五十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门

我的搜素简单实现原理
我们可以用js来实现,首先用js获取到输入的搜索词
设置一个数组里存放搜素词,
判断搜索词在数组里是否存在如果存在删除原来的词,重新将新词放在数组最前面
如果不存在直接将新词放在数组最前面即可,然后循环数组显示结果即可
热门搜索
实现原理,当用户搜索一个词时,可以保存到数据库,然后记录搜索次数,
利用redis缓存搜索次数最到的词,过一段时间更新一下缓存
备注:Django结合Scrapy的开源项目可以学习一下
django-dynamic-scraper
https://github.com/holgerd77/django-dynamic-scraper
补充
默认的elasticsearch(搜索引擎)只能搜索1万条数据,在大就会报错了
设置方法
步骤一:
打开项目的索引库地址,将该索引先关闭,否则设置操步骤二无法提交
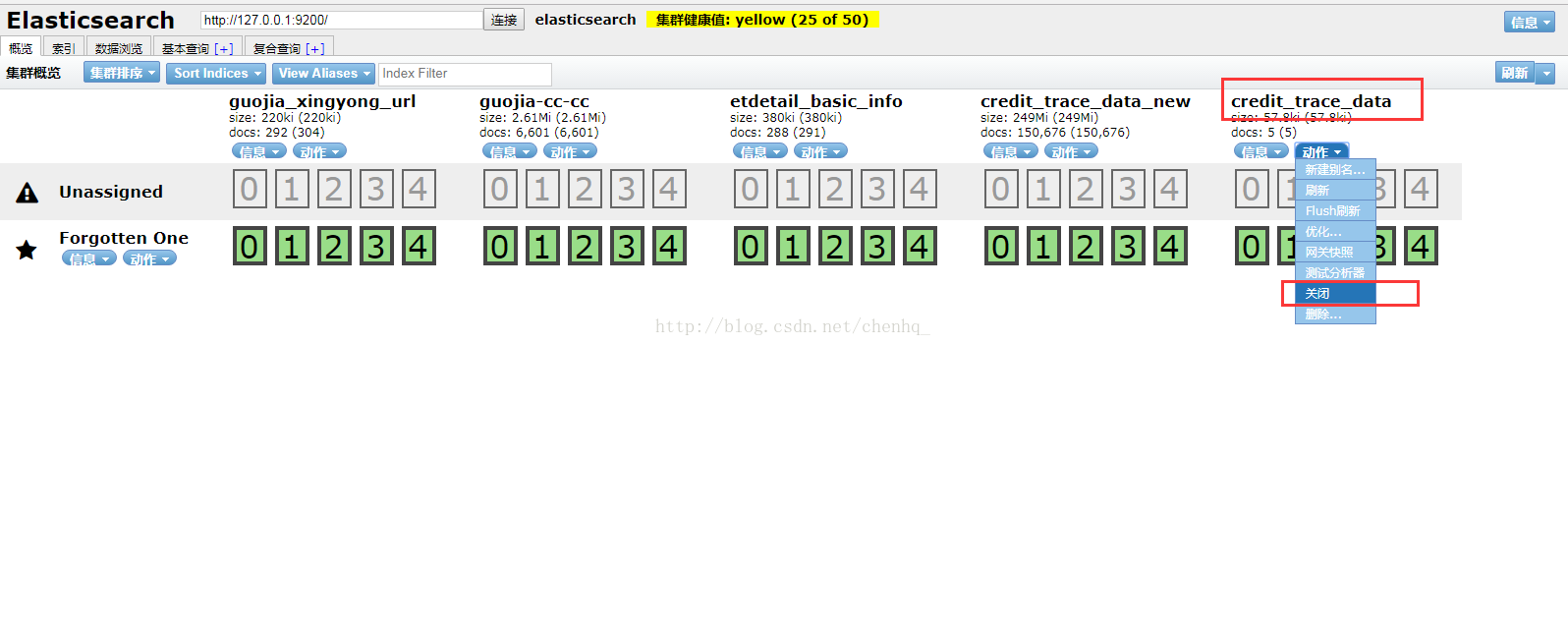
步骤二:
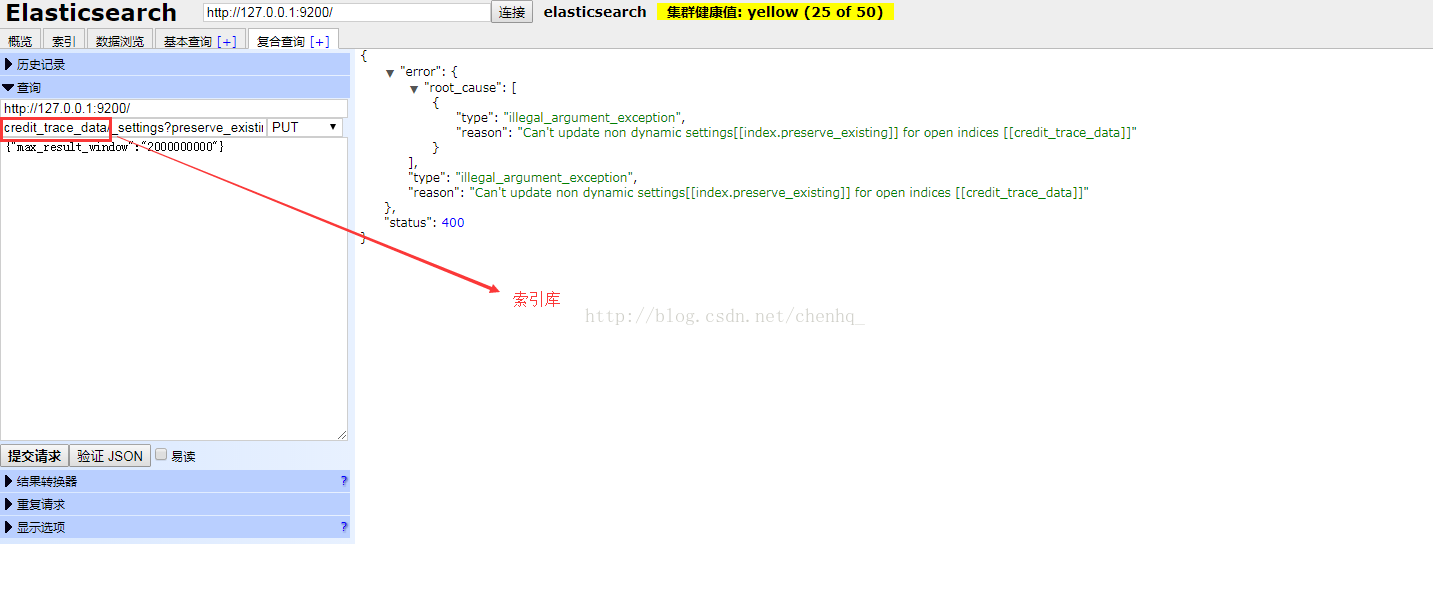
打开复合查询,填入如下信息,记得选择PUT方式提交,credit_trace_data改为本索引库中的索引,max_result_window设为20亿,此值是integer类型,不能无限大
http://127.0.0.1:9200/ PUT
credit_trace_data/_settings?preserve_existing=true
{
"max_result_window" : "2000000000"
}
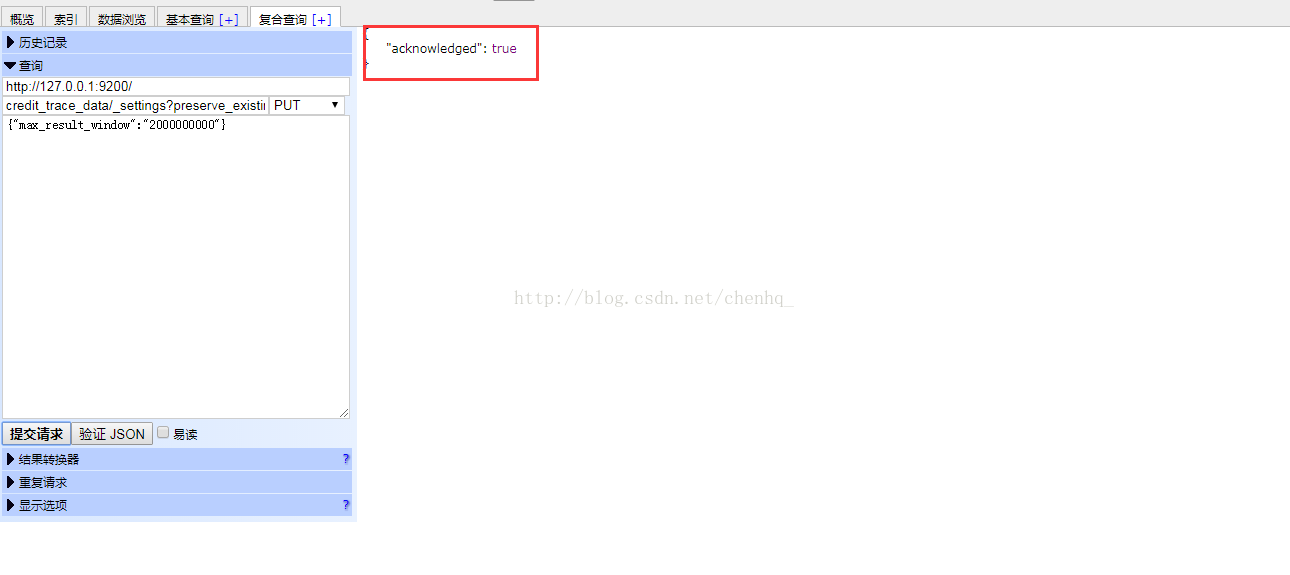
最后点击提交申请,如果配置正确右侧窗口会显示如下信息
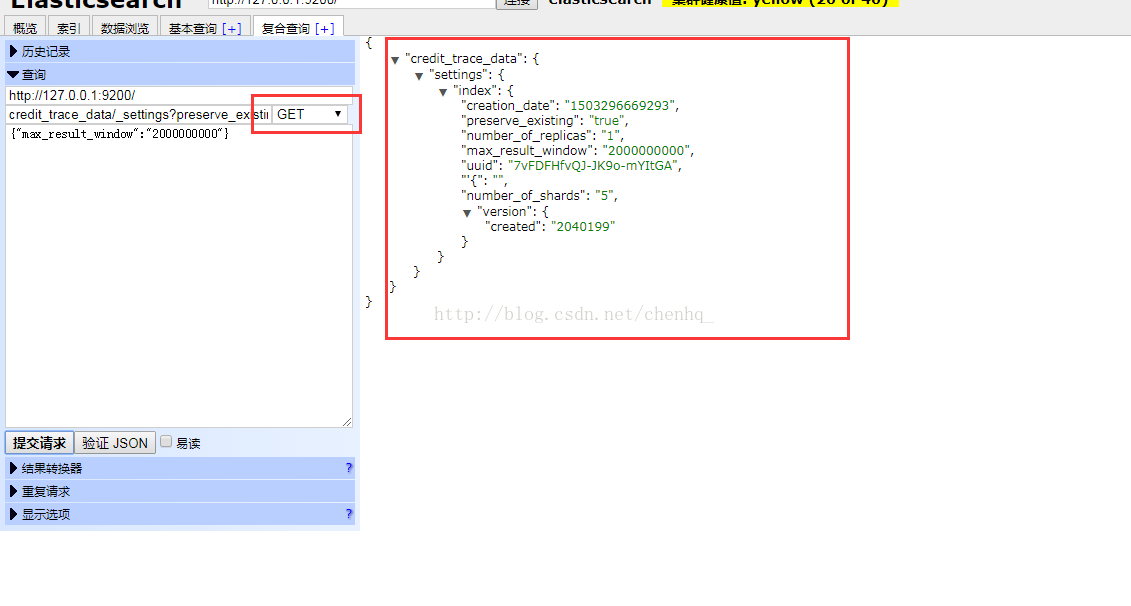
如果要查询max_result_window时只需要将PUT改为get即可
最后记得开启索引!
五十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索的更多相关文章
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
随机推荐
- pycharm的MySQLdb模块导不进去时解决办法
一.Windows下python2.7安装MySQLdb模块 根据Python多少位下载对应版本: 32位:https://pypi.python.org/pypi/MySQL-python/1.2. ...
- how to deal with ^M in linux
change windows file to linux file dos2unix configure https://blog.csdn.net/xiongmaojiayou/article/de ...
- 【我的Android进阶之旅】如何在浏览器上使用Octotree插件树形地展示Github项目代码?
前言 最近有个同事看到我打开Github项目时,浏览器上的展示效果是树形的,于是他问我这个是什么浏览器插件,我告诉他是Octotree插件.现在我就来介绍介绍这款Octotree插件. 效果对比 1. ...
- sql server dba之路
转自:https://blog.csdn.net/dba_huangzj/article/details/7841441 在专职DBA工作一年过一个月以后,开通了CSDN的博客专栏,在第一篇文章中,我 ...
- 解读tensorflow之rnn 的示例 ptb_word_lm.py
这两天想搞清楚用tensorflow来实现rnn/lstm如何做,但是google了半天,发现tf在rnn方面的实现代码或者教程都太少了,仅有的几个教程讲的又过于简单.没办法,只能亲自动手一步步研究官 ...
- use html5 video tag with MSE for h264 live streaming
本编博客记录桌面虚拟化移动端预研. 完整demo: https://github.com/MarkRepo/wfs.js 常见的直播方案有RTMP RTSP HLS 等等, 由于这些流都需要先传输到服 ...
- 图形数据库 Neo4j 开发实战【转载】
简介: Neo4j 是一个高性能的 NoSQL 图形数据库.Neo4j 使用图(graph)相关的概念来描述数据模型,把数据保存为图中的节点以及节点之间的关系.很多应用中数据之间的关系,可以很直接地使 ...
- linux 或c 时间相关处理类型和函数
注意1.精确级别,纳秒级别原型long clock_gettime (clockid_t which_clock, struct timespec *tp); 头文件time.hwhich_cloc ...
- Django-model基础(Day69)
阅读目录 ORM 创建表(建立模型) 添加表记录 查询表记录 F查询与Q查询 修改表记录 删除表记录 数据库回顾:http://www.cnblogs.com/yuanchenqi/articles/ ...
- iOS消息推送原理
推送相关概念,如下图1-1: 1.Provider:就是为指定IOS设备应用程序提供Push的服务器,(如果IOS设备的应用程序是客户端的话,那么Provider可以理解为服务端[消息的发起者]): ...