spark复习笔记(5):API分析
0.spark是基于hadoop的mr模型,扩展了MR,高效实用MR模型,内存型集群计算,提高了app处理速度。
1.特点:(1)在内存中存储中间结果
(2)支持多种语言:java scala python
(3)内置了80多种算子
2.sparkCore模块(通用执行引擎)
(1)通用的执行引擎,提供内存计算和对外部数据集的引用。
3.spark sql
(1)Spark SQL是Spark Core之上的组件,引入了新的数据抽象称为SchemaRDD,它为结构化和半结构化数据提供支持。
4.Spark Streaming
(1)Spark流利用Spark Core的快速调度功能来执行流分析。它以小批的形式获取数据,并对这些小批的数据执行RDD(弹性分布式数据集)转换。
5.MLlib(Machoine Learning Library)
(1)MLib是一个分布式内存的Spark架构的分布式机器学习框架。根据基准测试,这是由MLlib开发人员针对交替最小而成法(ALS)实现所做的。
一、RDD弹性分布式数据集
(1)弹性分布式数据集RDD是Spark的一个基本数据结构
(2)是对象的不可变数据集
(3)在RDD中的每个数据集都被分成一个个逻辑分区,这使其能够在集群的不同节点上进行计算
(4)RDD能够包含任何类型的Python,Java,或者Scala对象,包括用户自定义类
(5)正常情况下,RDD是一个只读的记录分区集合。RDDs可以通过对稳定存储数据或其他RDDs进行确定性操作来创建。RDD是可以并行操作的元素的容错集合。
(6)有两种方式来创建RDD:在你的驱动程序里面并行化一个存在的集合,对现有集合进行并行处理;第二种方式是引用一个外部存储的数据集
(7)由于复制、序列化和磁盘io,MapReduce中的数据共享很慢。大多数Hadoop应用程序,它们花费90%以上的时间进行HDFS读写操作。认识到这个问题,研究人员开发了一个专门的框架,叫ApacheSequence。SMART的核心思想是弹性分布式数据集(RDD),它支持内存中的处理计算。这意味着,它将内存状态存储为跨作业的对象,并且该对象在这些作业之间是可共享的。内存中的数据共享速度是网络和磁盘的10至100倍。现在让我们来看看在SparkRDD中迭代和交互操作是如何发生的。
(8)在spark RDD上的迭代式操作
下图显示了一个一个在Spark RDD上的迭代式操作,它会将结果存储在分布式内存而不是本地稳定的存储系统并且使得系统更加快。如果分布式内存足够高效的存储中间结果,那么它将会这些结果存储在磁盘上
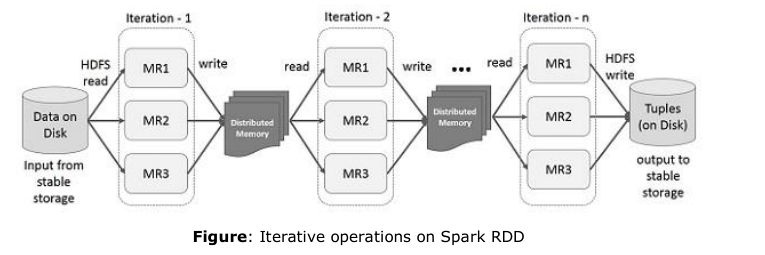
默认情况下,每次在其上运行操作时,都可能重新计算每个转换后的RDD。但是,您也可以在内存中持久化一个RDD,在这种情况下,Spark会在下一次查询时将集群上的元素保持在周围,以获得更快的访问速度。还支持在磁盘上持久化RDD,或跨多个节点进行复制。
(9)RDD内部包含了5个主要的属性
分区列表
应用给每个切片的计算函数
到其他RDD的依赖列表 //决定依赖关系
(可选的)针对key-value类型的RDD的分区类
(可选的)首选块位置列表
(10)MapPartitionsRDD:针对父RDD的每个分区提供了函数构成的新类型的RDD
(11)ShuffleRDD:从混洗中产生结果的RDD(如数据的再分区)
(12)[DAGScheduler]高级调度器层面,实现按照阶段进行调度(stage),按照shuffle进行判断,实现了面向阶段的调度,对RDD作业的各个阶段计算有向无环图,并且跟踪RDD和每个阶段的输出,找出最小的调度来运行作业,将stage对象以任务集的方式提交给底层的调度器,底层调度器要实现任务调度器,进而在集群上来运行作业。TaskSet已经包含了全部的单独的task,这些task都能基于cluster的数据进行正确的运行
stage通过在需要shuffle的边界处将RDD打碎来创建Stage对象。具有宅依赖RDD的操作,比如map(),filter(),是被管线化一起形成一个任务集。在每个stage中形成一个RDD任务集,被管道化到一个任务集中去了。而具有shuffle依赖的操作则包含多个阶段,一个stage用于输出,另外一个stage用于输入。最后每个阶段只有shuffle依赖。
(13)DAG调度器检测首选位置来运行rask,通过基于当前的缓存状态,并传递给底层的任务调度器来实现
二、术语介绍
[job]
提交给调度的顶层的工作项目,由ActiveJob来进行表示
[Stage]
是task的集合,计算job中的中间结果。同一个RDD上的每个任务都会计算同一个函数
[RDD]
分区的集合,关联一个计算函数,在每个分区上关联一个计算函数,阶段=被分开。stage在shuffle边界处进行分离,这会引进一个隔离,需要上一个stage完成后才能得到一个输出结果
[Task]任务是单独的工作单元。每个发送给一台主机
[cache tracking]缓存跟踪。DAG调度器会找出哪些RDD被缓存。避免不必要的重复计算。同样的,也会记住哪个shufflemap已经输出了结果。可以避免map端shuffle的重复处理。
[Preferred locations]
dag调度器根据rdd的中首选位置属性在哪里运行
[Cleanup]所依赖的作业完成的时候,数据会被清理,为了防止内存泄露。主要针对耗时计算为了容错,统一阶段可能会运行多次,我们称之为attempt
[ActiveJob]在DAG调度器中运行的作业,称为Active Job。作业分为两种类型,
[sparkContext]
/**
* Default min number of partitions for Hadoop RDDs when not given by user
* Notice that we use math.min so the "defaultMinPartitions" cannot be higher than 2.默认的最小分区数不能超过2
* The reasons for this are discussed in https://github.com/mesos/spark/pull/718
*/
def defaultMinPartitions: Int = math.min(defaultParallelism, 2)
spark复习笔记(5):API分析的更多相关文章
- spark复习笔记(4):spark脚本分析
1.[start-all.sh] #!/usr/bin/env bash # # Licensed to the Apache Software Foundation (ASF) under one ...
- Spark 学习笔记 —— 常见API
一.RDD 的创建 1)通过 RDD 的集合数据结构,创建 RDD sc.parallelize(List(1,2,3),2) 其中第二个参数代表的是整个数据,分为 2 个 partition,默认情 ...
- spark复习笔记(7):sparkstreaming
一.介绍 1.sparkStreaming是核心模块Spark API的扩展,具有可伸缩,高吞吐量以及容错的实时数据流处理等.数据可以从许多来源(如Kafka,Flume,Kinesis或TCP套接字 ...
- spark复习笔记(7):sparkSQL
一.saprkSQL模块,使用类sql的方式访问Hadoop,实现mr计算,底层使用的是rdd 1.hive //hadoop mr sql 2.phenoix //hbase上构建sql的交互过 ...
- spark复习笔记(3)
在windows上实现wordcount单词统计 一.编写scala程序,引入spark类库,完成wordcount 1.sparkcontextAPI sparkcontext是spark功能的主要 ...
- spark复习笔记(2)
之前工作的时候经常用,隔了段时间,现在学校要用学的东西也忘了,翻翻书谢谢博客吧. 1.什么是spark? Spark是一种快速.通用.可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPL ...
- Spark记录-org.apache.spark.sql.hive.HiveContext与org.apache.spark.sql.SQLContext包api分析
HiveContext/SQLContext val hiveContext=new HiveContext(new SparkContext(new SparkConf().setAppName(& ...
- spark复习笔记(1)
使用spark实现work count ---------------------------------------------------- (1)用sc.textFile(" &quo ...
- spark复习笔记(6):RDD持久化
在spark中最重要的功能之一是跨操作在内存中持久化数据集.当你持久化一个RDD的时候,每个节点都存放了一个它在内存中计算的一个分区,并在该数据集的其他操作中进行重用,持久化一个RDD的时候,节点上的 ...
随机推荐
- 1. svn 简介
参考文档: http://svndoc.iusesvn.com/ SVN的 相关网站 什么是svn?Subversion是一个“集中式”的信息共享系统.版本库是Subversion的核心部分,是数据的 ...
- RMI实现方案
- ASP:CheckBox获取前台的checked的属性
后台代码: for (int i = 0; i < this.GvCourses.Rows.Count; i++) { CheckBox chb = this.GvCourses.Rows[i] ...
- web上传大文件(>4G)有什么解决方案?
众所皆知,web上传大文件,一直是一个痛.上传文件大小限制,页面响应时间超时.这些都是web开发所必须直面的. 本文给出的解决方案是:前端实现数据流分片长传,后面接收完毕后合并文件的思路. 实现文件夹 ...
- Quartus_II官方教程-中文版之SignalTap II
非常实用 187-196 第十二章:调试 Quartus_II官方教程-中文版.pdf
- Vim 编辑器学习笔记
参考资料: 世界上最牛的编辑器: Vim 1
- Java继承和多态-Static关键字
1. 什么是Static 关键字? Static 能够与变量,方法和类一起使用,称为静态变量,静态方法.如果在一个类中使用static修饰变量或者方法的话,它们可以直接通过类访问,不需要创建一个类的对 ...
- 关于MonoBehaviour的单例通用规则
长久以来,对于基于MonoBehaviour的单例总是心有梗结,总觉得用得很忐忑,今天,终于有时间思考和总结了下,理清了想通了.代码和注释如下: 其中GameLogic是我们自己的控制游戏生命周期的管 ...
- Linux内核调试方法总结之Call Trace
内核态call trace 内核态有三种出错情况,分别是bug, oops和panic. bug属于轻微错误,比如在spin_lock期间调用了sleep,导致潜在的死锁问题,等等. oops代表某一 ...
- ASP 解析json
第一个方法是使用 JScript : <script language="jscript" runat="server"> Array.protot ...