四十一 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
elasticsearch(搜索引擎)基本的索引和文档CRUD操作
也就是基本的索引和文档、增、删、改、查、操作
注意:以下操作都是在kibana里操作的
elasticsearch(搜索引擎)都是基于http方法来操作的
GET 请求指定的页面信息,并且返回实体主体
POST 向指定资源提交数据进行处理请求,数据被包含在请求体中,POST请求可能会导致新的资源的建立和/或已有资源的修改
PUT 向服务器传送的数据取代指定的文档的内容
DELETE 请求服务器删除指定的页面
1、索引初始化,相当于创建一个数据库
用kibana创建
代码说明

# 初始化索引(也就是创建数据库)
# PUT 索引名称
"""
PUT jobbole #设置索引名称
{
"settings": { #设置
"index": { #索引
"number_of_shards":5, #设置分片数
"number_of_replicas":1 #设置副本数
}
}
}
"""
代码
# 初始化索引(也就是创建数据库)
# PUT 索引名称 PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
}
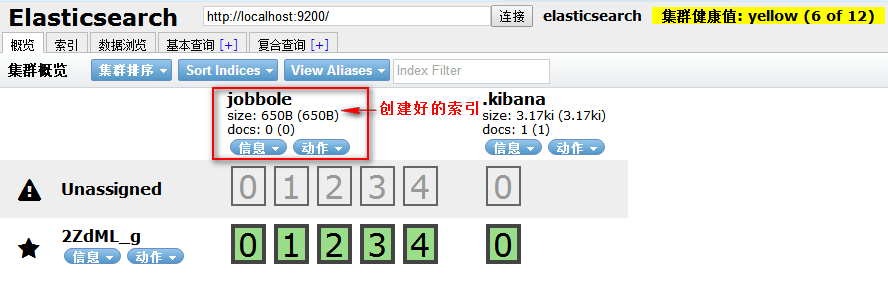
我们也可以使用可视化根据创建索引
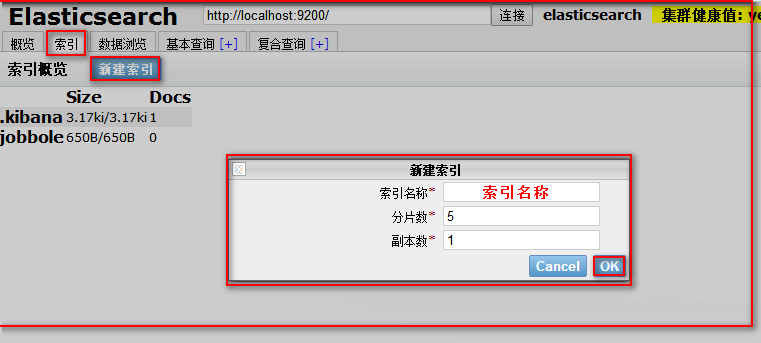
注意:索引一旦创建,分片数量不可修改,副本数量可以修改的
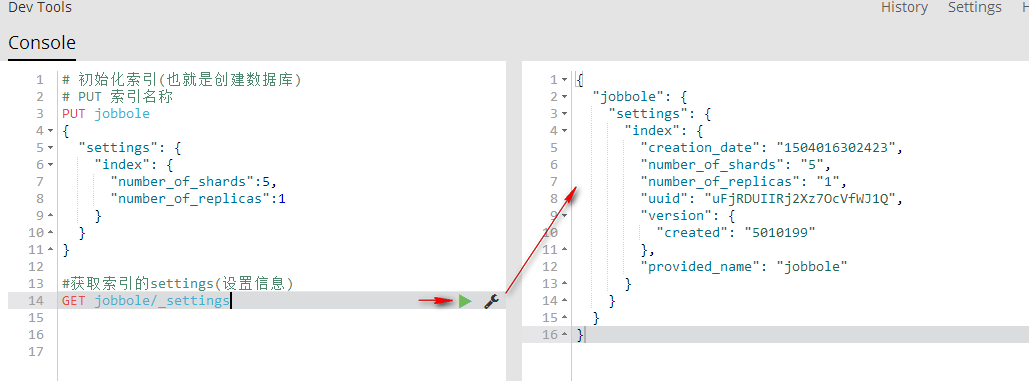
2、获取索引的settings(设置信息)
GET 索引名称/_settings 获取指定索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取指定索引的settings(设置信息)
GET jobbole/_settings
GET _all/_settings 获取所有索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings #获取所有索引的settings(设置信息)
GET _all/_settings
GET .索引名称,索引名称/_settings 获取多个索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings #获取所有索引的settings(设置信息)
#GET _all/_settings
GET .kibana,jobbole/_settings
3、更新索引的settings(设置信息)
PUT 索引名称/_settings 更新指定索引的设置信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
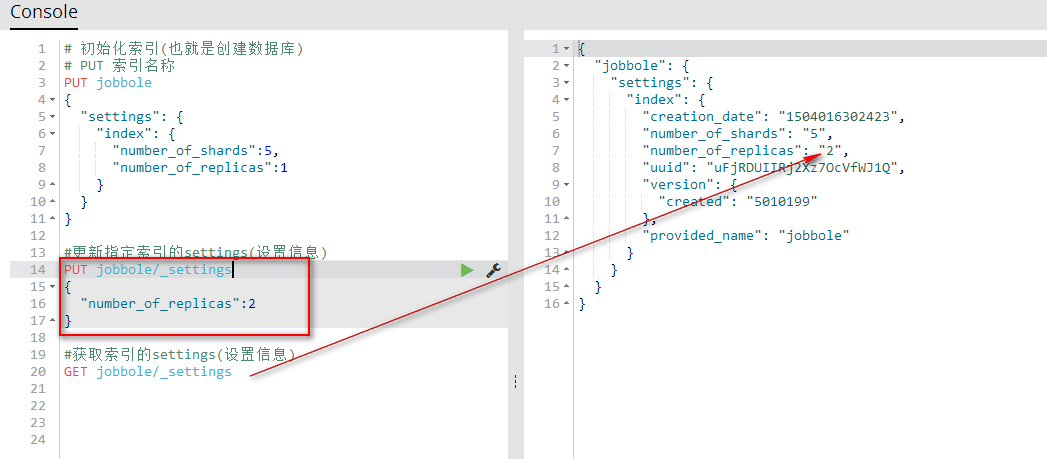
} #更新指定索引的settings(设置信息)
PUT jobbole/_settings
{
"number_of_replicas":2
} #获取索引的settings(设置信息)
GET jobbole/_settings
4、获取索引的(索引信息)
GET _all 获取所有索引的索引信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings GET _all
GET 索引名称 获取指定的索引信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
} #获取索引的settings(设置信息)
#GET jobbole/_settings
#GET _all
GET jobbole
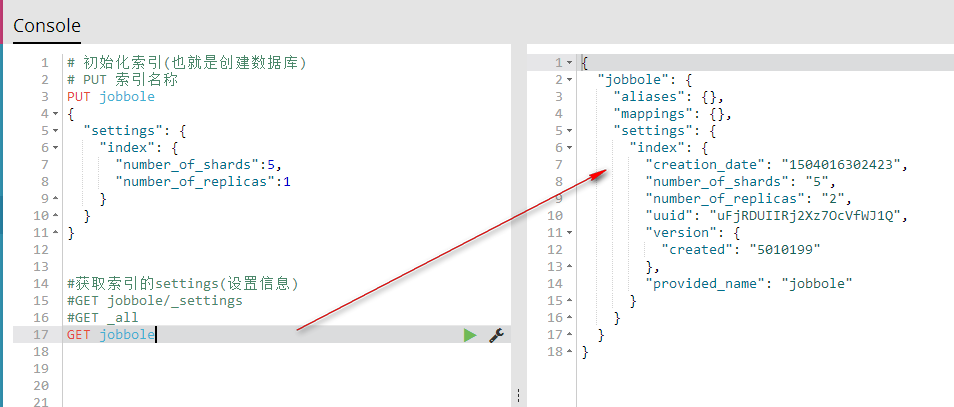
5、保存文档(相当于数据库的写入数据)
PUT index(索引名称)/type(相当于表名称)/1(相当于id){字段:值} 保存文档自定义id(相当于数据库的写入数据)
#保存文档(相当于数据库的写入数据)
PUT jobbole/job/1
{
"title":"python分布式爬虫开发",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园"
},
"publish_date":"2017-4-16",
"comments":15
}
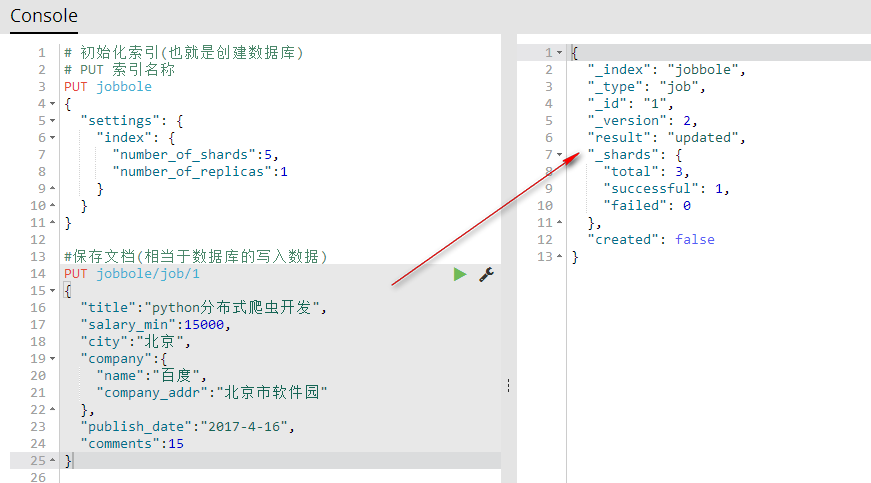
可视化查看

POST index(索引名称)/type(相当于表名称)/{字段:值} 保存文档自动生成id(相当于数据库的写入数据)
注意:自动生成id需要用POST方法
#保存文档(相当于数据库的写入数据)
POST jobbole/job
{
"title":"html开发",
"salary_min":15000,
"city":"上海",
"company":{
"name":"微软",
"company_addr":"上海市软件园"
},
"publish_date":"2017-4-16",
"comments":15
}

6、获取文档(相当于查询数据)
GET 索引名称/表名称/id 获取指定的文档所有信息
#获取文档(相当于查询数据)
GET jobbole/job/1
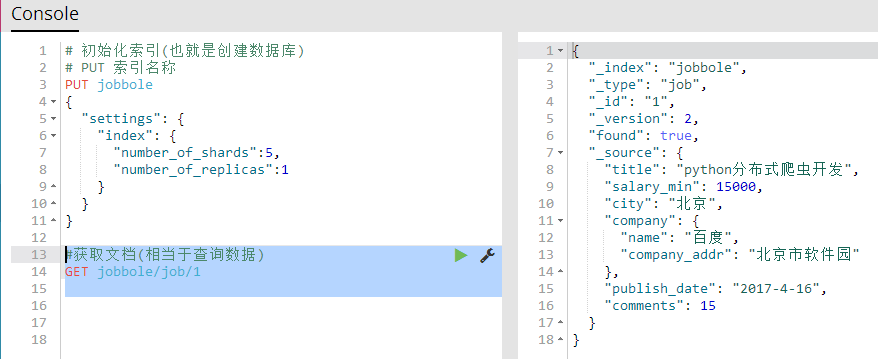
GET 索引名称/表名称/id?_source 获取指定文档的所有字段
GET 索引名称/表名称/id?_source=字段名称,字段名称,字段名称 获取指定文档的多个指定字段
GET 索引名称/表名称/id?_source=字段名称 获取指定文档的一个指定字段
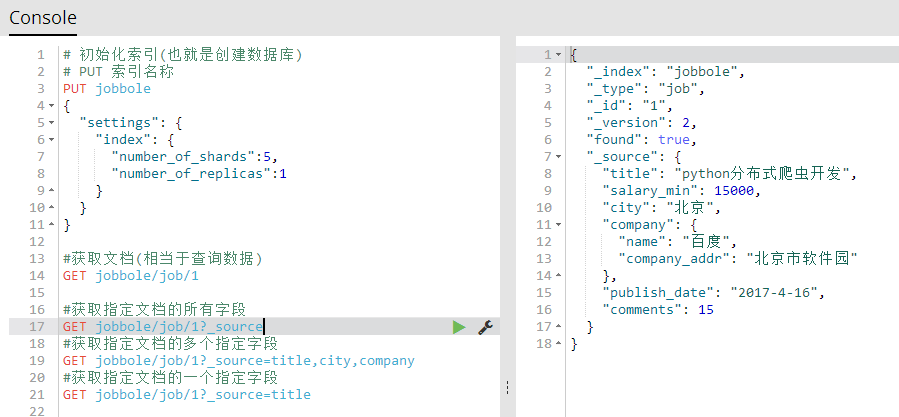
#获取指定文档的所有字段
GET jobbole/job/1?_source
#获取指定文档的多个指定字段
GET jobbole/job/1?_source=title,city,company
#获取指定文档的一个指定字段
GET jobbole/job/1?_source=title
7、修改文档(相当于修改数据)
修改文档(用保存文档的方式,进行覆盖来修改文档)原有数据全部被覆盖
#修改文档(用保存文档的方式,进行覆盖来修改文档)
PUT jobbole/job/1
{
"title":"python分布式爬虫开发",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园"
},
"publish_date":"2017-4-16",
"comments":20
}
修改文档(增量修改,没修改的原数据不变)【推荐】
POST 索引名称/表/id/_update
{
"doc": {
"字段":值,
"字段":值
}
}
#修改文档(增量修改,没修改的原数据不变)
POST jobbole/job/1/_update
{
"doc": {
"comments":20,
"city":"天津"
}
}
8、删除索引,删除文档
DELETE 索引名称/表/id 删除索引里的一个指定文档
DELETE 索引名称 删除一个指定索引
#删除索引里的一个指定文档
DELETE jobbole/job/1
#删除一个指定索引
DELETE jobbole
四十一 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查的更多相关文章
- 第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引
第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引 倒排索引 倒排索引源于实际应用中需要根据属性的值来查找记录.这种索引表中的每一项都包 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 五十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
随机推荐
- 初识python(二)
初识python(二) 1.变量 变量:把程序运行的中间结果临时的存在内存里,以便后续的代码调用. 1.1 声明变量: #!/usr/bin/env python # -*- coding: utf- ...
- oracle入门(2)—— 使用图形工具navicat for oracle
[本文介绍] 本文将介绍如何使用图形工具navicat for oracle连接本地数据库 以及远程访问 服务器数据库. [下载地址] http://www.navicat.com.cn/downlo ...
- Linux常用命令(更新)
- 基于WinIO 3.0实现驱动级键盘模拟输入
基于WinIO 3.0实现驱动级键盘模拟输入 一个业务场景需要使用驱动级的键盘模拟,折腾了2天,总结一下,为后人节省时间. 限制条件: 1.需要真实PC机,虚拟机不行 2.仅支持PS/2 键盘(指外接 ...
- springmvc RequestParam、RequestHeader
/** * 了解: * * @CookieValue: 映射一个 Cookie 值. 属性同 @RequestParam */ @RequestMapping("/testCookieVal ...
- HDU - 6336 Problem E. Matrix from Arrays (规律+二维前缀和)
题意: for (int i = 0; ; ++i) { for (int j = 0; j <= i; ++j) { M[j][i - j] = A[cursor]; cursor = (cu ...
- HDFS JAVA API介绍
注:在工程pom.xml 所在目录,cmd中运行 mvn package ,打包可能会有两个jar,名字较长的是包含所有依赖的重量级的jar,可以在linux中使用 java -cp 命令来跑.名字较 ...
- strtok()函数、fseek()函数、fwrite()函数、fread()函数的使用
在电子词典这个项目过程中遇到了几个主要的问题,第一个是怎么解决把翻译分开这个.第二个事情就是怎么把结构体写到文件中.这两个问题,一个是关于字符串的操作一个是关于文件的操作. strtok函数 char ...
- Windows10安装mysql数据库
安装以及配置,参考下面链接 https://www.cnblogs.com/qjoanven/p/7898006.html 碰到的问题: 1. 安装的时候出现 mysql Install/Remove ...
- 20165101刘天野 2018-2019-2《网络对抗技术》Exp5 MSF基础应用
目录 20165101刘天野 2018-2019-2<网络对抗技术>Exp5 MSF基础应用 1. 实践内容 1.1一个主动攻击实践,如ms08_067; (1分) 1.2 一个针对浏览器 ...