python爬虫之PyQuery的基本使用
PyQuery库也是一个非常强大又灵活的网页解析库,如果你有前端开发经验的,都应该接触过jQuery,那么PyQuery就是你非常绝佳的选择,PyQuery 是 Python 仿照 jQuery 的严格实现。语法与 jQuery 几乎完全相同,所以不用再去费心去记一些奇怪的方法了。
官网地址:http://pyquery.readthedocs.io/en/latest/
jQuery参考文档: http://jquery.cuishifeng.cn/
1、字符串的初始化
from pyquery import PyQuery as pq html = '''<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
print(doc)
print(type(doc))
print(doc('li'))
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>
<class 'pyquery.pyquery.PyQuery'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
运行结果
2、打开html文件
注意路劲问题
from pyquery import PyQuery as pq
doc = pq(filename='index.html')
print(doc)
print(doc('head'))
<title>Title</title>
</head>
<body>
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>'''
</body>
</html>
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
运行结果
3、打开某个网站
doc = pq('https://www.baidu.com')
# doc1 = pq(url='https://www.baidu.com')
print(doc)
print(doc('head'))
4、基于CSS选择器查找
from pyquery import PyQuery as pq html = '''<div>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
print(doc)
#id等于haha下面的class等于item-0下的a标签下的span标签(注意层级关系以空格隔开)
print(doc('#haha .item-0 a span'))
<div>
<ul id="haha">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>
<span class="bold">third item</span>
运行结果
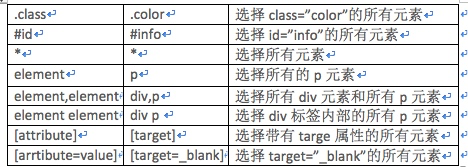
5、可以通过已经查找的标签,查找这个标签下的子标签或者父标签,而不用从头开始查找。
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
item = doc('div ul')
print(item)
#我们可以通过已经查找到的标签,再此查找这个标签下面的标签
print(item.parent())
print(item.children())
<ul id="haha">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
<div class="‘content’">
<ul id="haha">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
运行结果
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
item = doc('div ul')
print(item)
#注意这里查找ul标签的所有子标签,也就是li标签,下面是查找class属性的标签,如果你把class换成href肯定不行,它指的只是儿子并不是子子孙孙
print(item.children('[class]'))
6、获取属性值
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
#注意class=item-0 active是一个class的属性,但是在pyquery里面要是中间也是空格隔开的话,
#就变成了item-0下的active标签下的a标签了,所以这里空格必须改成点
item = doc(".item-0.active a")
print(type(item))
print(item)
#获取属性值的两种方法
print(item.attr.href)
print(item.attr('href'))
<class 'pyquery.pyquery.PyQuery'>
<a href="link3.html"><span class="bold">third item</span></a>
link3.html
link3.html
运行结果
7、获取标签的内容
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
a = doc("a").text()
print(a)
#结果很有趣,他是找到所有标签的值,然后给连到一起打出来,就像一段话
second item third item fourth item fifth item
运行结果
8、Dom操作
1、属性的增加删除操作
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
li = doc('.item-0.active')
print(li)
#删除classactive
print(li.removeClass('active'))
#增加class属性haha
print(li.addClass('haha'))
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-0"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-0 haha"><a href="link3.html"><span class="bold">third item</span></a></li>
运行结果
2、attrs和css
注意:下列操作有则改之,无则加之。
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
li = doc('.item-0.active')
print(li)
print(li.attr('id','id_test'))
print(li.css('font-size','20px'))
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-0 active" id="id_test"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-0 active" id="id_test" style="font-size: 20px"><a href="link3.html"><span class="bold">third item</span></a></li>
运行结果
3、删除某个标签,在爬去过程中我们通常爬去一下标签或者内容下来的时候总会有些不想要的标签,这个时候我们可以用下面的类似方法删除这个标签。
from pyquery import PyQuery as pq html = '''<div class='content'>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
data = doc('.content')
print(data.text())
#删除所有a标签
data.find('a').remove()
#再次打印
print(data.text())
first item second item third item fourth item fifth item
first item
运行结果
python爬虫之PyQuery的基本使用的更多相关文章
- Python爬虫之PyQuery使用(六)
Python爬虫之PyQuery使用 PyQuery简介 pyquery能够通过选择器精确定位 DOM 树中的目标并进行操作.pyquery相当于jQuery的python实现,可以用于解析HTML网 ...
- python爬虫神器PyQuery的使用方法
你是否觉得 XPath 的用法多少有点晦涩难记呢? 你是否觉得 BeautifulSoup 的语法多少有些悭吝难懂呢? 你是否甚至还在苦苦研究正则表达式却因为少些了一个点而抓狂呢? 你是否已经有了一些 ...
- python爬虫之pyquery学习
相关内容: pyquery的介绍 pyquery的使用 安装模块 导入模块 解析对象初始化 css选择器 在选定元素之后的元素再选取 元素的文本.属性等内容的获取 pyquery执行DOM操作.css ...
- 【Python爬虫】PyQuery解析库
PyQuery解析库 阅读目录 初始化 基本CSS选择器 查找元素 遍历 获取信息 DOM操作 伪类选择器 PyQuery 是 Python 仿照 jQuery 的严格实现.语法与 jQuery 几乎 ...
- Python爬虫之pyquery库的基本使用
# 字符串初始化 html = ''' <div> <ul> <li class = "item-0">first item</li> ...
- Python爬虫系列-PyQuery详解
强大又灵活的网页解析库.如果你觉得正则写起来太麻烦,如果你觉得BeautifulSoup语法太难记,如果你熟悉jQuery的语法,那么PyQuery就是你的最佳选择. 安装 pip3 install ...
- python爬虫之PyQuery
# -*- coding: UTF-8 -*- from pyquery import PyQuery as pq import re from datetime import datetime,ti ...
- Python爬虫利器六之PyQuery的用法
前言 你是否觉得 XPath 的用法多少有点晦涩难记呢? 你是否觉得 BeautifulSoup 的语法多少有些悭吝难懂呢? 你是否甚至还在苦苦研究正则表达式却因为少些了一个点而抓狂呢? 你是否已经有 ...
- 小白学 Python 爬虫(23):解析库 pyquery 入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- SQL Server 数据导入Mysql具体教程
SQLServer2005数据导入Mysql到具体教程(測试) SQL SERVER数据导入MYSQL文件夹 1.Navicat for MySQL 版本号10.0.9 2.创建目标数据库 3.创 ...
- UVA129-Krypton Factor(搜索剪枝)
Problem UVA129-Krypton Factor Accept:1959 Submit:10261 Time Limit: 3000 mSec Problem Description 通 ...
- 在Ubuntu上安装Jenkins
先决条件 安装Java SDK sudo apt-get install openjdk-8-jdk # sudo apt-get install openjdk-7-jdk 早些系统可以安装 第1步 ...
- 机器学习算法总结(十二)——流形学习(Manifold Learning)
1.什么是流形 流形学习的观点:认为我们所能观察到的数据实际上是由一个低维流行映射到高维空间的.由于数据内部特征的限制,一些高维中的数据会产生维度上的冗余,实际上这些数据只要比较低的维度就能唯一的表示 ...
- day 03 基本数据类型的使用、运算符
一:基本数据类型的使用 1.为什么数据要区分类型 数据类型指的是变量值的类型,变量值是用来记录事物的状态的,而事物的状态具有不同的类型,不同类型的变量值表示不同类型的状态,所以数据要区分类型. 2.数 ...
- memcache讲解和在.net中初使用
memcache讲解和在.net中初使用 2017年10月17日 22:51:36 等待临界 阅读数:503 前言 传统数据库面临的问题 数据库死锁 磁盘IO 正文 了解memcache 原理 基 ...
- WPF(一)
什么是WPF WPF(Windows Presentation Foundation)是用于Windows的现代图形显示系统.与之前出现的技术相比,WPF发生了根本性变化.WPF引用了"内置 ...
- [MicroPython]TPYBoard智能小车“飞奔的TPYBoard装甲一号”
智能小车作为现代的新发明,是以后的发展方向,他可以按照预先设定的模式在一个环境里自动的运作,不需要人为的管理,可应用于科学勘探等等的用途.智能小车能够实时显示时间.速度.里程,具有自动寻迹.寻光.避障 ...
- Java IO(五)——字符流进阶及BufferedWriter、BufferedReader
一.字符流和字节流的区别 拿一下上一篇文章的例子: package com.demo.io; import java.io.File; import java.io.FileReader; impor ...
- Sqlserver内存管理:限制最大占用内存(转载)
一.Sqlserver对系统内存的管理原则是:按需分配,且贪婪(用完不还).它不会自动释放内存,因此执行结果集大的sql语句时,数据取出后,会一直占用内存,直到占满机器内存(并不会撑满,还是有个最大限 ...