Node.js爬虫实战 - 爬你喜欢的
前言
今天没有什么前言,就是想分享些关于爬虫的技术,任性。来吧,各位客官,里边请...
开篇第一问:爬虫是什么嘞?
首先咱们说哈,爬虫不是“虫子”,姑凉们不要害怕。
爬虫 - 一种通过一定方式按照一定规则抓取数据的操作或方法。
开篇第二问:爬虫能做什么嘞?
来来来,谈谈需求
产品MM:
- 爱豆的新电影上架了,整体电影评价如何呢?
- 暗恋的妹子最近又失恋了,如何在她发微博的时候第一时间知道发了什么,好去呵护呢?
- 总是在看小说的时候点到广告?总是在看那啥的时候点出来,澳xx场又上线啦?
- 做个新闻类网站没有数据源咋办?
研发GG:
爬虫随时准备为您服务!
- 使用爬虫,拉取爱豆视频所有的评价,导入表格,进而分析评价
- 使用爬虫,加上定时任务,拉取妹子的微博,只要数据有变化,接入短信或邮件服务,第一时间通知
- 使用爬虫,拉取小说内容或xxx的视频,自己再设计个展示页,perfect!
- 使用爬虫,定时任务,拉取多个新闻源的新闻,存储到数据库
开篇第三问:爬虫如何实现嘞?
实现爬虫的技术有很多,如python、Node等,今天胡哥给大家分享使用Node做爬虫:爬取小说网站-首页推荐小说
爬取第一步-确定目标
目标网站:https://www.23us.so
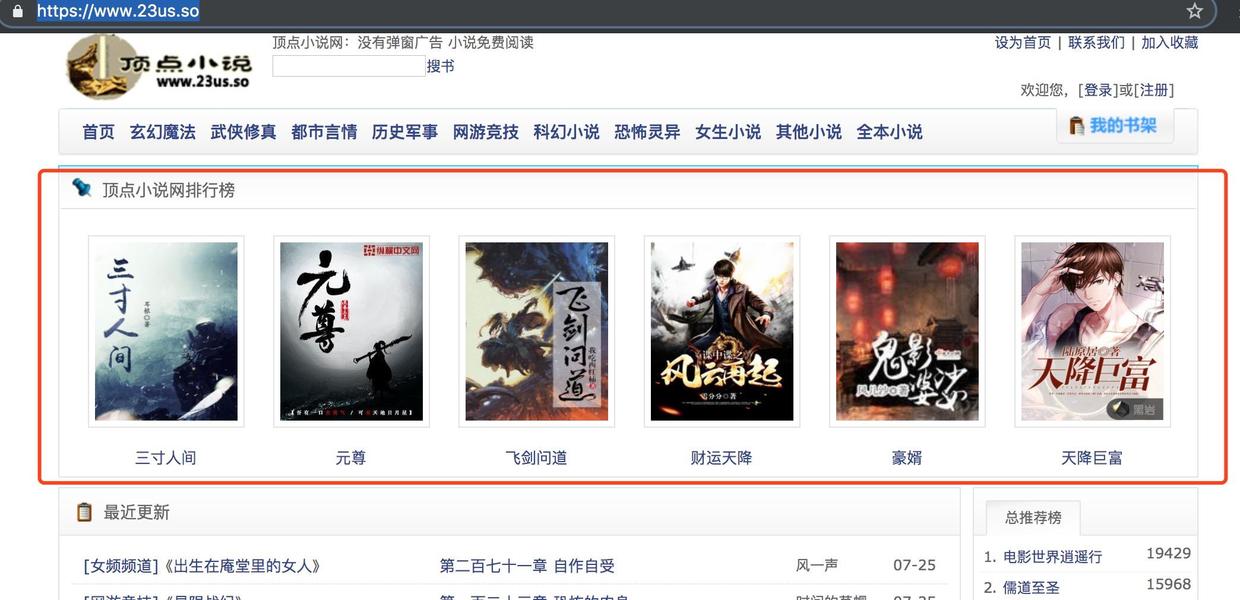
我们要获取排行榜中六部小说的:书名、封面、以及小说书籍信息对应的地址(后续获取小说完整信息)
爬取第二步-分析目标特点
网页的内容是由HTML生成的,抓取内容就相当找到特定的HTML结构,获取该元素的值。
打开网页调试控制台,查看元素HTML结构。
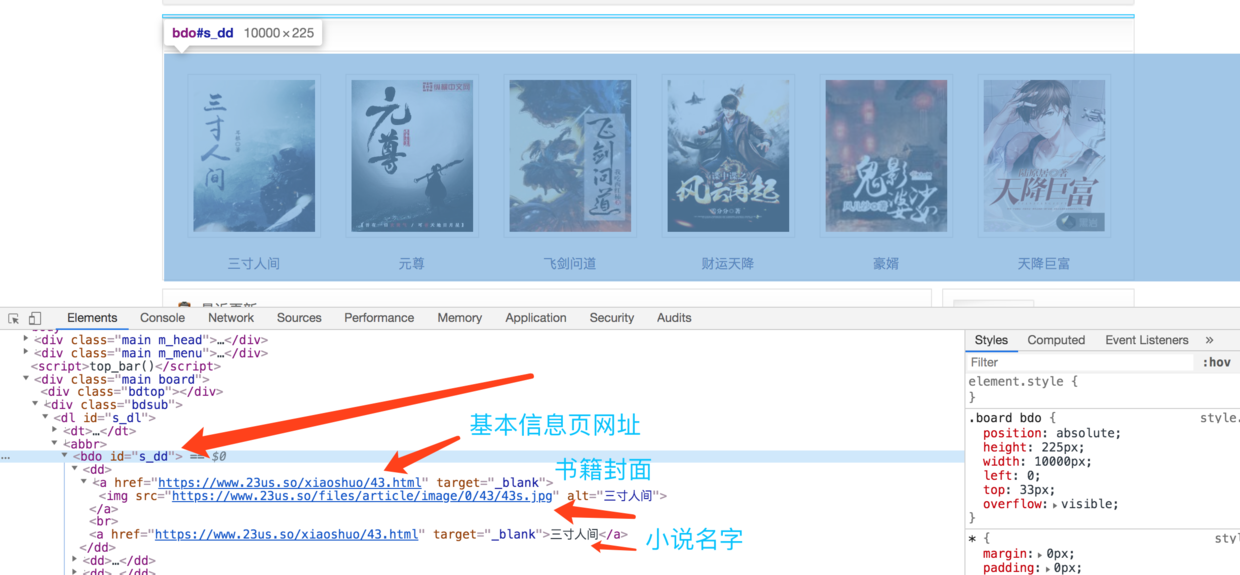
注意观察页面HTML的结构,排行榜推荐的小说的HTML结构是
bdo#s-dd 元素
dd 子元素 - 每一部小说
a 目录信息
img 封面
a 小说名称
爬取第三步-弄丫的
工具善其事必先利其器,准备好趁手的兵器!
superagent
模拟客户端发送网络请求,可设置请求参数、header头信息
npm install superagent -D
cheerio
类jQuery库,可将字符串导入,创建对象,用于快速抓取字符串中的符合条件的数据
npm install cheerio -D
项目目录:
node-pachong/
- index.js
- package.json
- node_modules/
上代码:
// node-pachong/index.js
/**
* 使用Node.js做爬虫实战
* author: justbecoder <justbecoder@aliyun.com>
*/
// 引入需要的工具包
const sp = require('superagent');
const cheerio = require('cheerio');
// 定义请求的URL地址
const BASE_URL = 'http://www.23us.so';
// 1. 发送请求,获取HTML字符串
(async () => {
let html = await sp.get(BASE_URL);
// 2. 将字符串导入,使用cheerio获取元素
let $ = cheerio.load(html.text);
// 3. 获取指定的元素
let books = []
$('#s_dd dd').each(function () {
let info = {
link: $(this).find('a').eq(0).attr('href'),
name: $(this).find('a').eq(1).text(),
image: $(this).find('img').attr('src')
}
books.push(info)
})
console.log(books)
})()
友情提醒:每个网站的HTML结构是不一样,在抓取不同网站的数据时,要分析不同的解构,才能百发百中。
效果图:
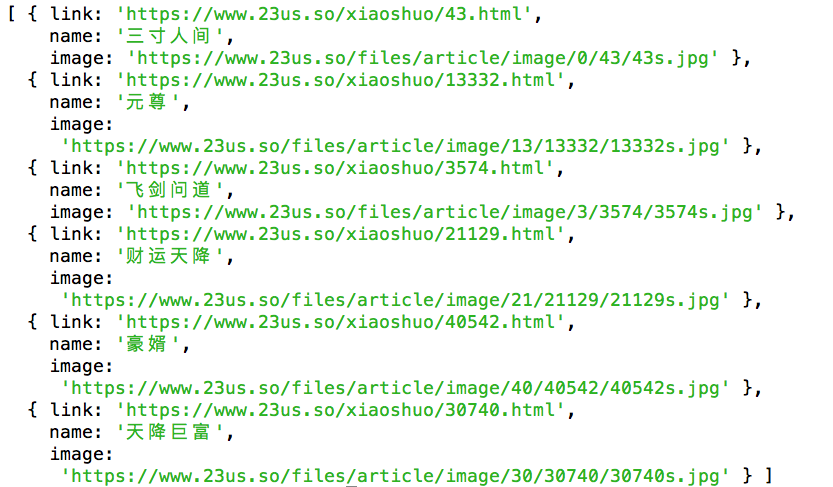
获取到信息之后,做接口数据返回、存储数据库,你想干啥都行...
源码获取
关注胡哥有话说公众号,回复“爬虫”,即可获取源码地址。
后记
以上就是胡哥今天给大家分享的内容,喜欢的小伙伴记得收藏、转发、点击右下角按钮在看,推荐给更多小伙伴呦,欢迎多多留言交流...
胡哥有话说,一个有技术,有情怀的胡哥!京东开放平台首席前端攻城狮。与你一起聊聊大前端,分享前端系统架构,框架实现原理,最新最高效的技术实践!
长按扫码关注,更帅更漂亮呦!关注胡哥有话说公众号,可与胡哥继续深入交流呦!

Node.js爬虫实战 - 爬你喜欢的的更多相关文章
- Node JS爬虫:爬取瀑布流网页高清图
原文链接:Node JS爬虫:爬取瀑布流网页高清图 静态为主的网页往往用get方法就能获取页面所有内容.动态网页即异步请求数据的网页则需要用浏览器加载完成后再进行抓取.本文介绍了如何连续爬取瀑布流网页 ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- 《Node.js开发实战详解》学习笔记
<Node.js开发实战详解>学习笔记 ——持续更新中 一.NodeJS设计模式 1 . 单例模式 顾名思义,单例就是保证一个类只有一个实例,实现的方法是,先判断实例是否存在,如果存在则直 ...
- node.js爬虫
这是一个简单的node.js爬虫项目,麻雀虽小五脏俱全. 本项目主要包含一下技术: 发送http抓取页面(http).分析页面(cheerio).中文乱码处理(bufferhelper).异步并发流程 ...
- Koa与Node.js开发实战(3)——Nunjucks模板在Koa中的应用(视频演示)
技术架构: 在Koa中应用Nunjucks,需要先把Nunjucks集成为符合Koa规格的中间件(Middleware),从本质上来讲,集成后的中间件的作用是给上下文对象绑定一个render(vi ...
- Node.js aitaotu图片批量下载Node.js爬虫1.00版
即使是https网页,解析的方式也不是一致的,需要多试试. 代码: //====================================================== // aitaot ...
- Node.js umei图片批量下载Node.js爬虫1.00
这个爬虫在abaike爬虫的基础上改改图片路径和下一页路径就出来了,代码如下: //====================================================== // ...
- Node.js abaike图片批量下载Node.js爬虫1.01版
//====================================================== // abaike图片批量下载Node.js爬虫1.01 // 1.01 修正了输出目 ...
随机推荐
- 《转载黑马教程》HTML&&CSS讲义,仅供参考
今日内容: 1. HTML标签:表单标签 2. CSS: HTML标签:表单标签 * 表单: * 概念:用于采集用户输入的数据的.用于和服务器进行交互. * form:用于定义表单的.可以定义一个范围 ...
- Greenplum主备节点切换
1. 场景描述 Greenplum主节点出现故障,需要将standby节点手动切换为master节点,当master节点修复完成后,再将新修复的master节点设置为standyb节点加入到集群中. ...
- 5分钟完成mysql离线安装
1. 场景描述 mysql离线安装并不复杂,就是经常会出现漏东西,有时候的搞半天,总结下,快速离线安装mysql,直接把下面的命令敲一遍就好,5-10分钟就能安装好. 2. 解决方案 安装的mysql ...
- [NOIP2016]换教室 题解(奇怪的三种状态)
2558. [NOIP2016]换教室 [题目描述] 对于刚上大学的牛牛来说,他面临的第一个问题是如何根据实际情况申请合适的课程. 在可以选择的课程中,有2n节课程安排在n个时间段上.在第i(1< ...
- android_layout_relativelayout(一)
android的相对布局relativelayout也是一个值得研究的部分.先归纳下最近的几个心得. 相对布局中,xml文件第一个控件总是在屏幕的左上角为它的位置,别管你手机是竖着的还是横着的. 从第 ...
- 快速掌握mongoDB(四)—— C#驱动MongoDB用法演示
前边我们已经使用mongo shell进行增删查改和聚合操作,这一篇简单介绍如何使用C#驱动MongoDB.C#驱动MongoDB的本质是将C#的操作代码转换为mongo shell,驱动的API也比 ...
- 洛谷P4995 跳跳!题解
求关注,求赞,求评论QAQ 题目:https://www.luogu.org/problemnew/show/P4995 简单描述一下吧,就是说有n块石头,起始可以跳到任何一块上面,接着也是,只不过每 ...
- koa2服务端使用jwt进行鉴权及路由权限分发
大体思路 后端书写REST api时,有一些api是非常敏感的,比如获取用户个人信息,查看所有用户列表,修改密码等.如果不对这些api进行保护,那么别人就可以很容易地获取并调用这些 api 进行操作. ...
- 题解 P3126 【[USACO15OPEN]回文的路径Palindromic Paths】
P3126 [USACO15OPEN]回文的路径Palindromic Paths 看到这题题解不多,蒟蒻便想更加通俗易懂地分享一点自己的心得,欢迎大佬批评指正^_^ 像这种棋盘形的两边同时做的dp还 ...
- JS+Jquery自定义格式导出HTML为Word(下列插件同样可以用于Excel导出)
这里的word导出主要采用了jquery.wordexport.js.FileSaver.js,做功能之前我也是找了很多网上的资料,里面涉及到js导出word的用的都是这个插件,只是在自定义样式这一块 ...