行人重识别(ReID) ——概述
什么是Re-ID?
- 行人重识别(Person re-identification,简称Re-ID)也称行人再识别,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。广泛被认为是一个图像检索的子问题。给定一个监控行人图像,检索跨设备下的该行人图像。旨在弥补目前固定的摄像头的视觉局限,并可与行人检测/行人跟踪技术相结合,可广泛应用于智能视频监控、智能安保等领域。
- 如下图所示:一个区域有多个摄像头拍摄视频序列,ReID的要求对一个摄像头下感兴趣的行人,检索到该行人在其他摄像头下出现的所有图片。

为什么要Re-ID?
在监控视频中,由于相机分辨率和拍摄角度的缘故,通常无法得到质量非常高的人脸图片。当人脸识别失效的情况下,ReID就成为了一个非常重要的替代品技术。
研究形式
- 数据集通常是通过人工标注或者检测算法得到的行人图片,目前与检测独立,注重识别
- 数据集分为训练集、验证集、Query、Gallery
- 在训练集上进行模型的训练,得到模型后对Query与Gallery中的图片提取特征计算相似度,对于每个Query在Gallery中找出前N个与其相似的图片
- 训练、测试中人物身份不重复

两大方向
- 特征提取:学习能够应对在不同摄像头下行人变化的特征
- 度量学习 :将学习到的特征映射到新的空间使相同的人更近不同的人更远
存在挑战
- 不同下摄像头造成行人外观的巨大变化;
- 目标遮挡(Occlusion)导致部分特征丢失;
- 不同的 View,Illumination 导致同一目标的特征差异;
- 不同目标衣服颜色近似、特征近似导致区分度下降;
常用数据集
CUHK03
Market1501
DukeMTMC-reID
MSMT17
这里只列举了常用的数据集,更全的数据集可以参考:Person Re-identification Datasets
常用评价指标
- rank-k:算法返回的排序列表中,前k位为存在检索目标则称为rank-k命中。eg:rank1:首位为检索目标则rank-1命中。
- Cumulative Match Characteristic (CMC)
举个很简单的例子,假如在人脸识别中,底库中有100个人,现在来了1个待识别的人脸(假如label为m1),与底库中的人脸比对后将底库中的人脸按照得分从高到低进行排序,我们发现:
如果识别结果是m1、m2、m3、m4、m5……,则此时rank-1的正确率为100%;rank-2的正确率也为100%;rank-5的正确率也为100%;
如果识别结果是m2、m1、m3、m4、m5……,则此时rank-1的正确率为0%;rank-2的正确率为100%;rank-5的正确率也为100%;
如果识别结果是m2、m3、m4、m5、m1……,则此时rank-1的正确率为0%;rank-2的正确率为0%;rank-5的正确率为100%;
同理,当待识别的人脸集合有很多时,则采取取平均值的做法。例如待识别人脸有3个(假如label为m1,m2,m3),同样对每一个人脸都有一个从高到低的得分,
比如:
人脸1结果为m1、m2、m3、m4、m5……,
人脸2结果为m2、m1、m3、m4、m5……,
人脸3结果m3、m1、m2、m4、m5……,
则此时rank-1的正确率为(1+1+1)/3=100%;
rank-2的正确率也为(1+1+1)/3=100%;
rank-5的正确率也为(1+1+1)/3=100%;
比如:
人脸1结果为m4、m2、m3、m5、m6……,
人脸2结果为m1、m2、m3、m4、m5……,
人脸3结果m3、m1、m2、m4、m5……,
则此时rank-1的正确率为(0+0+1)/3=33.33%;
rank-2的正确率为(0+1+1)/3=66.66%;
rank-5的正确率也为(0+1+1)/3=66.66%;
curve:计算rank-k的击中率,形成rank-acc的曲线,如下图:
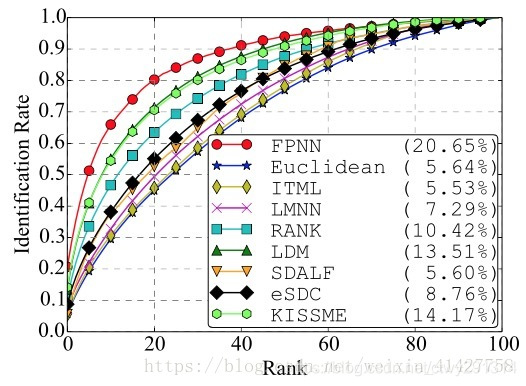
- mAP(mean average precision):反应检索的人在数据库中所有正确的图片排在排序列表前面的程度,能更加全面的衡量ReID算法的性能。如下图,假设该检索行人在gallery中有10张图片,在检索的list中位置(rank)分别为1、2、3、4、5、6、7、8、9,则ap为(1/ 1 + 2 / 2 + 3 / 3 + 4 / 4 + 5 / 5 + 6 / 6 + 7 / 7 + 8 / 8 + 9 / 9) / 10 = 0.90;ap较大时,该行人的检索结果都相对靠前,对所有query的ap取平均值得到mAP

一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
正确率 = 检测出来的正样本数/检测出来的总数
召回率 = 检测出来的正样本数/所有正样本个数
我们来举一个新的例子。
假设有一个搜索引擎,根据搜索引擎,有如下结果:
搜索1相关的样本总共有5个: 正,正,正,正,正
| Rank1 | 正 | 负 | 正 | 负 | 负 | 正 | 负 | 负 | 正 | 正 |
|---|---|---|---|---|---|---|---|---|---|---|
| Recall | 1/5=0.2 | 1/5=0.2 | 2/5=0.4 | 2/5=0.4 | 2/5=0.4 | 3/5=0.6 | 3/5=0.6 | 3/5=0.6 | 4/5=0.8 | 5/5=1.0 |
| Precision | 1/1=1.0 | 1/2=0.5 | 2/3=0.66 | 2/4=0.5 | 2/5=0.4 | 3/6=0.5 | 3/7=0.42 | 3/8=0.38 | 4/9=0.44 | 7/10=0.5 |
Precision从左到右1/1, 1/2, 2/3, 2/4…以此类推
搜索2相关样本总共有3个,以下是搜索引擎返回的结果
| Rank1 | 正 | 负 | 负 | 正 | 正 | 负 | 负 |
|---|---|---|---|---|---|---|---|
| Recall | 0.33 | 0.33 | 0.33 | 0.66 | 1 | 1 | 1 |
| Precision | 1.0 | 0.5 | 0.33 | 0.5 | 0.6 | 0.5 | 0.43 |
我们把每个正样本所对应的Precision求平均
搜索1的mAP:mAP = (1/1 + 2/3 + 3/6 + 4/9+ 5/10) / 5 = 0.72
搜索2的mAP: mAP = (1/1 + 2/4 + 3/5) / 3 = 0.63
整体的mAP = (0.72 + 0.63) /2 = 0.675
行人重识别(ReID) ——概述的更多相关文章
- 行人重识别(ReID) ——数据集描述 DukeMTMC-reID
数据集简介 DukeMTMC 数据集是一个大规模标记的多目标多摄像机行人跟踪数据集.它提供了一个由 8 个同步摄像机记录的新型大型高清视频数据集,具有 7,000 多个单摄像机轨迹和超过 2,700 ...
- 行人重识别(ReID) ——数据集描述 Market-1501
数据集简介 Market-1501 数据集在清华大学校园中采集,夏天拍摄,在 2015 年构建并公开.它包括由6个摄像头(其中5个高清摄像头和1个低清摄像头)拍摄到的 1501 个行人.32668 个 ...
- 行人重识别(ReID) ——基于深度学习的行人重识别研究综述
转自:https://zhuanlan.zhihu.com/p/31921944 前言:行人重识别(Person Re-identification)也称行人再识别,本文简称为ReID,是利用计算机视 ...
- 行人重识别(ReID) ——技术实现及应用场景
导读 跨镜追踪(Person Re-Identification,简称 ReID)技术是现在计算机视觉研究的热门方向,主要解决跨摄像头跨场景下行人的识别与检索.该技术能够根据行人的穿着.体态.发型等信 ...
- 行人重识别(ReID) ——数据集描述 CUHK03
数据集简介 CUHK03是第一个足以进行深度学习的大规模行人重识别数据集,该数据集的图像采集于香港中文大学(CUHK)校园.数据以"cuhk-03.mat"的 MAT 文件格式存储 ...
- 行人重识别(ReID) ——基于Person_reID_baseline_pytorch修改业务流程
下载Person_reID_baseline_pytorch地址:https://github.com/layumi/Person_reID_baseline_pytorch/tree/master/ ...
- 行人重识别(ReID) ——基于MGN-pytorch进行可视化展示
下载MGN-pytorch:https://github.com/seathiefwang/MGN-pytorch 下载Market1501数据集:http://www.liangzheng.org/ ...
- CVPR2020行人重识别算法论文解读
CVPR2020行人重识别算法论文解读 Cross-modalityPersonre-identificationwithShared-SpecificFeatureTransfer 具有特定共享特征变换 ...
- 行人重识别和车辆重识别(ReID)中的评测指标——mAP和Rank-k
1.mAP mAP的全称是mean Average Precision,意为平均精度均值(如果按照原来的顺利翻译就是平均均值精度).这个指标是多目标检测和多标签图像分类中长常用的评测指标,因为这类任务 ...
随机推荐
- MySQL两个时间相减
SELECT TIMESTAMPDIFF(MONTH,'2009-10-01','2009-09-01'); interval可是: SECOND 秒 SECONDS MINUTE 分钟 MINUTE ...
- Jupyter配置Spark开发环境
兄弟连大数据培训和大家一起探究Jupyter配置 Spark 开发环境 简介 为Jupyter配置Spark开发环境,可以安装全家桶–Spark Kernel或Toree,也可按需安装相关组件. 考虑 ...
- eclipse配置Maven——菜鸟篇
首先解释关于webservice: Web service是一个平台独立的,低耦合的,自包含的.基于可编程的web的应用程序, 可使用开放的XML(标准通用标记语言下的一个子集)标准来描述.发布.发现 ...
- android 小游戏 ---- 数独(二)
> 首先创建一个自己的View类 -->继承SurfaceView并实现SurfaceHolder.Callback接口 --> SurfaceView.getHolder ...
- http协议的深刻理解
https://www.cnblogs.com/mayite/p/9095986.html
- POJ 1383 Labyrinth (bfs 树的直径)
Labyrinth 题目链接: http://acm.hust.edu.cn/vjudge/contest/130510#problem/E Description The northern part ...
- 如何将一个SpringBoot简便地打成一个war包(亲测有效)
正常情况下SpringBoot项目是以jar包的形式,通过命令行: 来运行的,并且SpringBoot是内嵌Tomcat服务器,所以每次重新启动都是用的新的Tomcat服务器.正因如此,也出现了一个问 ...
- React-Native 之 GD (十)Android启动页面 及 模态方式跳转
1.Android启动页面 思路:新建一个组件作为 Android 的启动页,index.android.js 的初始化窗口改为 Android启动页,设置定时器,使其在1.5秒后自动跳转到 Main ...
- (转)VS2010结合水晶报表做条码标签打印功能
本文转载自:http://blog.sina.com.cn/s/blog_552ca1400100y6dd.html 先来个功能效果图: 大家都知道VS2005和VS2008软件本身是包含水晶报表插件 ...
- scrapy Pipeline使用twisted异步实现mysql数据插入
from twisted.enterprise import adbapi class MySQLAsyncPipeline: def open_spider(self, spider): db = ...