j重置,模式串从开始再次进行匹配
}
}
if (j == plen) // 匹配成功
return "位置是"+(i+1 - j);
else
return "匹配失败"; // 匹配失败
}
}
}
查看匹配结果:


这是暴力破解,abcdeddd和ddd,在ddd的第0位和abcdeddd的第3位匹配后,继续比较下一位,发现不匹配了,重新将ddd的第0位和
kmp的思路如下:
KMP算法
KMP算法是D.E.Knuth、V.R.Pratt和J.H.Morris同时发现,所以命名为KMP算法。
此算法可以在O(n+m)的时间数量级上完成串的模式匹配。
主要就是改进了暴力匹配中i回溯的操作,KMP算法中当一趟匹配过程中出现字符比较不等时,
不直接回溯i,而是利用已经得到的“部分匹配”的结果将模式串向右移动(j-next[k])的距离。
import java.util.Arrays;
public class kmp {
/**
* KMP算法
KMP算法是D.E.Knuth、V.R.Pratt和J.H.Morris同时发现,所以命名为KMP算法。
此算法可以在O(n+m)的时间数量级上完成串的模式匹配。
主要就是改进了暴力匹配中i回溯的操作,KMP算法中当一趟匹配过程中出现字符比较不等时,
不直接回溯i,而是利用已经得到的“部分匹配”的结果将模式串向右移动(j-next[k])的距离。
* @param source
* @param pattern
* @return
*/
public static String kmpStringMatch(String source, String pattern)
{
int i = 0;
int j = 0;
char[] s = source.toCharArray();
char[] p = pattern.toCharArray();
int slen = s.length;
int plen = p.length;
int[] next = getNext(p);
while(i < slen && j < plen)
{
if(j == -1 || s[i] == p[j])
{
++i;
++j;
}
else
{
//如果j != -1且当前字符匹配失败,则令i不变,
//j = next[j],即让pattern模式串右移j - next[j]个单位
j = next[j];
}
}
if(j == plen)
return "位置是"+(i+1 - j);
else
return "匹配失败"; // 匹配失败
}
/**
* 关于next[k]数组的计算引出的两种办法,一种是递归,一种对递归优化,第一种对应的就是KMP算法,第二种就是优化的KMP算法。
next函数值仅取决于模式串本身而和主串无关。
有很多讲next函数值计算办法的资料,在此我想用一种直观的比较容易理解的办法来表达。
举个栗子:现在有一个模式串abab
模式串的各个字串 前缀 后缀 最大公共元素长度
a null null 0
ab a b 0
aba a,ab a,ba 1
abab a,ab,aba b,ab,bab 2
* @param p
* @return
*/
private static int[] getNext(char[] p)
{
/**
* 已知next[j] = k, 利用递归的思想求出next[j+1]的值
* 1.如果p[j] = p[k],则next[j+1] = next[k] + 1;
* 2.如果p[j] != p[k],则令k = next[k],如果此时p[j] == p[k],则next[j+1] = k+1
* 如果不相等,则继续递归前缀索引,令k=next[k],继续判断,直至k=-1(即k=next[0])或者p[j]=p[k]为止
*/
int plen = p.length;
int[] next = new int[plen];
System.out.println("next函数值:" + Arrays.toString(next));
int k = -1;
int j = 0;
next[0] = -1; //这里采用-1做标识
while(j < plen -1)
{
if(k == -1 || p[j] == p[k])
{
++k;
++j;
next[j] = k;
}
else
{
k = next[k];
}
}
System.out.println("next函数值:" + Arrays.toString(next));
return next;
}
}
算法之暴力破解和kmp算法 判断A字符串是否包含B字符串的更多相关文章
- 字符串查找算法总结(暴力匹配、KMP 算法、Boyer-Moore 算法和 Sunday 算法)
字符串匹配是字符串的一种基本操作:给定一个长度为 M 的文本和一个长度为 N 的模式串,在文本中找到一个和该模式相符的子字符串,并返回该字字符串在文本中的位置. KMP 算法,全称是 Knuth-Mo ...
- 从暴力匹配到KMP算法
前言 现在有两个字符串:\(s1\)和\(s2\),现在要你输出\(s2\)在\(s1\)当中每一次出现的位置,你会怎么做? 暴力匹配算法 基本思路 用两个指针分别指向当前匹配到的位置,并对当前状态进 ...
- 【功能代码】---3 JS判断字符串是否包含某个字符串
JS判断字符串是否包含某个字符串 var str ="abc"; if(str.indexOf("bc")>-1){ alert('str中包含bc字符串 ...
- mysql判断表里面一个逗号分隔的字符串是否包含单个字符串、查询结果用逗号分隔
1.mysql判断表里面一个逗号分隔的字符串是否包含单个字符串 : FIND_IN_SET select * from tablename where FIND_IN_SET(传的参数,匹配字段) 例 ...
- C/C++判断字符串是否包含某个字符串
C风格 #include <iostream> #include <string> #include <cstring> using namespace std; ...
- 算法进阶面试题01——KMP算法详解、输出含两次原子串的最短串、判断T1是否包含T2子树、Manacher算法详解、使字符串成为最短回文串
1.KMP算法详解与应用 子序列:可以连续可以不连续. 子数组/串:要连续 暴力方法:逐个位置比对. KMP:让前面的,指导后面. 概念建设: d的最长前缀与最长后缀的匹配长度为3.(前缀不能到最后一 ...
- 算法(Java实现)—— KMP算法
KMP算法 应用场景 字符串匹配问题 有一个字符串str1 = " hello hello llo hhello lloh helo" 一个子串str2 = "hello ...
- 【字符串算法3】浅谈KMP算法
[字符串算法1] 字符串Hash(优雅的暴力) [字符串算法2]Manacher算法 [字符串算法3]KMP算法 这里将讲述 [字符串算法3]KMP算法 Part1 理解KMP的精髓和思想 其实KM ...
- 程序员的算法课(11)-KMP算法
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/m0_37609579/article/de ...
随机推荐
- Mac安装7Z以及Mac下查看隐藏文件夹
一:Mac下安装7Z: 1:brew直接安装解压工具 $ brew search 7z 会搜索到: ==> Formulae p7zip 2:$ brew install p7zip ...
- 前端添加视频流rtmp格式
要求:rtmp格式, 在线直播 url地址 效果: 代码:初次打开时间较长, <!DOCTYPE html> <html> <head> <script ty ...
- python 字典dict - python基础入门(15)
前面的课程讲解了字符串str/列表list/元组tuple,还有最后一种比较重要的数据类型也需要介绍介绍,那就是python字典,俗称:dict. python中的字典可与字符串/列表/元组不同,因为 ...
- matplotlib中的imshow()
import matplotlib.pyplot as plt plt.imshow(x,cmap) x表示要显示的图片变量,cmap为颜色图谱,默认为RGB(A)颜色空间,也可以指定,gray是灰度 ...
- markdown转移字符表
本片转的ASCII码,主要针对$,另外我为了不让"&#xxx;"被转移成字符,我在分号";"前加了个空格,复制的时候注意一下 字符 转义 0 空格 @ ...
- 【leetcode算法-简单】27. 移除元素
[题目描述] 给定一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素,返回移除后数组的新长度. 不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空 ...
- javaIO -- InputStream和OutStream
一.简介 InputStream 和 OutputStream 对于字节流的输入和输出是作为协议的存在 所以有必要了解下这两个类提供出来的基本约定,这两个类是抽象类,而且基本上没什么实现,都是依赖于子 ...
- spring 框架的核心总结
最近在学习Java语言,从而也学习了SpringFramework 这个大名鼎鼎的框架.从而做一些的记录. 题外话: 学习过几种不同的语言,后来知道所有的编程语言里所有的概念翻来覆去都是一样的事物,只 ...
- vue中设置全局的css样式
只需在main.js ====import './style.less' main.js =>> import Vue from 'vue' import App from ...
- SAS学习笔记13 SAS数据清洗和加工(续)
查找缺失值 cha[*]和num[*]是建立数组cha和num,但不指定数组中的元素数 自动变量_character_表示数据集中的所有字符型变量 自动变量_numeric_表示数据集中的所有数值型变 ...