scrapy抓取拉勾网职位信息(八)——使用scrapyd对爬虫进行部署
上篇我们实现了分布式爬取,本篇来说下爬虫的部署。
分析:我们上节实现的分布式爬虫,需要把爬虫打包,上传到每个远程主机,然后解压后执行爬虫程序。这样做运行爬虫也可以,只不过如果以后爬虫有修改,需要重新修改好代码后,重新打包上传然后执行(当然你愿意每台登上去后修改代码也行)。本篇我们使用scrapd来进行部署。
使用scrapyd来部署爬虫大体只需要几步:
- 在需要运行爬虫的主机上安装scrapyd,并且启动scrapyd服务
- 使用scrapy-client把项目打包成egg文件,部署到scrapyd服务
- 使用scrapyd提供的网络API来对爬虫进行操作,包括启动爬虫、停止爬虫等操作。
一、安装相关的库
pip install scrapyd (需要运行爬虫的主机都要安装)
pip install scrapyd-client (本机主机安装即可,作用是为了把爬虫项目部署到远程主机的scrapyd去)
二、修改scrapyd配置文件
[root@kongqing /]# whereis scrapyd
scrapyd: /etc/scrapyd /root/.pyenv/shims/scrapyd
[root@kongqing /]# cd /etc/scrapyd
[root@kongqing scrapyd]# ls
scrapyd.conf
[root@kongqing scrapyd]# vim scrapyd.conf bind_address=0.0.0.0 #修改为0.0.0.0可以使用其他任意主机进行连接
三、启动scrapyd,直接命令行输入scrapyd(这样就启动了一个网络的监听,端口默认是6800)

四、使用本机浏览器打开47.98.xx.xx:6800 (前面换成自己安装好scrapyd的远程主机IP地址)
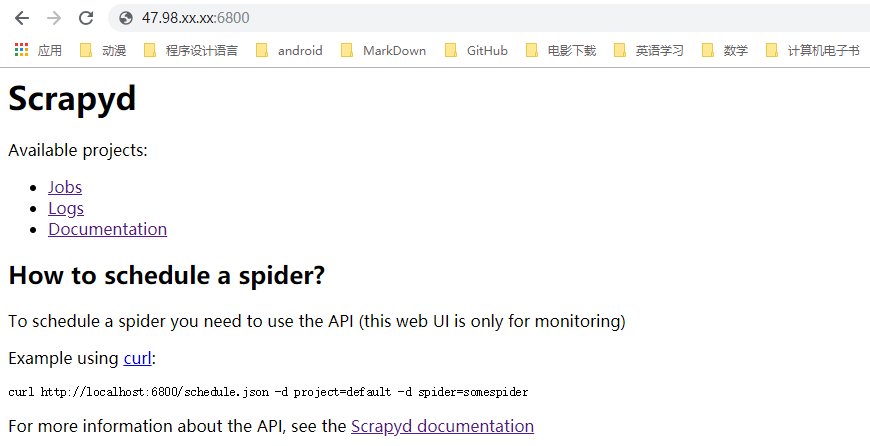
解释一波:
- jobs代表的就是爬虫项目
- logs代表的是日志文件,也就是你爬虫运行时显示的那些信息
- Documentation这个指的scrapyd的文档,教你对爬虫项目进行启停等操作的
当然,目前里面还没有项目,所以jobs、logs里面都是空的。
五、修改本地爬虫文件scrapy.cfg文件(前面解释过,这个文件是用来做爬虫部署用的)
[settings]
default = lagou.settings [deploy]
#url = http://localhost:6800/ #本地的直接能运行,我就不改了
project = lagou [deploy:aliyun] #:后面是别名,自己设置,用来识别部署的是哪台设备,避免弄混
url = http://47.98.xx.xx:6800/ #远程主机的地址及端口
project = lagou
六、使用scrapyd_client将项目部署到远程主机
- 在scrapy.cfg文件所在目录打开cmd命令行,(地址栏输入cmd,或者shift+右键打开)
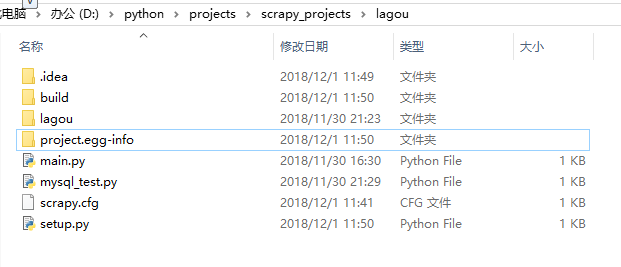
- 执行部署命令scrapyd-deploy aliyun --version 201812010050

解释一波:
- 如果只输入命令scrapyd-deploy就是直接部署本机了,因为本机没有跟别名
- aliyun代表的是我的远程主机,也就是scrapy.cfg文件中的[deploy:aliyun]这部分。建议大家加别名,方便识别管理。
- --version是可选的,代表一个版本,后面的数字我是使用的当前时间,自己可以根据需要设置。默认是时间戳,也就是不使用--version它也会默认给你生成一个版本信息。
- 可以看到,成功执行部署命令后,本地项目目录多了两个文件夹
七、使用scrapyd网络API启停爬虫
打开API文档看一下,我们可以看到有以下这些方法:
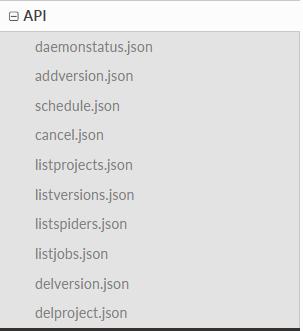
这里只解释两个用法,其他的自己看文档。
shedule.json:运行一个爬虫(会返回一个jobid),文档示例用法如下:
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=somespider
cancel.json:停止一个爬虫(需要有jobid),文档示例用法如下:
$ curl http://localhost:6800/cancel.json -d project=myproject -d job=6487ec79947edab326d6db28a2d86511e8247444
现在我们启动我们自己在远程主机上的爬虫项目。
- 首先执行以下代码:
curl http://47.98.xx.xx:6800/schedule.json -d project=lagou -d spider=lagou_c #修改为自己的远程主机IP,项目名是lagou,spider名字是lagou_c
- 我们用浏览器打开47.98.xx.xx:6800看下jobs,可以看到有一个爬虫在运行了
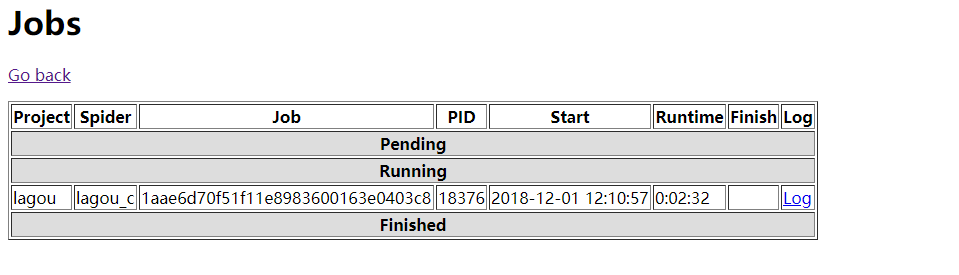
- 注意到那个蓝色的Log了么,爬虫的调试信息都在这里,我们点击就可以看到爬虫运行时的信息了

- 现在我们停止这个爬虫,使用命令
curl http://47.98.xx:xx/cancel.json -d project=lagou -d job=1aae6d70f51f11e8983600163e0403c8 (需要修改为自己的远程主机IP,项目名称,job就是之前运行时候的jobid
- 我们现在再到网页里看一下,显示刚刚那个爬虫已经停止了:
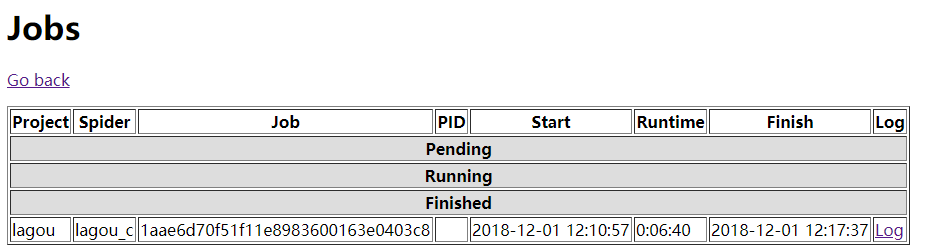
这样我们使用scrapyd就完成了爬虫部署到远程服务器的过程,如果你觉得使用网络API调用的方式不习惯的话,也可以用scrapyd_api来调用,不过需要生成egg文件,地址在这里,有兴趣的可以尝试。
scrapy抓取拉勾网职位信息(八)——使用scrapyd对爬虫进行部署的更多相关文章
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- scrapy抓取拉勾网职位信息(三)——爬虫rules内容编写
在上篇中,分析了拉勾网需要跟进的页面url,本篇开始进行代码编写. 在编写代码前,需要对scrapy的数据流走向有一个大致的认识,如果不是很清楚的话建议先看下:scrapy数据流 本篇目标:让拉勾网爬 ...
- scrapy抓取拉勾网职位信息(二)——拉勾网页面分析
网站结构分析: 四个大标签:首页.公司.校园.言职 我们最终是要得到详情页的信息,但是从首页的很多链接都能进入到一个详情页,我们需要对这些标签一个个分析,分析出哪些链接我们需要跟进. 首先是四个大标签 ...
- scrapy抓取拉勾网职位信息(四)——对字段进行提取
上一篇中已经分析了详情页的url规则,并且对items.py文件进行了编写,定义了我们需要提取的字段,本篇将具体的items字段提取出来 这里主要是涉及到选择器的一些用法,如果不是很熟,可以参考:sc ...
- scrapy抓取拉勾网职位信息(七)——数据存储(MongoDB,Mysql,本地CSV)
上一篇完成了随机UA和随机代理的设置,让爬虫能更稳定的运行,本篇将爬取好的数据进行存储,包括本地文件,关系型数据库(以Mysql为例),非关系型数据库(以MongoDB为例). 实际上我们在编写爬虫r ...
- scrapy抓取拉勾网职位信息(七)——实现分布式
上篇我们实现了数据的存储,包括把数据存储到MongoDB,Mysql以及本地文件,本篇说下分布式. 我们目前实现的是一个单机爬虫,也就是只在一个机器上运行,想象一下,如果同时有多台机器同时运行这个爬虫 ...
- scrapy抓取拉勾网职位信息(六)——反爬应对(随机UA,随机代理)
上篇已经对数据进行了清洗,本篇对反爬虫做一些应对措施,主要包括随机UserAgent.随机代理. 一.随机UA 分析:构建随机UA可以采用以下两种方法 我们可以选择很多UserAgent,形成一个列表 ...
- scrapy抓取拉勾网职位信息(五)——代码优化
上一篇我们已经让代码跑起来,各个字段也能在控制台输出,但是以item类字典的形式写的代码过于冗长,且有些字段出现的结果不统一,比如发布日期. 而且后续要把数据存到数据库,目前的字段基本都是string ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
随机推荐
- CSS3实现文本垂直排列
最近的一个项目中要使文字垂直排列,也就是运用了CSS的writing-mode属性. writing-mode最初时ie中支持的一个属性,后来在CSS3中增添了这一新的属性,所以在ie中和其他浏览器中 ...
- Web Api返回值
首先:注明,我还没这么强的功力啦!这是我看的网上的,因为怕博主删除就自己复制了一下 博主的网址是:http://www.cnblogs.com/landeanfen/p/5501487.html 使用 ...
- js 给指定ID赋值
js 给指定ID赋值 <script language="javascript" type="text/javascript"> document. ...
- 实现字符串检索strstr函数、字符串长度strlen函数、字符串拷贝strcpy函数
#include <stdio.h> #include <stdlib.h> #include <string.h> /* _Check_return_ _Ret_ ...
- XML-RPC笔记
1.什么是XML-RPC RPC(Remote Procedure Call)就是相当于提供了一种"远程接口"来供外部系统调用,常用于不同平台.不同架构的系统之间互相调用. XML ...
- PHP代码审计学习
原文:http://paper.tuisec.win/detail/1fa2683bd1ca79c 作者:June 这是一次分享准备.自己还没有总结这个的能力,这次就当个搬运工好了~~ 0x01 工具 ...
- 配置kernel的log buf大小(如果kmsg log被覆盖)
如果在打印kmsg log时发现log被覆盖,log 的buf不够大可以使用默认配置调buf: defconfig CONFIG_LOG_BUF_SHIFT=20 (默认是17 2的17次方) ...
- Linux运维常用的几个命令介绍【转】
Linux运维常用的几个命令介绍 1. 查看系统内核版本 [root@funsion geekxa]# cat /etc/issue CentOS release 6.5 (Final) Kerne ...
- localhost或127.0.0.1或192.168.1.*被转到129129.com上的问题
系统启动里会有个httpd的apache程序在运行,自启禁用掉后.windows下有个apache文件夹,干掉就可以. 个别GHOST XP程序里面会装这种流氓程序.
- 72.Edit Distance---dp
题目链接:https://leetcode.com/problems/edit-distance/description/ 题目大意:找出两个字符串之间的编辑距离(每次变化都只消耗一步). 法一(借鉴 ...