sklearn模型的属性与功能-【老鱼学sklearn】
本节主要讲述模型中的各种属性及其含义。
例如上个博文中,我们有用线性回归模型来拟合房价。
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 打印出预测的前5条房价数据
print("预测的前5条房价数据:")
print(model.predict(X_test)[:5])
在sklearn中使用各种模型时都用了一种统一的样式,基本上都是先用fit()进行训练,然后用predict()进行预测。
对于线性回归模型,其数学模型基本上类似:
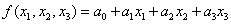
这里我们只提供了三个属性(x1, x2, x3)作为示例进行描述,在训练时本质上就是不停地调整a0, a1, a2, a3的参数,使其最终预测的f值与实际的y值之间的差值最小化,这里的差值一般用差的平方和来表示。
对于我们前面的房价例子中,当模型进行了fit()之后,相当于构建了上述的线性方程,那这个方程中的系数是多少呢?也就是上面的a1,a2,a3等这些系数值是多少呢?我们有没有办法把它打印出来呢?
我们可以通过:
print(model.coef_)
打印出这个线性方程前的系数:
[ -6.87376243e-02 3.32843076e-02 4.06433614e-02 1.75803112e+00
-1.87184969e+01 3.85410965e+00 2.32212165e-02 -1.23775798e+00
3.03653042e-01 -1.08755181e-02 -1.01367357e+00 9.56725087e-03
-6.08759683e-01]
这里总共有13个系数值,为何有13个系数值呢?
因为我们在预测房价时认为影响房价总共有13个参数,并且我们在训练的数据集中就获得了这13个属性值,这样相应地就有13个自变量,13个自变量的系数值。
但我们知道,在线性方程中还有一个常量值,也称为截距,相当于某个房价的平均值或基准值的概念(当然这里的命名有点不那么标准,希望读者能够自己去体会),也就是此值代表的是当各个属性值都为0时所代表的房价值。
如何打印出这个常量值呢?
print(model.intercept_)
输出为:
35.6839415854
相当于当某房子的房龄为0,户型为0房时等这些条件下,房价为35万这样的理解方式。
这里sklearn用coef_和intercept_对系数和截距进行了命名,这两个名字的全称为:coefficient(系数)和intercept(截距)
其实通过系数值,我们还能获得如下信息:
. 此系数中如果是+号,表示是正相关,如果是-号表示是负相关;
. 如果系数值越大,则说明其对最终房价的影响度就越大,当然,这是在其变量值是同等度量的情况下。
经过上面参数预测出来的结果跟实际值之间到底差距多少呢?
这里可以通过score来进行表述,这个得分的实现方式在sklearn中分简单,例子如下:
print("得分:", model.score(X_test, y_test))
输出为:
得分: 0.630433028896
这里得分为0-1的值,可以简单认为是63分,看来当前房价的预测准确度不是很高,只有63分。
这里的打分计算公式类似均方差的概念,也就是预测值与实际值之差的平方和再开方,然后除以实际值与实际平均值之差的平方再开方之类的,具体计算公式是什么样的,可以在IDEA中查看相应score函数的说明文档就可以。
sklearn模型的属性与功能-【老鱼学sklearn】的更多相关文章
- sklearn保存模型-【老鱼学sklearn】
训练好了一个Model 以后总需要保存和再次预测, 所以保存和读取我们的sklearn model也是同样重要的一步. 比如,我们根据房源样本数据训练了一下房价模型,当用户输入自己的房子后,我们就需要 ...
- sklearn数据库-【老鱼学sklearn】
在做机器学习时需要有数据进行训练,幸好sklearn提供了很多已经标注好的数据集供我们进行训练. 本节就来看看sklearn提供了哪些可供训练的数据集. 这些数据位于datasets中,网址为:htt ...
- sklearn标准化-【老鱼学sklearn】
在前面的一篇博文中关于计算房价中我们也大致提到了标准化的概念,也就是比如对于影响房价的参数中有面积和户型,面积的取值范围可以很广,它可以从0-500平米,而户型一般也就1-5. 标准化就是要把这两种参 ...
- sklearn交叉验证-【老鱼学sklearn】
交叉验证(Cross validation),有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法.于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证. 一开始 ...
- sklearn交叉验证2-【老鱼学sklearn】
过拟合 过拟合相当于一个人只会读书,却不知如何利用知识进行变通. 相当于他把考试题目背得滚瓜烂熟,但一旦环境稍微有些变化,就死得很惨. 从图形上看,类似下图的最右图: 从数学公式上来看,这个曲线应该是 ...
- sklearn交叉验证3-【老鱼学sklearn】
在上一个博文中,我们用learning_curve函数来确定应该拥有多少的训练集能够达到效果,就像一个人进行学习时需要做多少题目就能拥有较好的考试成绩了. 本次我们来看下如何调整学习中的参数,类似一个 ...
- tensorflow卷积神经网络-【老鱼学tensorflow】
前面我们曾有篇文章中提到过关于用tensorflow训练手写2828像素点的数字的识别,在那篇文章中我们把手写数字图像直接碾压成了一个784列的数据进行识别,但实际上,这个图像是2828长宽结构的,我 ...
- 二分类问题续 - 【老鱼学tensorflow2】
前面我们针对电影评论编写了二分类问题的解决方案. 这里对前面的这个方案进行一些改进. 分批训练 model.fit(x_train, y_train, epochs=20, batch_size=51 ...
- 为何学习matplotlib-【老鱼学matplotlib】
这次老鱼开始学习matplotlib了. 在上个pandas最后一篇博文中,我们已经看到了用matplotlib进行绘图的功能,这次更加系统性地学习一下关于matplotlib的功能. matlab由 ...
随机推荐
- python之继承、抽象类、新式类和经典类
一.上节补充1.静态属性静态属性 : 类的属性,所有的对象共享这个变量 如果用对象名去修改类的静态属性:在对象的空间中又创建了一个属性,而不能修改类中属性的值 操作静态属性应该用类名来操作 例1:请你 ...
- Qt QWidget
原文: https://www.cnblogs.com/muyuhu/archive/2012/10/26/2741184.html QWidget 类代表一般的窗口,其他窗口类都是从 QWidget ...
- Nginx-Tomcat搭建负载均衡(转载)
一. 工具 nginx-1.8.0 apache-tomcat-6.0.33 二. 目标 实现高性能负载均衡的Tomcat集群: 三. 步骤 1.首先下载Nginx,要下载稳定版: 2 ...
- Hive 执行作业时报错 [ Diagnostics: File file:/ *** reduce.xml does not exist FileNotFoundException: File file:/ ]
2019-03-10 本篇文章旨在阐述本人在某一特定情况下遇到 Hive 执行 MapReduce 作业的问题的探索过程与解决方案.不对文章的完全.绝对正确性负责. 解决方案 Hive 的配置文件 ...
- Android的LinearLayout中orientation默认值为什么是HORIZONTAL
在一个偶然(闲着无聊)的过程中,突然非常好奇为什么LinearLayout在不指定排列方向为垂直(VERTICAL)时就得是水平方向(HORIZONTAL)排列的.产生这个疑问的时候脑子里蹦出来的第一 ...
- mpvue——componets中引入vant-weapp组件
前言 这个问题很奇葩,网上也有很多人,给了很多方法,但是我想说的是,那些方法我用了都没效果,我试了一些都没效果,因为我当时引入时报错说没有export default出来,但是一旦暴露出来就又出其他问 ...
- PKUWC2019爆0记
PKUWC2019爆0记 访问量该骗的还是要骗. 1.20 坐了一天的高铁到jz了,热的一批 1.21 上午开营仪式 下午day1 打开发现有个地主斗 然后开T1 出题人你™搞笑吧放一道sb都能切的题 ...
- web.xml:<url-pattern>
web.xml 中的 <url-pattern> 是 <servlet-mapping> 或 <filter-mapping> 下的子标签. url :http:/ ...
- Battery Historian 使用常用命令
一.重置电池数据收集数据 打开电池数据获取:adb shell dumpsys batterystats --enable full-wake-history 重置电池数据: adb shell du ...
- HTML词法和语法
1. 词 token 专业不是计算机的博主比较尴尬,一直以为token就是验证身份用的标识 token —— 表示 “最小有意义的单元” 以这个简单的p标签为例,我们分析哪些是token: <p ...