Spark Idea Maven 开发环境搭建
一、安装jdk
jdk版本最好是1.7以上,设置好环境变量,安装过程,略。
二、安装Maven
我选择的Maven版本是3.3.3,安装过程,略。
编辑Maven安装目录conf/settings.xml文件,
<!-- 修改Maven 库存放目录-->
<localRepository>D:\maven-repository\repository</localRepository>
三、安装Idea
安装过程,略。
四、创建Spark项目
1、新建一个Spark项目,
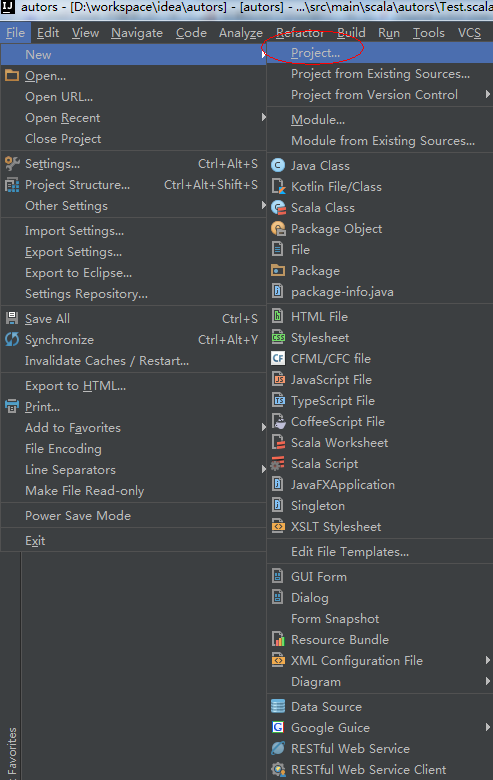
2、选择Maven,从模板创建项目,

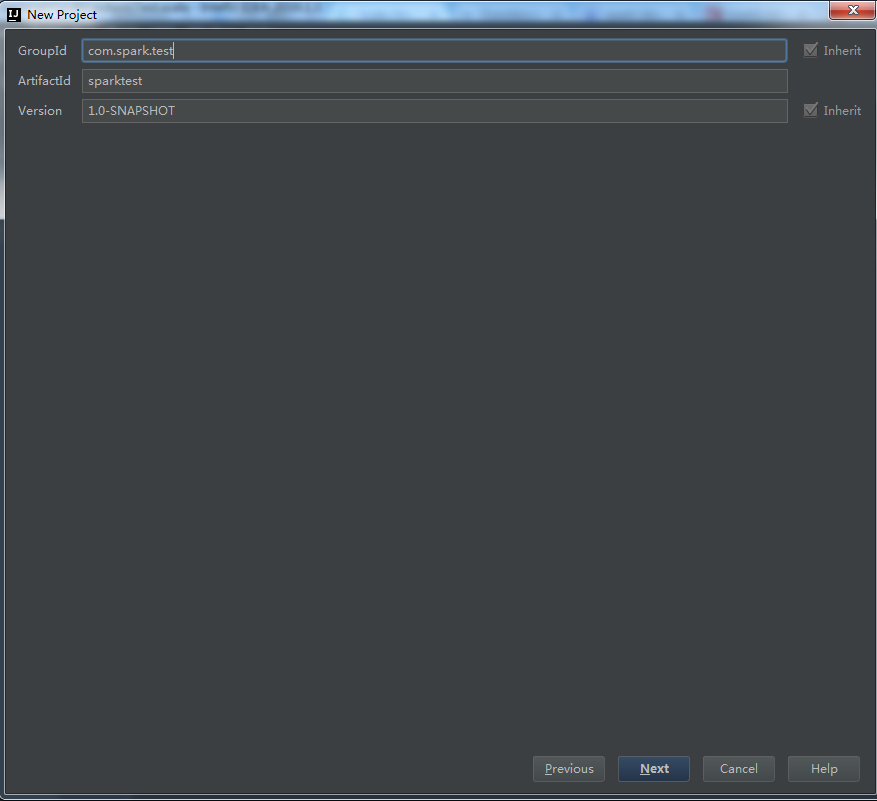
3、填写项目GroupId等,
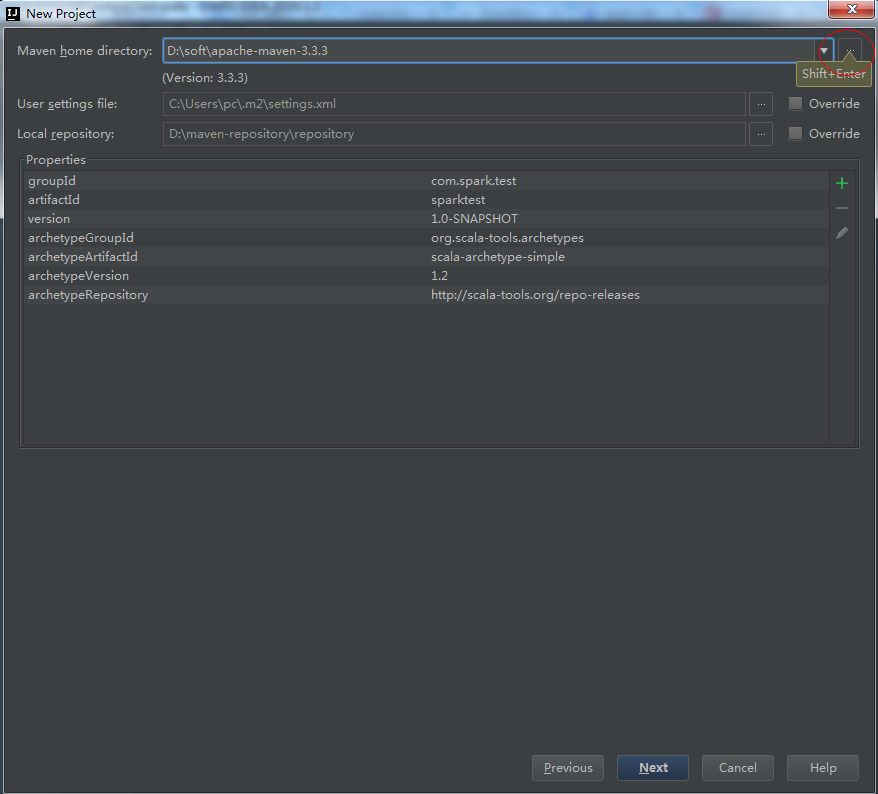
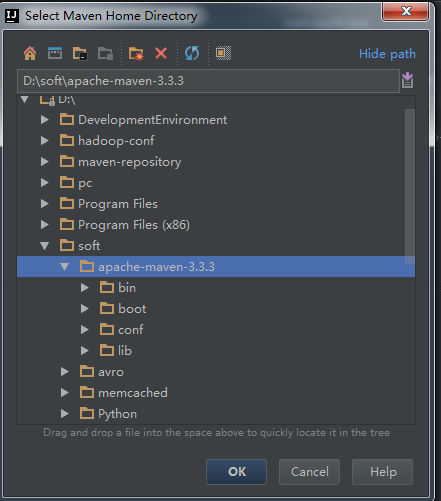
4、选择本地安装的Maven和Maven配置文件。
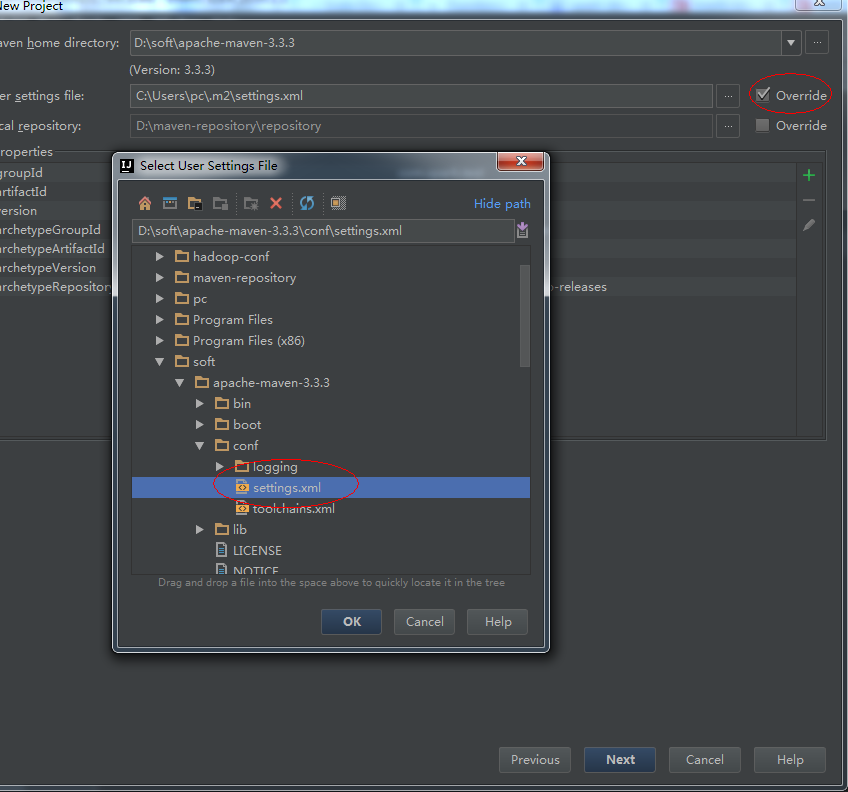
5、next
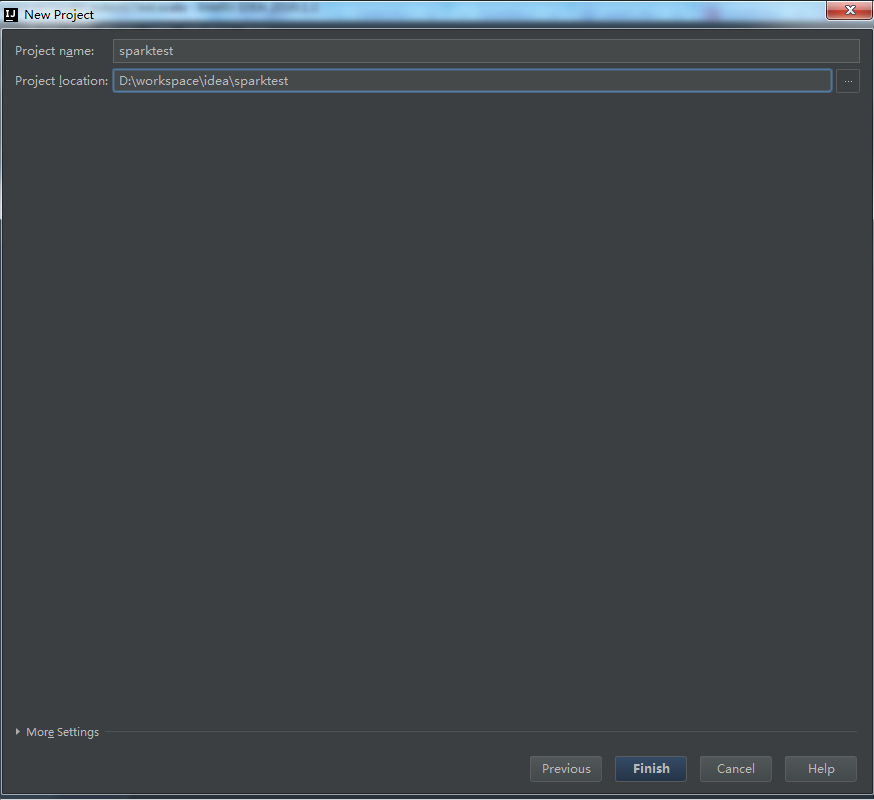
6、创建完毕,查看新项目结构:
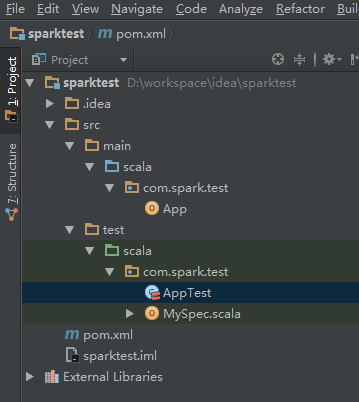
7、自动更新Maven pom文件
8、编译项目
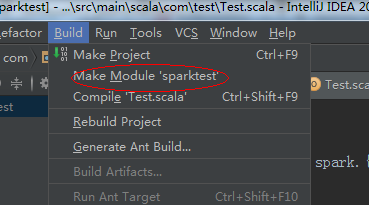
如果出现这种错误,这个错误是由于Junit版本造成的,可以删掉Test,和pom.xml文件中Junit的相关依赖,
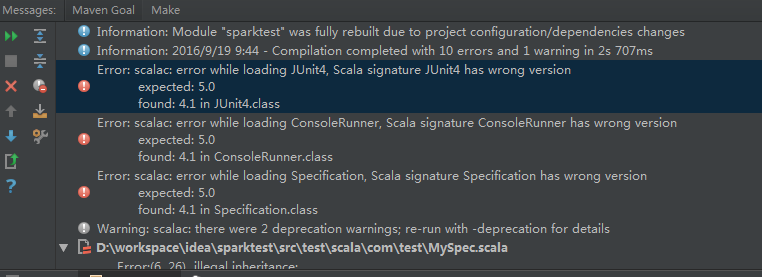
即删掉这两个Scala类:

和pom.xml文件中的Junit依赖:
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
9、刷新Maven依赖

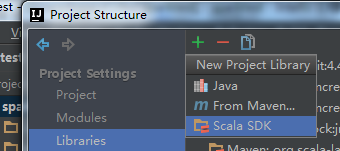
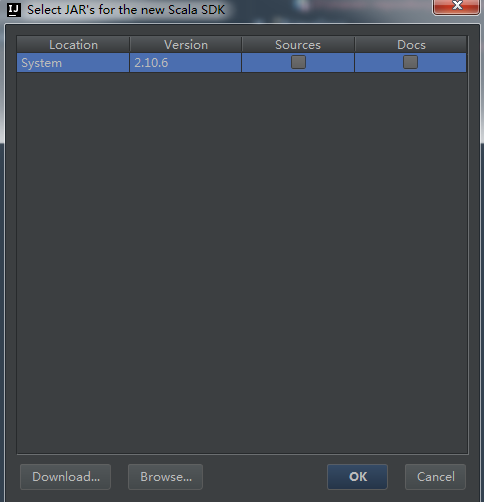
10、引入Jdk和Scala开发库
11、在pom.xml加入相关的依赖包,包括Hadoop、Spark等
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.1</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.1</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.9</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.1</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.5.1</version>
</dependency>
然后刷新maven的依赖,
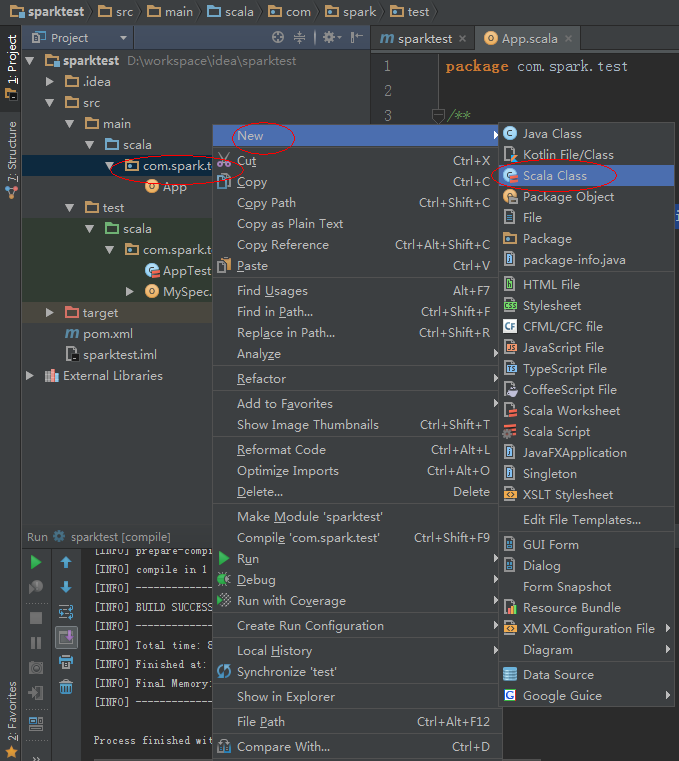
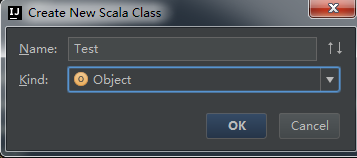
12、新建一个Scala Object。
测试代码为:
def main(args: Array[String]) {
println("Hello World!")
val sparkConf = new SparkConf().setMaster("local").setAppName("test")
val sparkContext = new SparkContext(sparkConf)
}
执行,
如果报了以下错误,
java.lang.SecurityException: class "javax.servlet.FilterRegistration"'s signer information does not match signer information of other classes in the same package
at java.lang.ClassLoader.checkCerts(ClassLoader.java:952)
at java.lang.ClassLoader.preDefineClass(ClassLoader.java:666)
at java.lang.ClassLoader.defineClass(ClassLoader.java:794)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
at java.net.URLClassLoader.access$100(URLClassLoader.java:71)
at java.net.URLClassLoader$1.run(URLClassLoader.java:361)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at org.spark-project.jetty.servlet.ServletContextHandler.<init>(ServletContextHandler.java:136)
at org.spark-project.jetty.servlet.ServletContextHandler.<init>(ServletContextHandler.java:129)
at org.spark-project.jetty.servlet.ServletContextHandler.<init>(ServletContextHandler.java:98)
at org.apache.spark.ui.JettyUtils$.createServletHandler(JettyUtils.scala:110)
at org.apache.spark.ui.JettyUtils$.createServletHandler(JettyUtils.scala:101)
at org.apache.spark.ui.WebUI.attachPage(WebUI.scala:78)
at org.apache.spark.ui.WebUI$$anonfun$attachTab$1.apply(WebUI.scala:62)
at org.apache.spark.ui.WebUI$$anonfun$attachTab$1.apply(WebUI.scala:62)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.spark.ui.WebUI.attachTab(WebUI.scala:62)
at org.apache.spark.ui.SparkUI.initialize(SparkUI.scala:61)
at org.apache.spark.ui.SparkUI.<init>(SparkUI.scala:74)
at org.apache.spark.ui.SparkUI$.create(SparkUI.scala:190)
at org.apache.spark.ui.SparkUI$.createLiveUI(SparkUI.scala:141)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:466)
at com.test.Test$.main(Test.scala:13)
at com.test.Test.main(Test.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
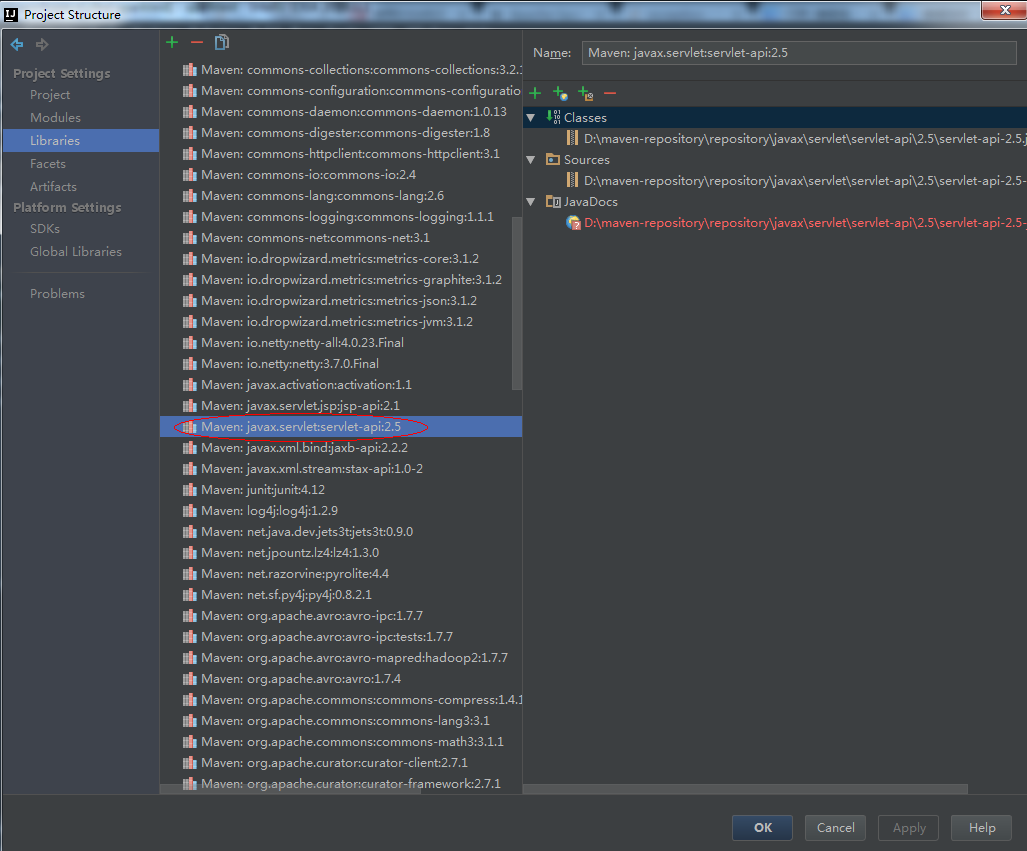
可以把servlet-api 2.5 jar删除即可:
最好的办法是删除pom.xml中相关的依赖,即
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
最后的pom.xml文件的依赖是
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.1</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.5.1</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>1.5.1</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.5.2</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>1.5.2</version>
</dependency> <dependency>
<groupId>com.databricks</groupId>
<artifactId>spark-avro_2.10</artifactId>
<version>2.0.1</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.5.2</version>
</dependency> </dependencies>
如果是报了这个错误,也没有什么问题,程序依旧可以执行,
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:356)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:371)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:364)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:80)
at org.apache.hadoop.security.SecurityUtil.getAuthenticationMethod(SecurityUtil.java:611)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:272)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:260)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:790)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:760)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:633)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2084)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2084)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2084)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:311)
at com.test.Test$.main(Test.scala:13)
at com.test.Test.main(Test.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
最后看到的正常输出:
Hello World!
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
16/09/19 11:21:29 INFO SparkContext: Running Spark version 1.5.1
16/09/19 11:21:29 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:356)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:371)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:364)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:80)
at org.apache.hadoop.security.SecurityUtil.getAuthenticationMethod(SecurityUtil.java:611)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:272)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:260)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:790)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:760)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:633)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2084)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2084)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2084)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:311)
at com.test.Test$.main(Test.scala:13)
at com.test.Test.main(Test.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
16/09/19 11:21:29 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/09/19 11:21:30 INFO SecurityManager: Changing view acls to: pc
16/09/19 11:21:30 INFO SecurityManager: Changing modify acls to: pc
16/09/19 11:21:30 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(pc); users with modify permissions: Set(pc)
16/09/19 11:21:30 INFO Slf4jLogger: Slf4jLogger started
16/09/19 11:21:31 INFO Remoting: Starting remoting
16/09/19 11:21:31 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.51.143:52500]
16/09/19 11:21:31 INFO Utils: Successfully started service 'sparkDriver' on port 52500.
16/09/19 11:21:31 INFO SparkEnv: Registering MapOutputTracker
16/09/19 11:21:31 INFO SparkEnv: Registering BlockManagerMaster
16/09/19 11:21:31 INFO DiskBlockManager: Created local directory at C:\Users\pc\AppData\Local\Temp\blockmgr-f9ea7f8c-68f9-4f9b-a31e-b87ec2e702a4
16/09/19 11:21:31 INFO MemoryStore: MemoryStore started with capacity 966.9 MB
16/09/19 11:21:31 INFO HttpFileServer: HTTP File server directory is C:\Users\pc\AppData\Local\Temp\spark-64cccfb4-46c8-4266-92c1-14cfc6aa2cb3\httpd-5993f955-0d92-4233-b366-c9a94f7122bc
16/09/19 11:21:31 INFO HttpServer: Starting HTTP Server
16/09/19 11:21:31 INFO Utils: Successfully started service 'HTTP file server' on port 52501.
16/09/19 11:21:31 INFO SparkEnv: Registering OutputCommitCoordinator
16/09/19 11:21:31 INFO Utils: Successfully started service 'SparkUI' on port 4040.
16/09/19 11:21:31 INFO SparkUI: Started SparkUI at http://192.168.51.143:4040
16/09/19 11:21:31 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
16/09/19 11:21:31 INFO Executor: Starting executor ID driver on host localhost
16/09/19 11:21:31 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 52520.
16/09/19 11:21:31 INFO NettyBlockTransferService: Server created on 52520
16/09/19 11:21:31 INFO BlockManagerMaster: Trying to register BlockManager
16/09/19 11:21:31 INFO BlockManagerMasterEndpoint: Registering block manager localhost:52520 with 966.9 MB RAM, BlockManagerId(driver, localhost, 52520)
16/09/19 11:21:31 INFO BlockManagerMaster: Registered BlockManager
16/09/19 11:21:31 INFO SparkContext: Invoking stop() from shutdown hook
16/09/19 11:21:32 INFO SparkUI: Stopped Spark web UI at http://192.168.51.143:4040
16/09/19 11:21:32 INFO DAGScheduler: Stopping DAGScheduler
16/09/19 11:21:32 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
16/09/19 11:21:32 INFO MemoryStore: MemoryStore cleared
16/09/19 11:21:32 INFO BlockManager: BlockManager stopped
16/09/19 11:21:32 INFO BlockManagerMaster: BlockManagerMaster stopped
16/09/19 11:21:32 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
16/09/19 11:21:32 INFO SparkContext: Successfully stopped SparkContext
16/09/19 11:21:32 INFO ShutdownHookManager: Shutdown hook called
16/09/19 11:21:32 INFO ShutdownHookManager: Deleting directory C:\Users\pc\AppData\Local\Temp\spark-64cccfb4-46c8-4266-92c1-14cfc6aa2cb3 Process finished with exit code 0
至此,开发环境搭建完毕。
五、打jar包
1、新建一个Scala Object
代码是:
package com.test
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by pc on 2016/9/20.
*/
object WorldCount {
def main(args: Array[String]) {
val dataFile = args(0)
val output = args(1)
val sparkConf = new SparkConf().setAppName("WorldCount")
val sparkContext = new SparkContext(sparkConf)
val lines = sparkContext.textFile(dataFile)
val counts = lines.flatMap(_.split(",")).map(s => (s,1)).reduceByKey((a,b) => a+b)
counts.saveAsTextFile(output)
sparkContext.stop()
}
}
2、 File -》Project Structure
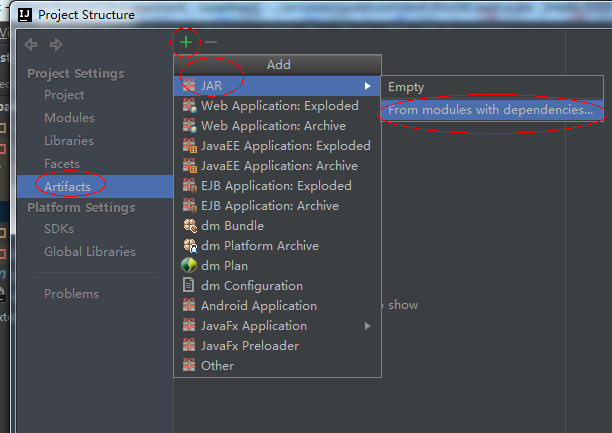
3、点击ok
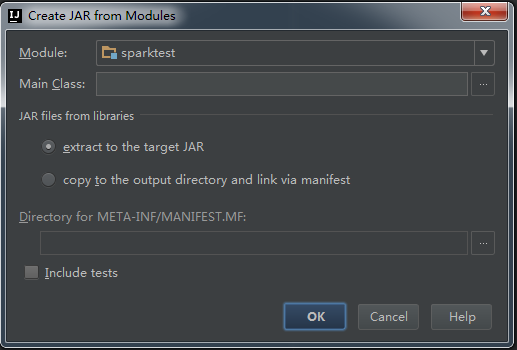
可以设置jar包输出目录:
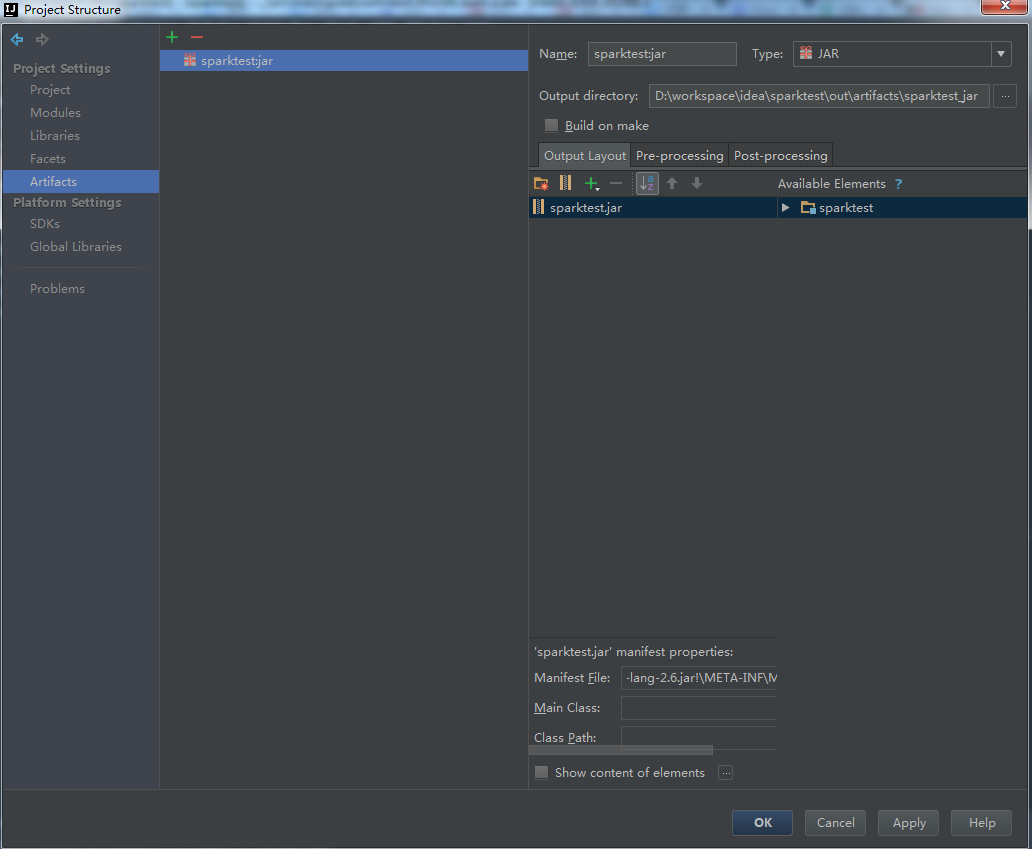
4、build Artifact
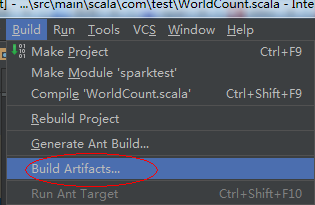
5、运行:
把测试文件放到HDFS的/test/ 目录下,提交:
spark-submit --class com.test.WorldCount --master spark://192.168.18.151:7077 sparktest.jar /test/data.txt /test/test-01
6、如果出现以下错误
Exception in thread "main" java.lang.SecurityException: Invalid signature file digest for Manifest main attributes
at sun.security.util.SignatureFileVerifier.processImpl(SignatureFileVerifier.java:240)
at sun.security.util.SignatureFileVerifier.process(SignatureFileVerifier.java:193)
at java.util.jar.JarVerifier.processEntry(JarVerifier.java:305)
at java.util.jar.JarVerifier.update(JarVerifier.java:216)
at java.util.jar.JarFile.initializeVerifier(JarFile.java:345)
at java.util.jar.JarFile.getInputStream(JarFile.java:412)
at sun.misc.JarIndex.getJarIndex(JarIndex.java:137)
at sun.misc.URLClassPath$JarLoader$1.run(URLClassPath.java:674)
at sun.misc.URLClassPath$JarLoader$1.run(URLClassPath.java:666)
at java.security.AccessController.doPrivileged(Native Method)
at sun.misc.URLClassPath$JarLoader.ensureOpen(URLClassPath.java:665)
at sun.misc.URLClassPath$JarLoader.<init>(URLClassPath.java:638)
at sun.misc.URLClassPath$3.run(URLClassPath.java:366)
at sun.misc.URLClassPath$3.run(URLClassPath.java:356)
at java.security.AccessController.doPrivileged(Native Method)
at sun.misc.URLClassPath.getLoader(URLClassPath.java:355)
at sun.misc.URLClassPath.getLoader(URLClassPath.java:332)
at sun.misc.URLClassPath.getResource(URLClassPath.java:198)
at java.net.URLClassLoader$1.run(URLClassLoader.java:358)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:270)
at org.apache.spark.util.Utils$.classForName(Utils.scala:173)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:641)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:205)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:120)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
就使用WinRAR打开jar包, 删除META-INF目录下的除了mainfest.mf,.rsa及maven目录以外的其他所有文件
Spark Idea Maven 开发环境搭建的更多相关文章
- Spark2.2,IDEA,Maven开发环境搭建附测试
前言: 停滞了一段时间,现在要沉下心来学习点东西,出点货了. 本文没有JavaJDK ScalaSDK和 IDEA的安装过程,网络上会有很多文章介绍这个内容,因此这里就不再赘述. 一.在IDEA上安装 ...
- spark Intellij IDEA开发环境搭建
(1)创建Scala项目 File->new->Project,如下图 选择Scala 然后next 其中Project SDK指定安装的JDK,Scala SDK指定安装的Scala(这 ...
- Scala java maven开发环境搭建
基于maven配置的scala开发环境,首先需要安装 idea 的scala plugin.然后就可以使用maven编译scala程序了.一般情况下都是java scala的混合,所以src下 ...
- Eclipse+maven开发环境搭建
版本描述: Eclipse 3.2.2 Maven 2.0.7 Jdk 1.5以上,本例是在jdk1.50版本测试通过 Maven配置过程 Maven官方下载地址:http://www.apache. ...
- Maven开发环境搭建
配置Maven流程: 1.下载Maven,官网:http://maven.apache.org/ 2.安装到本地: 1 ).解压apache-maven-x.x.x-bin.zip文件 2 ).配置M ...
- Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例【附详细代码】
http://blog.csdn.net/xiefu5hh/article/details/51707529 Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例[附 ...
- spark JAVA 开发环境搭建及远程调试
spark JAVA 开发环境搭建及远程调试 以后要在项目中使用Spark 用户昵称文本做一下聚类分析,找出一些违规的昵称信息.以前折腾过Hadoop,于是看了下Spark官网的文档以及 github ...
- Centos 基础开发环境搭建之Maven私服nexus
hmaster 安装nexus及启动方式 /usr/local/nexus-2.6.3-01/bin ./nexus status Centos 基础开发环境搭建之Maven私服nexus . 软件 ...
- Hadoop项目开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话 可详细参考,一定得去看 HBase 开发环境搭建(Eclipse\MyEclipse + Maven) Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Mav ...
随机推荐
- Java语言的多态性
用简单的话来描述Java:编译类型与运行类型不一致的时候就会出现多态! 下面一段代码可以用来描述Java多态 class BaseClass{ public String flag="父类的 ...
- Mark一下,一上午就这么过去了,关于客户端连接oracle10G的问题
Mark一下,一上午就这么过去了,关于客户端连接oracle10G的问题 正常的客户端PLSQL和Navicat都可以正常连接Oracle(局域网内),但代码生成器和VS2015死活连不上,在网上找了 ...
- 数据库最大连接池max pool size
本文导读:Max Pool Size如果未设置则默认为100,理论最大值为32767.最大连接数是连接池能申请的最大连接数,如果数据库连接请求超过此数,后面的数据库连接请求将被加入到等待队列中,这会影 ...
- echo、print、sprint、sprintf输出
echo() 函数 定义和用法 echo() 函数输出一个或多个字符串. 语法 echo(strings) 参数 描述 strings 必需.一个或多个要发送到输出的字符串. 提示和注释 注释:ech ...
- A Brief Introduction to Markovs Chains
本文译自A Brief Introduction to Markovs Chains 译者按: 前面一篇文章讲的是蒙特卡洛积分,也就是通过生成符合特定分布的随机变量来近似计算积分值,例如: \(E = ...
- OC 中 类目、延展和协议
Category : 也叫分类,类目. *是 为没有源代码的类 扩充功能 *扩充的功能会成为原有类的一部分,可以通过原有类或者原有类的对象直接调用,并且可继承 *该方法只能扩充方法,不能扩充实例变量 ...
- 修改MySQL用户的密码
=====知道当前用户密码时===== P.S.:此文只针对windows下的用户密码更改. 1.使用进入MySQL的bin文件夹下: cd path\to\bin\mysqladmin.exe 2. ...
- java common-io jar API
import org.apache.commons.beanutils.BeanUtils;public class Person { private String name; public Stri ...
- protobuf 数据解析的2种方法
方法1: message person{required int32 age = 1;required int32 userid = 2;optional string name = 3;} mess ...
- 20151214下拉列表:DropDownList
注意: .如果用事件的话就要把控件的AutoPostBack设置成true .防止网页刷新用一个判断 if (!IsPostBack)//判断是第一个开始还是取的返回值 { } 下拉列表:DropDo ...