四十一 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
elasticsearch(搜索引擎)基本的索引和文档CRUD操作
也就是基本的索引和文档、增、删、改、查、操作
注意:以下操作都是在kibana里操作的
elasticsearch(搜索引擎)都是基于http方法来操作的
GET 请求指定的页面信息,并且返回实体主体
POST 向指定资源提交数据进行处理请求,数据被包含在请求体中,POST请求可能会导致新的资源的建立和/或已有资源的修改
PUT 向服务器传送的数据取代指定的文档的内容
DELETE 请求服务器删除指定的页面
1、索引初始化,相当于创建一个数据库
用kibana创建
代码说明

# 初始化索引(也就是创建数据库)
# PUT 索引名称
"""
PUT jobbole #设置索引名称
{
"settings": { #设置
"index": { #索引
"number_of_shards":5, #设置分片数
"number_of_replicas":1 #设置副本数
}
}
}
"""
代码
# 初始化索引(也就是创建数据库)
# PUT 索引名称 PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
}
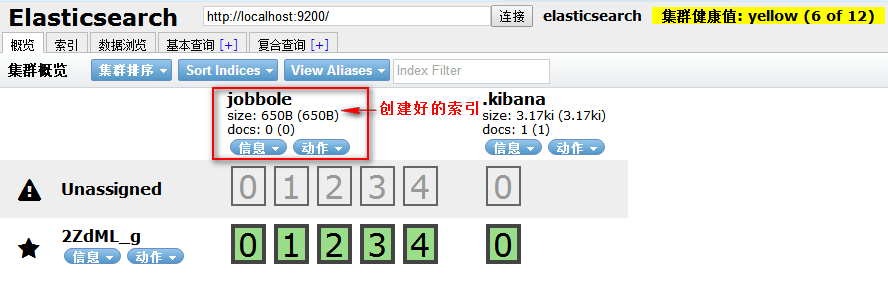
我们也可以使用可视化根据创建索引
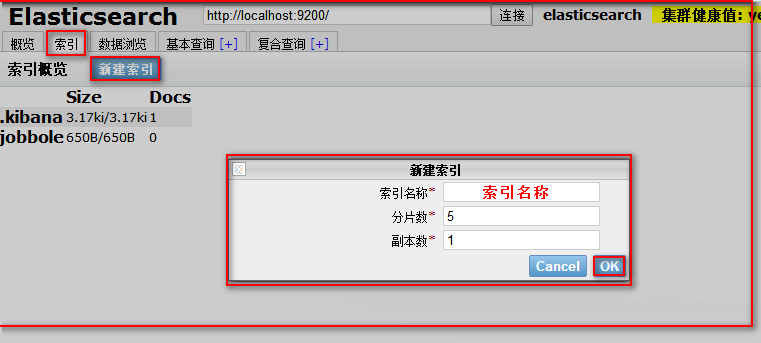
注意:索引一旦创建,分片数量不可修改,副本数量可以修改的
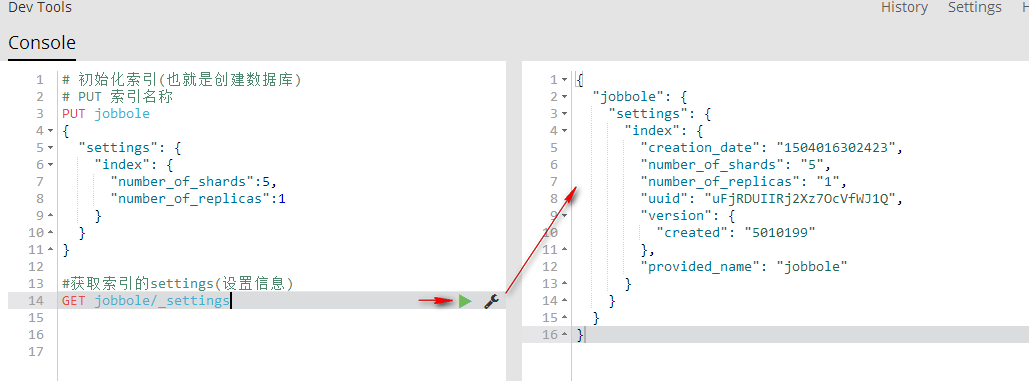
2、获取索引的settings(设置信息)
GET 索引名称/_settings 获取指定索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取指定索引的settings(设置信息)
GET jobbole/_settings
GET _all/_settings 获取所有索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings #获取所有索引的settings(设置信息)
GET _all/_settings
GET .索引名称,索引名称/_settings 获取多个索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings #获取所有索引的settings(设置信息)
#GET _all/_settings
GET .kibana,jobbole/_settings
3、更新索引的settings(设置信息)
PUT 索引名称/_settings 更新指定索引的设置信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
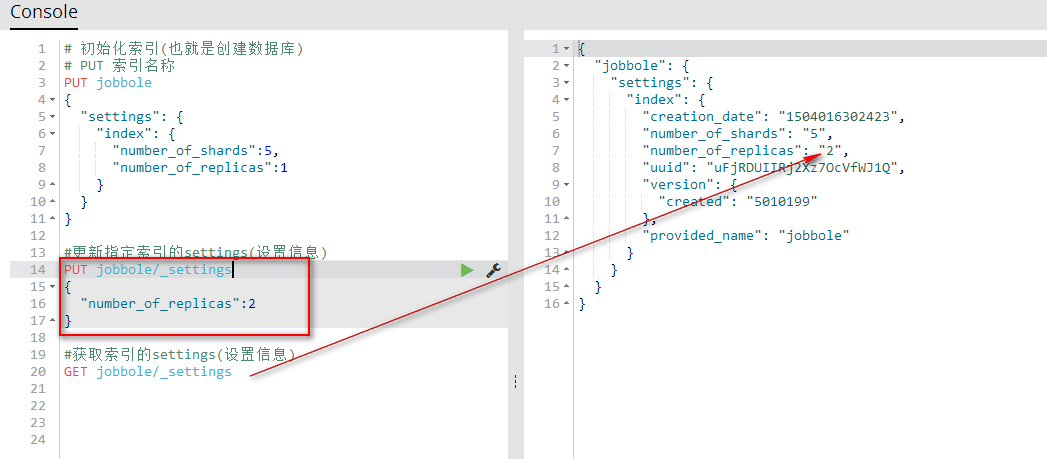
} #更新指定索引的settings(设置信息)
PUT jobbole/_settings
{
"number_of_replicas":2
} #获取索引的settings(设置信息)
GET jobbole/_settings
4、获取索引的(索引信息)
GET _all 获取所有索引的索引信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings GET _all
GET 索引名称 获取指定的索引信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings
#GET _all
GET jobbole
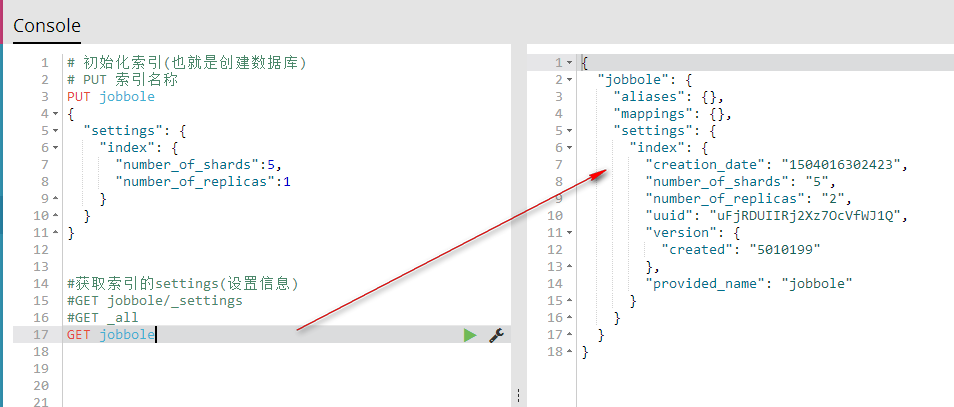
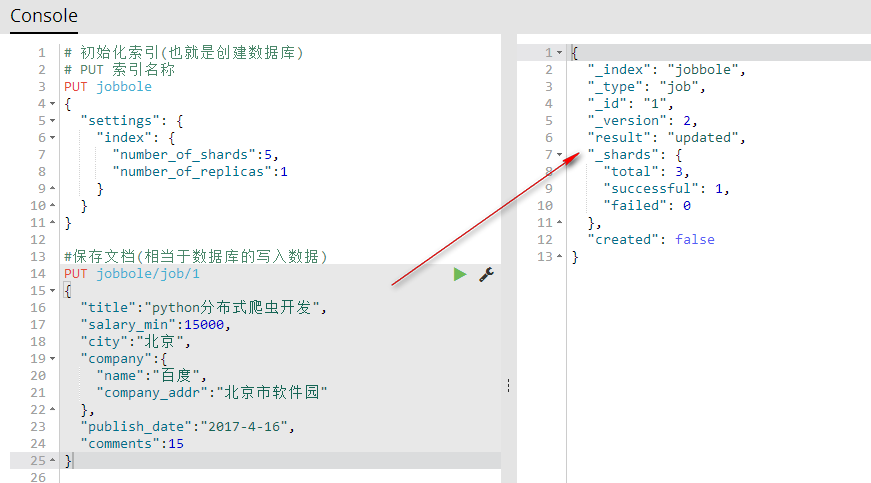
5、保存文档(相当于数据库的写入数据)
PUT index(索引名称)/type(相当于表名称)/1(相当于id){字段:值} 保存文档自定义id(相当于数据库的写入数据)
#保存文档(相当于数据库的写入数据)
PUT jobbole/job/1
{
"title":"python分布式爬虫开发",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园"
},
"publish_date":"2017-4-16",
"comments":15
}
可视化查看

POST index(索引名称)/type(相当于表名称)/{字段:值} 保存文档自动生成id(相当于数据库的写入数据)
注意:自动生成id需要用POST方法
#保存文档(相当于数据库的写入数据)
POST jobbole/job
{
"title":"html开发",
"salary_min":15000,
"city":"上海",
"company":{
"name":"微软",
"company_addr":"上海市软件园"
},
"publish_date":"2017-4-16",
"comments":15
}

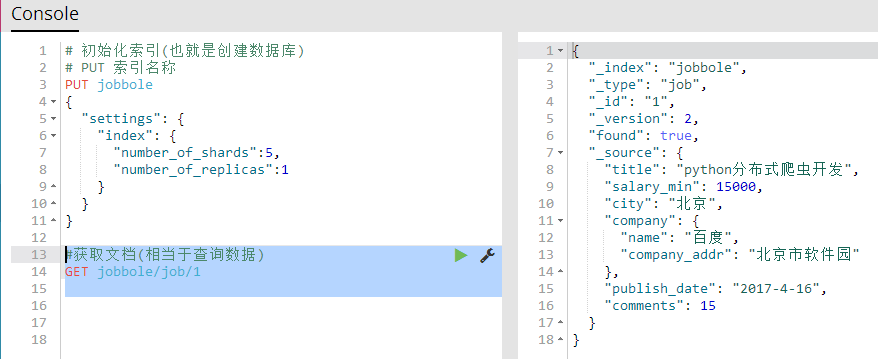
6、获取文档(相当于查询数据)
GET 索引名称/表名称/id 获取指定的文档所有信息
#获取文档(相当于查询数据)
GET jobbole/job/1
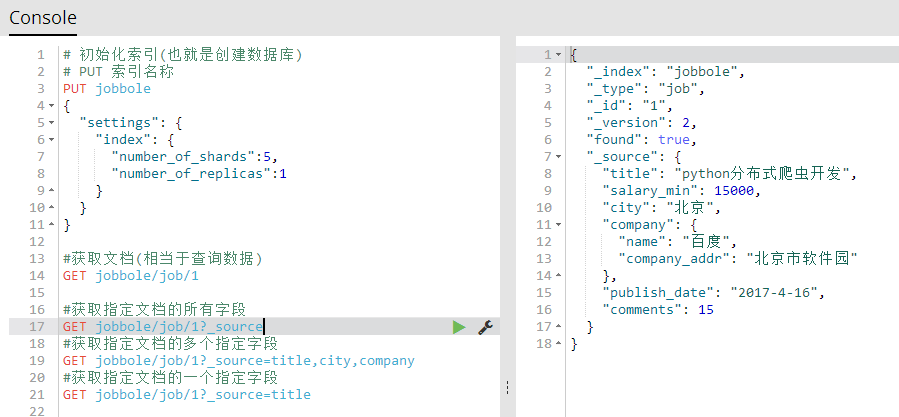
GET 索引名称/表名称/id?_source 获取指定文档的所有字段
GET 索引名称/表名称/id?_source=字段名称,字段名称,字段名称 获取指定文档的多个指定字段
GET 索引名称/表名称/id?_source=字段名称 获取指定文档的一个指定字段
#获取指定文档的所有字段
GET jobbole/job/1?_source
#获取指定文档的多个指定字段
GET jobbole/job/1?_source=title,city,company
#获取指定文档的一个指定字段
GET jobbole/job/1?_source=title
7、修改文档(相当于修改数据)
修改文档(用保存文档的方式,进行覆盖来修改文档)原有数据全部被覆盖
#修改文档(用保存文档的方式,进行覆盖来修改文档)
PUT jobbole/job/1
{
"title":"python分布式爬虫开发",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园"
},
"publish_date":"2017-4-16",
"comments":20
}
修改文档(增量修改,没修改的原数据不变)【推荐】
POST 索引名称/表/id/_update
{
"doc": {
"字段":值,
"字段":值
}
}
#修改文档(增量修改,没修改的原数据不变)
POST jobbole/job/1/_update
{
"doc": {
"comments":20,
"city":"天津"
}
}
8、删除索引,删除文档
DELETE 索引名称/表/id 删除索引里的一个指定文档
DELETE 索引名称 删除一个指定索引
#删除索引里的一个指定文档
DELETE jobbole/job/1
#删除一个指定索引
DELETE jobbole
四十一 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查的更多相关文章
- 第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引
第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引 倒排索引 倒排索引源于实际应用中需要根据属性的值来查找记录.这种索引表中的每一项都包 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 五十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
随机推荐
- position:relative和z-index解决元素边框重合小bug
由于margin-left:-1;导致一边重合造成以上情况. 解决方法:给元素增加position:relative样式,且给选中的样式增加z-index:1;高于其他未选中元素即可解决.
- HTML里引号的输出与显示
关于输入框中显示双引号和单引号 前台显示解决办法: 方法一: 单引号<input type="text" value="'"> 双引号<inp ...
- Mindjet MindManager 出现Runtime Error解决方案
Mindjet MindManager文件打开报错怎么解决?文件打开后提示Runtime Error!Program:C:\Program Files\MindManager 9\Mindmanage ...
- IIS设置文件 App_Offline.htm 网站维护
在ASP.NET 2.0 站点根目录下,只要存在 App_Offline.htm 文件,那么所有对.aspx的请求都将转向App_Offline.htm .而且浏览器的地址栏显示的是所请求的.aspx ...
- 流畅的python 符合python风格的对象
对象表示形式 每门面向对象的语言至少都有一种获取对象的字符串表示形式的标准方式.Python 提供了两种方式. repr() 以便于开发者理解的方式返回对象的字符串表示形式.str() 以便于用户理解 ...
- Django继承
Django目前支持两种不同的继承方式,包括抽象基础类和多表继承. 1.抽象基础类: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 cla ...
- 从零到一创建ionic移动app:创建第一个app
新建一个空项目,让它能够在你的虚拟机/手机上跑起来 第一步 新建工程 ionic start myApp blank 一个简单的Web应用我们已经创建完成了,接下来我们就要做一些部署到移动端之前的 ...
- Kattis - cokolada【水】
Kattis - cokolada[水] 题意 有一个人想吃巧克力,但是巧克力都是按照 2 的幂次的数量包装的,然后他想吃一定数量块的巧克力,然后可以敲碎,每次敲碎都分成两半,比如四块装的分成两块就是 ...
- [转]浅谈Hive vs. HBase 区别在哪里
浅谈Hive vs. HBase 区别在哪里 导读:Apache Hive是一个构建于Hadoop(分布式系统基础架构)顶层的数据仓库,Apache HBase是运行于HDFS顶层的NoSQL(=No ...
- QT5.6.0 鼠标支持
QT5用QPA换了QWS之后,USB鼠标就不知道怎么支持,网上搜啊搜,各种尝试,终于可以了. export TSLIB_ROOT=/mnt/sdcard/tslib export TSLIB_PLUG ...