requests+lxml+xpath爬取电影天堂
1.导入相应的包
import requests
from lxml import etree
2.原始ur
url="https://www.dytt8.net/html/gndy/dyzz/list_23_1.html"
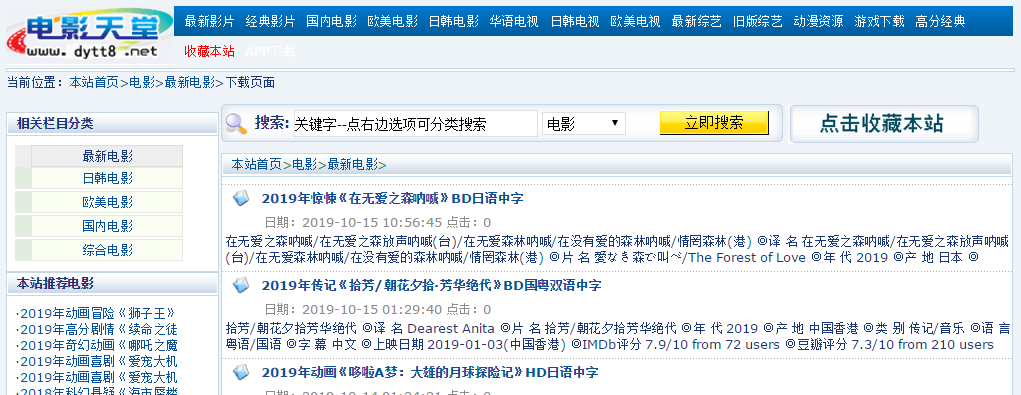
我们要爬取的是最新电影,在该界面中,我们发现,具体的信息存储在每个名字的链接中,因此我们要获取所有电影的链接才能得到电影的信息。同时我们观察url,发现
list_23_1,最后的1是页面位于第几页。右键点击其中一个电影的名字-检查。

我们发现,其部分连接位于具有class="tbspan"的table的<b>中,首先建立一个函数,用来得到所有的链接:
#用于补全url
base_url="https://www.dytt8.net"
def get_domain_urls(url):
response=requests.get(url=url,headers=headers)
text=response.text
html=etree.HTML(text)
#找到具有class="tbspan"的table下的所有a下面的href里面的值
detail_urls=html.xpath("//table[@class='tbspan']//a/@href")
#将url进行补全
detail_urls=map(lambda url:base_url+url,detail_urls)
return detail_urls
我们输出第1页中的所有url结果:
url="https://www.dytt8.net/html/gndy/dyzz/list_23_1.html"
for i in get_domain_urls(url):
print(i)
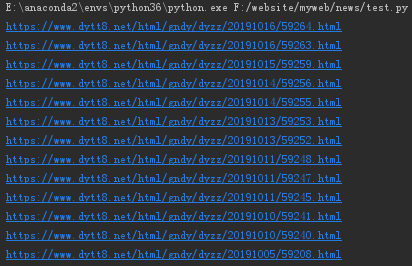
我们随便进入第一个链接:

按下F12,发现这些信息基本上都在div id="Zoom"中,接下来我们就可以对该界面进行解析。

def parse_detail_page(url):
movie={}
response=requests.get(url,headers=headers)
text=response.content.decode("GBK")
html=etree.HTML(text)
zoom=html.xpath("//div[@id='Zoom']")[0]
infos=zoom.xpath("//text()")
def parse_info(info,rule):
return info.replace(rule,"").lstrip()
for k,v in enumerate(infos):
if v.startswith("◎译 名"):
v=parse_info(v,"◎译 名").split("/")[0]
movie["name"]=v
elif v.startswith("◎产 地"):
v=parse_info(v,"◎产 地")
movie["country"]=v
elif v.startswith("◎类 别"):
v=parse_info(v,"◎类 别")
movie["category"]=v
elif v.startswith("◎豆瓣评分"):
v=parse_info(v,"◎豆瓣评分").split("/")[0]
movie["douban"]=v
elif v.startswith("◎导 演"):
v=parse_info(v,"◎导 演")
movie["director"]=v
elif v.startswith("◎主 演"):
v=parse_info(v,"◎主 演")
actors=[v]
for x in range(k+1,len(infos)):
actor=infos[x].strip()
if actor.startswith("◎"):
break
actors.append(actor)
movie["actors"]=actors
elif v.startswith("◎简 介"):
profile=""
for x in range(k+1,len(infos)):
tmp=infos[x].strip()
if tmp.startswith("【下载地址】"):
break
else:
profile=profile+tmp
movie["profile"]=profile
down_url=html.xpath("//td[@bgcolor='#fdfddf']/a/@href")
movie["down_url"]=down_url
return movie
最后将这两个整合进一个爬虫中:
def spider():
domain_url="https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html"
movies=[]
for i in range(1,2):
page=str(i)
url=domain_url.format(page)
detail_urls=get_domain_urls(url)
for detail_url in detail_urls:
movie = parse_detail_page(detail_url)
movies.append(movie)
print(movies)
运行爬虫,得到以下结果(在Json查看器中进行格式化):
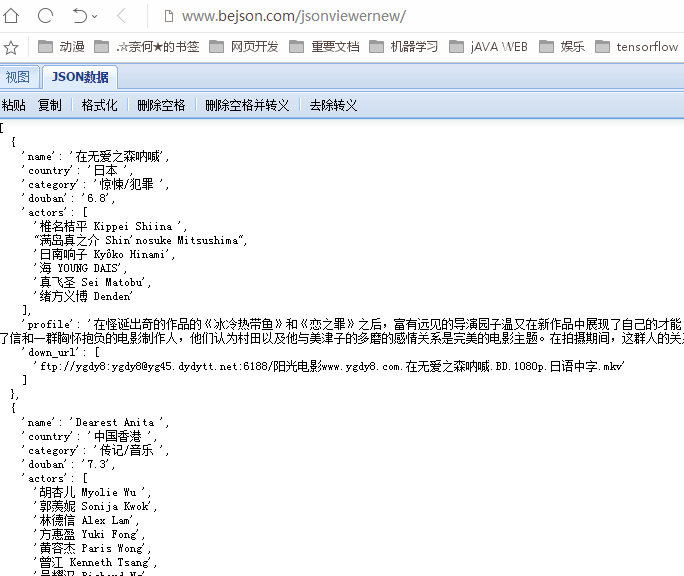
至此,一个简单的电影爬虫就完成了。
requests+lxml+xpath爬取电影天堂的更多相关文章
- requests+lxml+xpath爬取豆瓣电影
(1)lxml解析html from lxml import etree #创建一个html对象 html=stree.HTML(text) result=etree.tostring(html,en ...
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- python利用requests和threading模块,实现多线程爬取电影天堂最新电影信息。
利用爬到的数据,基于Django搭建的一个最新电影信息网站: n1celll.xyz (用的花生壳动态域名解析,服务器在自己的电脑上,纯属自娱自乐哈.) 今天想利用所学知识来爬取电影天堂所有最新电影 ...
- 14.python案例:爬取电影天堂中所有电视剧信息
1.python案例:爬取电影天堂中所有电视剧信息 #!/usr/bin/env python3 # -*- coding: UTF-8 -*- '''======================== ...
- scrapy框架用CrawlSpider类爬取电影天堂.
本文使用CrawlSpider方法爬取电影天堂网站内国内电影分类下的所有电影的名称和下载地址 CrawlSpider其实就是Spider的一个子类. CrawlSpider功能更加强大(链接提取器,规 ...
- Python爬取电影天堂指定电视剧或者电影
1.分析搜索请求 一位高人曾经说过,想爬取数据,要先分析网站 今天我们爬取电影天堂,有好看的美剧我在上面都能找到,算是很全了. 这个网站的广告出奇的多,用过都知道,点一下搜索就会弹出个窗口,伴随着滑稽 ...
- requests结合xpath爬取豆瓣最新上映电影
# -*- coding: utf-8 -*- """ 豆瓣最新上映电影爬取 # ul = etree.tostring(ul, encoding="utf-8 ...
- requests+BeautifulSoup | 爬取电影天堂全站电影资源
import requests import urllib.request as ur from bs4 import BeautifulSoup import csv import threadin ...
随机推荐
- Spring MVC-从零开始-分拆applicationContext. xrnl
1.目录结构 2.web.xml配置 <?xml version="1.0" encoding="ISO-8859-1"?> <web-app ...
- json与java对象的转换,以及struts2对json的支持,实现ajax技术
这两天学的东西有点多,今天抽个时间写下来,以此作为激励,这两天学了json,ajax,jQuery 一.使用第三方的工具java转换为json类型 首先就是java类型转换为json对象,首先要导入第 ...
- 如何提高scroll事件的性能
1. chrome devtool 是诊断页面滚动性能的有效工具 2. 提升滚动时性能,就是要达到fps高且稳. 3. 具体可以从以下方面着手 使用web worker分离无页面渲染无关的逻辑计算 触 ...
- 触电JavaScript-如何将json 二维数组转换为 JSON object
最近因为项目中使用的是 ActiveReports .Net 产品,因为他们最近新出了 ActiveReports JS 版本,所以内心有点痒痒,想试试这个纯前端版本报表控件到底如何,毕竟我们项目有 ...
- Android适配总结
1.dp与px的 密度类型 代表的分辨率 屏幕密度 换算 比例 低密度(ldpi) 240x320 120 1dp=0.75px 3 中密度(mdpi) 320x480 160 1dp = 1px 4 ...
- Android中Project、Module的区别
Project 可以包含多含 Module. Project相当于eclipse里面的工作区间,module相当于其project.module可以作为狭义上的模块,可以多个app共用的module. ...
- 50个实用的jq代码段整理
个人博客: http://mcchen.club 1. 如何创建嵌套的过滤器: //允许你减少集合中的匹配元素的过滤器, //只剩下那些与给定的选择器匹配的部分.在这种情况下, //查 ...
- Mac搭建 Eclipse +Pydev+Python 环境
Mac配置Python开发环境(Eclipse +Pydev+Python) 1.首先下载MAC版的64位Eclipse. eclips下载地址打开链接,选择需要的版本下载 2.下载Python. M ...
- 【前端词典】4 个实用有趣的 JS 特性
前言 最近在学习的过程中发现了我之前未曾了解过的一些特性,发现有些很有趣并且在处理一些问题的时候可以给我一个新的思路. 这里我将这些特性介绍给大家. 4 个有趣的 JS 特性 利用 a 标签解析 UR ...
- 代码审计-Beescms_V4.0
Beescms_V4.0代码审计源于一场AWD线下比赛的漏洞源码 看了别的师傅的文章发现这个源码也非常简单 ,所以今晚简单审计过一遍. 0x01 预留后门 awd首先备份源码,然后下载下来查杀后门, ...